 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoto: Enhancing Embedding with Multiple Joint Factors for Chinese Text Classification
Paper and Code

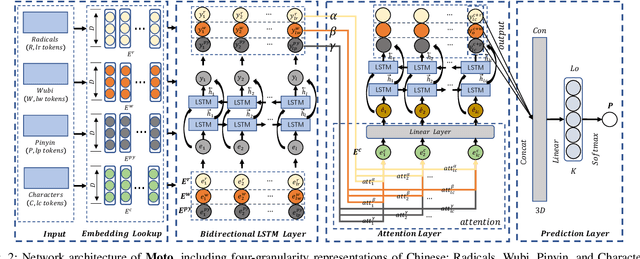


Recently, language representation techniques have achieved great performances in text classification. However, most existing representation models are specifically designed for English materials, which may fail in Chinese because of the huge difference between these two languages. Actually, few existing methods for Chinese text classification process texts at a single level. However, as a special kind of hieroglyphics, radicals of Chinese characters are good semantic carriers. In addition, Pinyin codes carry the semantic of tones, and Wubi reflects the stroke structure information, \textit{etc}. Unfortunately, previous researches neglected to find an effective way to distill the useful parts of these four factors and to fuse them. In our works, we propose a novel model called Moto: Enhancing Embedding with \textbf{M}ultiple J\textbf{o}int Fac\textbf{to}rs. Specifically, we design an attention mechanism to distill the useful parts by fusing the four-level information above more effectively. We conduct extensive experiments on four popular tasks. The empirical results show that our Moto achieves SOTA 0.8316 ($F_1$-score, 2.11\% improvement) on Chinese news titles, 96.38 (1.24\% improvement) on Fudan Corpus and 0.9633 (3.26\% improvement) on THUCNews.