 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring LLM Code Generation Stability via Structural Entropy
Aug 19, 2025Assessing the stability of code generation from large language models (LLMs) is essential for judging their reliability in real-world development. We extend prior "structural-entropy concepts" to the program domain by pairing entropy with abstract syntax tree (AST) analysis. For any fixed prompt, we collect the multiset of depth-bounded subtrees of AST in each generated program and treat their relative frequencies as a probability distribution. We then measure stability in two complementary ways: (i) Jensen-Shannon divergence, a symmetric, bounded indicator of structural overlap, and (ii) a Structural Cross-Entropy ratio that highlights missing high-probability patterns. Both metrics admit structural-only and token-aware variants, enabling separate views on control-flow shape and identifier-level variability. Unlike pass@k, BLEU, or CodeBLEU, our metrics are reference-free, language-agnostic, and execution-independent. We benchmark several leading LLMs on standard code generation tasks, demonstrating that AST-driven structural entropy reveals nuances in model consistency and robustness. The method runs in O(n,d) time with no external tests, providing a lightweight addition to the code-generation evaluation toolkit.
CallNavi: A Study and Challenge on Function Calling Routing and Invocation in Large Language Models
Jan 09, 2025
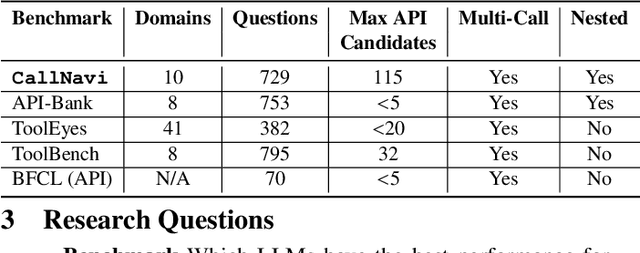


Interacting with a software system via a chatbot can be challenging, especially when the chatbot needs to generate API calls, in the right order and with the right parameters, to communicate with the system. API calling in chatbot systems poses significant challenges, particularly in complex, multi-step tasks requiring accurate API selection and execution. We contribute to this domain in three ways: first, by introducing a novel dataset designed to assess models on API function selection, parameter generation, and nested API calls; second, by benchmarking state-of-the-art language models across varying levels of complexity to evaluate their performance in API function generation and parameter accuracy; and third, by proposing an enhanced API routing method that combines general-purpose large language models for API selection with fine-tuned models for parameter generation and some prompt engineering approach. These approaches lead to substantial improvements in handling complex API tasks, offering practical advancements for real-world API-driven chatbot systems.
VisLingInstruct: Elevating Zero-Shot Learning in Multi-Modal Language Models with Autonomous Instruction Optimization
Feb 12, 2024This paper presents VisLingInstruct, a novel approach to advancing Multi-Modal Language Models (MMLMs) in zero-shot learning. Current MMLMs show impressive zero-shot abilities in multi-modal tasks, but their performance depends heavily on the quality of instructions. VisLingInstruct tackles this by autonomously evaluating and optimizing instructional texts through In-Context Learning, improving the synergy between visual perception and linguistic expression in MMLMs. Alongside this instructional advancement, we have also optimized the visual feature extraction modules in MMLMs, further augmenting their responsiveness to textual cues. Our comprehensive experiments on MMLMs, based on FlanT5 and Vicuna, show that VisLingInstruct significantly improves zero-shot performance in visual multi-modal tasks. Notably, it achieves a 13.1% and 9% increase in accuracy over the prior state-of-the-art on the TextVQA and HatefulMemes datasets.
