 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring LLM Code Generation Stability via Structural Entropy
Aug 19, 2025Assessing the stability of code generation from large language models (LLMs) is essential for judging their reliability in real-world development. We extend prior "structural-entropy concepts" to the program domain by pairing entropy with abstract syntax tree (AST) analysis. For any fixed prompt, we collect the multiset of depth-bounded subtrees of AST in each generated program and treat their relative frequencies as a probability distribution. We then measure stability in two complementary ways: (i) Jensen-Shannon divergence, a symmetric, bounded indicator of structural overlap, and (ii) a Structural Cross-Entropy ratio that highlights missing high-probability patterns. Both metrics admit structural-only and token-aware variants, enabling separate views on control-flow shape and identifier-level variability. Unlike pass@k, BLEU, or CodeBLEU, our metrics are reference-free, language-agnostic, and execution-independent. We benchmark several leading LLMs on standard code generation tasks, demonstrating that AST-driven structural entropy reveals nuances in model consistency and robustness. The method runs in O(n,d) time with no external tests, providing a lightweight addition to the code-generation evaluation toolkit.
DetectBERT: Towards Full App-Level Representation Learning to Detect Android Malware
Aug 29, 2024
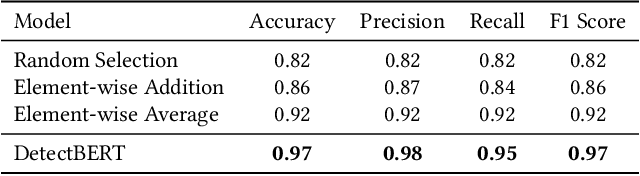
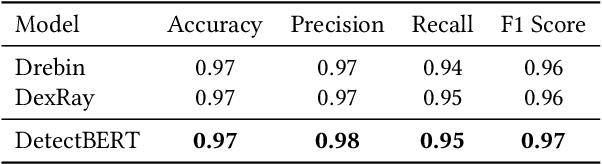
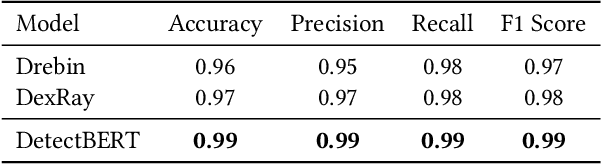
Recent advancements in ML and DL have significantly improved Android malware detection, yet many methodologies still rely on basic static analysis, bytecode, or function call graphs that often fail to capture complex malicious behaviors. DexBERT, a pre-trained BERT-like model tailored for Android representation learning, enriches class-level representations by analyzing Smali code extracted from APKs. However, its functionality is constrained by its inability to process multiple Smali classes simultaneously. This paper introduces DetectBERT, which integrates correlated Multiple Instance Learning (c-MIL) with DexBERT to handle the high dimensionality and variability of Android malware, enabling effective app-level detection. By treating class-level features as instances within MIL bags, DetectBERT aggregates these into a comprehensive app-level representation. Our evaluation demonstrates that DetectBERT not only surpasses existing state-of-the-art detection methods but also adapts to evolving malware threats. Moreover, the versatility of the DetectBERT framework holds promising potential for broader applications in app-level analysis and other software engineering tasks, offering new avenues for research and development.
LaFiCMIL: Rethinking Large File Classification from the Perspective of Correlated Multiple Instance Learning
Aug 15, 2023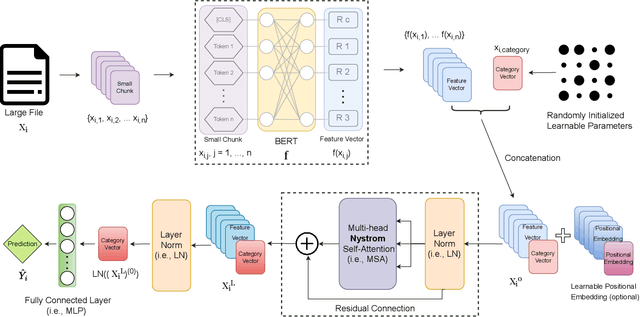
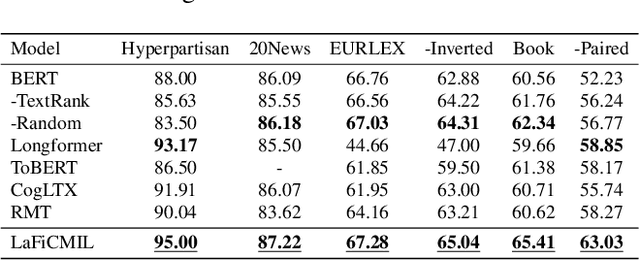
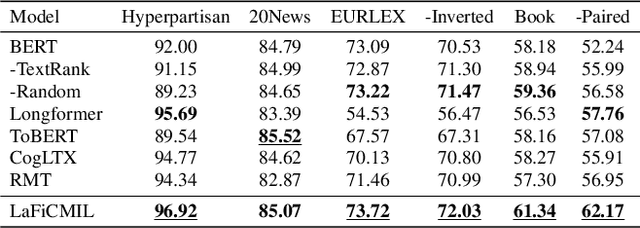
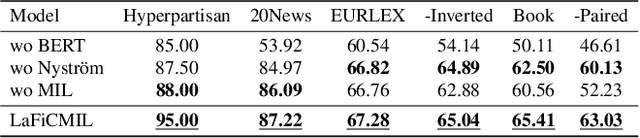
Transformer-based models, such as BERT, have revolutionized various language tasks, but still struggle with large file classification due to their input limit (e.g., 512 tokens). Despite several attempts to alleviate this limitation, no method consistently excels across all benchmark datasets, primarily because they can only extract partial essential information from the input file. Additionally, they fail to adapt to the varied properties of different types of large files. In this work, we tackle this problem from the perspective of correlated multiple instance learning. The proposed approach, LaFiCMIL, serves as a versatile framework applicable to various large file classification tasks covering binary, multi-class, and multi-label classification tasks, spanning various domains including Natural Language Processing, Programming Language Processing, and Android Analysis. To evaluate its effectiveness, we employ eight benchmark datasets pertaining to Long Document Classification, Code Defect Detection, and Android Malware Detection. Leveraging BERT-family models as feature extractors, our experimental results demonstrate that LaFiCMIL achieves new state-of-the-art performance across all benchmark datasets. This is largely attributable to its capability of scaling BERT up to nearly 20K tokens, running on a single Tesla V-100 GPU with 32G of memory.
A Pre-Trained BERT Model for Android Applications
Dec 12, 2022



The automation of an increasingly large number of software engineering tasks is becoming possible thanks to Machine Learning (ML). One foundational building block in the application of ML to software artifacts is the representation of these artifacts (e.g., source code or executable code) into a form that is suitable for learning. Many studies have leveraged representation learning, delegating to ML itself the job of automatically devising suitable representations. Yet, in the context of Android problems, existing models are either limited to coarse-grained whole-app level (e.g., apk2vec) or conducted for one specific downstream task (e.g., smali2vec). Our work is part of a new line of research that investigates effective, task-agnostic, and fine-grained universal representations of bytecode to mitigate both of these two limitations. Such representations aim to capture information relevant to various low-level downstream tasks (e.g., at the class-level). We are inspired by the field of Natural Language Processing, where the problem of universal representation was addressed by building Universal Language Models, such as BERT, whose goal is to capture abstract semantic information about sentences, in a way that is reusable for a variety of tasks. We propose DexBERT, a BERT-like Language Model dedicated to representing chunks of DEX bytecode, the main binary format used in Android applications. We empirically assess whether DexBERT is able to model the DEX language and evaluate the suitability of our model in two distinct class-level software engineering tasks: Malicious Code Localization and Defect Prediction. We also experiment with strategies to deal with the problem of catering to apps having vastly different sizes, and we demonstrate one example of using our technique to investigate what information is relevant to a given task.