CRNNet: Copy Recurrent Neural Network Structure Network
Dec 15, 2023

The target of Electronic Health Record (EHR) coding is to find the diagnostic codes according to the EHRs. In previous research, researchers have preferred to do multi-classification on the EHR coding task; most of them encode the EHR first and then process it to get the probability of each code based on the EHR representation. However, the question of complicating diseases is neglected among all these methods. In this paper, we propose a novel EHR coding framework, which is the first attempt at detecting complicating diseases, called Copy Recurrent Neural Network Structure Network (CRNNet). This method refers to the idea of adversarial learning; a Path Generator and a Path Discriminator are designed to more efficiently finish the task of EHR coding. We propose a copy module to detect complicating diseases; by the proposed copy module and the adversarial learning strategy, we identify complicating diseases efficiently. Extensive experiments show that our method achieves a 57.30\% ratio of complicating diseases in predictions, demonstrating the effectiveness of our proposed model. According to the ablation study, the proposed copy mechanism plays a crucial role in detecting complicating diseases.
Just-in-Time Security Patch Detection -- LLM At the Rescue for Data Augmentation
Dec 02, 2023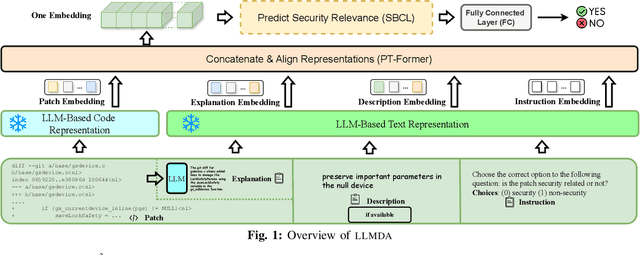
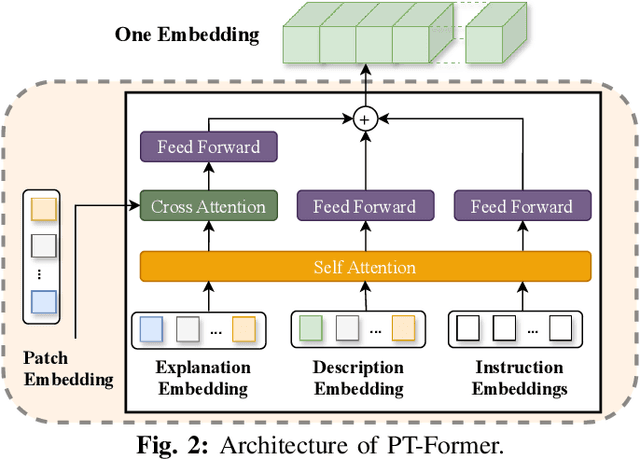
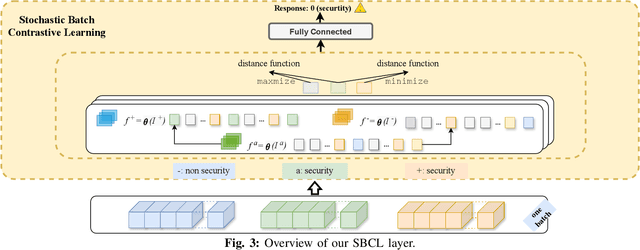
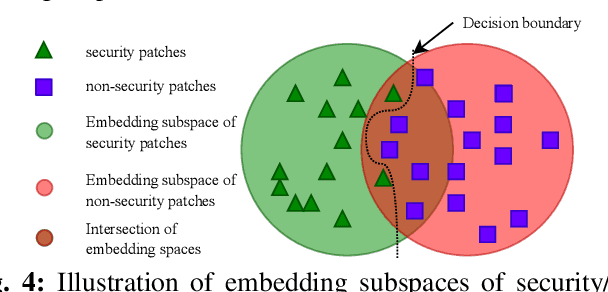
In the face of growing vulnerabilities found in open-source software, the need to identify {discreet} security patches has become paramount. The lack of consistency in how software providers handle maintenance often leads to the release of security patches without comprehensive advisories, leaving users vulnerable to unaddressed security risks. To address this pressing issue, we introduce a novel security patch detection system, LLMDA, which capitalizes on Large Language Models (LLMs) and code-text alignment methodologies for patch review, data enhancement, and feature combination. Within LLMDA, we initially utilize LLMs for examining patches and expanding data of PatchDB and SPI-DB, two security patch datasets from recent literature. We then use labeled instructions to direct our LLMDA, differentiating patches based on security relevance. Following this, we apply a PTFormer to merge patches with code, formulating hybrid attributes that encompass both the innate details and the interconnections between the patches and the code. This distinctive combination method allows our system to capture more insights from the combined context of patches and code, hence improving detection precision. Finally, we devise a probabilistic batch contrastive learning mechanism within batches to augment the capability of the our LLMDA in discerning security patches. The results reveal that LLMDA significantly surpasses the start of the art techniques in detecting security patches, underscoring its promise in fortifying software maintenance.
Copy Recurrent Neural Network Structure Network
May 22, 2023Electronic Health Record (EHR) coding involves automatically classifying EHRs into diagnostic codes. While most previous research treats this as a multi-label classification task, generating probabilities for each code and selecting those above a certain threshold as labels, these approaches often overlook the challenge of identifying complex diseases. In this study, our focus is on detecting complication diseases within EHRs. We propose a novel coarse-to-fine ICD path generation framework called the Copy Recurrent Neural Network Structure Network (CRNNet), which employs a Path Generator (PG) and a Path Discriminator (PD) for EHR coding. By using RNNs to generate sequential outputs and incorporating a copy module, we efficiently identify complication diseases. Our method achieves a 57.30\% ratio of complex diseases in predictions, outperforming state-of-the-art and previous approaches. Additionally, through an ablation study, we demonstrate that the copy mechanism plays a crucial role in detecting complex diseases.
Is ChatGPT the Ultimate Programming Assistant -- How far is it?
Apr 24, 2023



The recent progress in generative AI techniques has significantly influenced software engineering, as AI-driven methods tackle common developer challenges such as code synthesis from descriptions, program repair, and natural language summaries for existing programs. Large-scale language models (LLMs), like OpenAI's Codex, are increasingly adopted in AI-driven software engineering. ChatGPT, another LLM, has gained considerable attention for its potential as a bot for discussing source code, suggesting changes, providing descriptions, and generating code. To evaluate the practicality of LLMs as programming assistant bots, it is essential to examine their performance on unseen problems and various tasks. In our paper, we conduct an empirical analysis of ChatGPT's potential as a fully automated programming assistant, emphasizing code generation, program repair, and code summarization. Our study assesses ChatGPT's performance on common programming problems and compares it to state-of-the-art approaches using two benchmarks. Our research indicates that ChatGPT effectively handles typical programming challenges. However, we also discover the limitations in its attention span: comprehensive descriptions can restrict ChatGPT's focus and impede its ability to utilize its extensive knowledge for problem-solving. Surprisingly, we find that ChatGPT's summary explanations of incorrect code provide valuable insights into the developer's original intentions. This insight can be served as a foundation for future work addressing the oracle problem. Our study offers valuable perspectives on the development of LLMs for programming assistance, specifically by highlighting the significance of prompt engineering and enhancing our comprehension of ChatGPT's practical applications in software engineering.
GE-Blender: Graph-Based Knowledge Enhancement for Blender
Jan 30, 2023Although the great success of open-domain dialogue generation, unseen entities can have a large impact on the dialogue generation task. It leads to performance degradation of the model in the dialog generation. Previous researches used retrieved knowledge of seen entities as the auxiliary data to enhance the representation of the model. Nevertheless, logical explanation of unseen entities remains unexplored, such as possible co-occurrence or semantically similar words of them and their entity category. In this work, we propose an approach to address the challenge above. We construct a graph by extracting entity nodes in them, enhancing the representation of the context of the unseen entity with the entity's 1-hop surrounding nodes. Furthermore, We added the named entity tag prediction task to apply the problem that the unseen entity does not exist in the graph. We conduct our experiments on an open dataset Wizard of Wikipedia and the empirical results indicate that our approach outperforms the state-of-the-art approaches on Wizard of Wikipedia.
App Review Driven Collaborative Bug Finding
Jan 23, 2023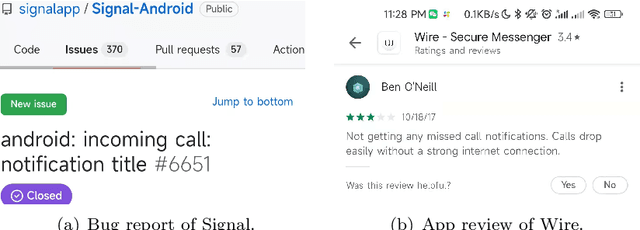
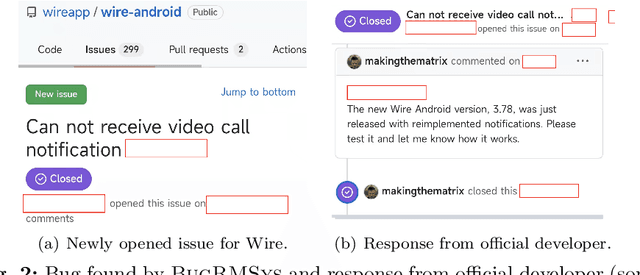


Software development teams generally welcome any effort to expose bugs in their code base. In this work, we build on the hypothesis that mobile apps from the same category (e.g., two web browser apps) may be affected by similar bugs in their evolution process. It is therefore possible to transfer the experience of one historical app to quickly find bugs in its new counterparts. This has been referred to as collaborative bug finding in the literature. Our novelty is that we guide the bug finding process by considering that existing bugs have been hinted within app reviews. Concretely, we design the BugRMSys approach to recommend bug reports for a target app by matching historical bug reports from apps in the same category with user app reviews of the target app. We experimentally show that this approach enables us to quickly expose and report dozens of bugs for targeted apps such as Brave (web browser app). BugRMSys's implementation relies on DistilBERT to produce natural language text embeddings. Our pipeline considers similarities between bug reports and app reviews to identify relevant bugs. We then focus on the app review as well as potential reproduction steps in the historical bug report (from a same-category app) to reproduce the bugs. Overall, after applying BugRMSys to six popular apps, we were able to identify, reproduce and report 20 new bugs: among these, 9 reports have been already triaged, 6 were confirmed, and 4 have been fixed by official development teams, respectively.
Moto: Enhancing Embedding with Multiple Joint Factors for Chinese Text Classification
Dec 09, 2022
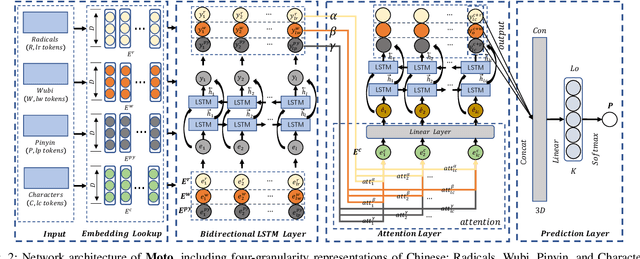


Recently, language representation techniques have achieved great performances in text classification. However, most existing representation models are specifically designed for English materials, which may fail in Chinese because of the huge difference between these two languages. Actually, few existing methods for Chinese text classification process texts at a single level. However, as a special kind of hieroglyphics, radicals of Chinese characters are good semantic carriers. In addition, Pinyin codes carry the semantic of tones, and Wubi reflects the stroke structure information, \textit{etc}. Unfortunately, previous researches neglected to find an effective way to distill the useful parts of these four factors and to fuse them. In our works, we propose a novel model called Moto: Enhancing Embedding with \textbf{M}ultiple J\textbf{o}int Fac\textbf{to}rs. Specifically, we design an attention mechanism to distill the useful parts by fusing the four-level information above more effectively. We conduct extensive experiments on four popular tasks. The empirical results show that our Moto achieves SOTA 0.8316 ($F_1$-score, 2.11\% improvement) on Chinese news titles, 96.38 (1.24\% improvement) on Fudan Corpus and 0.9633 (3.26\% improvement) on THUCNews.