CKG: Dynamic Representation Based on Context and Knowledge Graph
Dec 09, 2022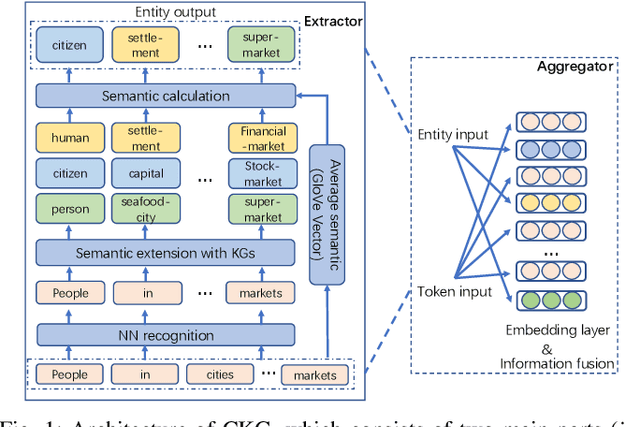



Recently, neural language representation models pre-trained on large corpus can capture rich co-occurrence information and be fine-tuned in downstream tasks to improve the performance. As a result, they have achieved state-of-the-art results in a large range of language tasks. However, there exists other valuable semantic information such as similar, opposite, or other possible meanings in external knowledge graphs (KGs). We argue that entities in KGs could be used to enhance the correct semantic meaning of language sentences. In this paper, we propose a new method CKG: Dynamic Representation Based on \textbf{C}ontext and \textbf{K}nowledge \textbf{G}raph. On the one side, CKG can extract rich semantic information of large corpus. On the other side, it can make full use of inside information such as co-occurrence in large corpus and outside information such as similar entities in KGs. We conduct extensive experiments on a wide range of tasks, including QQP, MRPC, SST-5, SQuAD, CoNLL 2003, and SNLI. The experiment results show that CKG achieves SOTA 89.2 on SQuAD compared with SAN (84.4), ELMo (85.8), and BERT$_{Base}$ (88.5).
Moto: Enhancing Embedding with Multiple Joint Factors for Chinese Text Classification
Dec 09, 2022
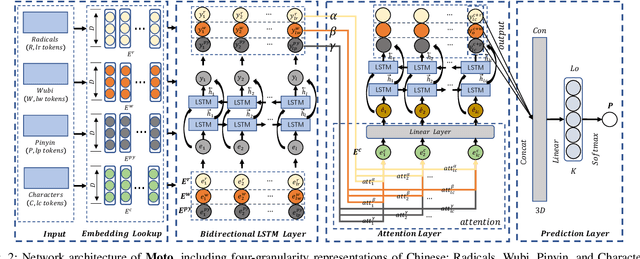


Recently, language representation techniques have achieved great performances in text classification. However, most existing representation models are specifically designed for English materials, which may fail in Chinese because of the huge difference between these two languages. Actually, few existing methods for Chinese text classification process texts at a single level. However, as a special kind of hieroglyphics, radicals of Chinese characters are good semantic carriers. In addition, Pinyin codes carry the semantic of tones, and Wubi reflects the stroke structure information, \textit{etc}. Unfortunately, previous researches neglected to find an effective way to distill the useful parts of these four factors and to fuse them. In our works, we propose a novel model called Moto: Enhancing Embedding with \textbf{M}ultiple J\textbf{o}int Fac\textbf{to}rs. Specifically, we design an attention mechanism to distill the useful parts by fusing the four-level information above more effectively. We conduct extensive experiments on four popular tasks. The empirical results show that our Moto achieves SOTA 0.8316 ($F_1$-score, 2.11\% improvement) on Chinese news titles, 96.38 (1.24\% improvement) on Fudan Corpus and 0.9633 (3.26\% improvement) on THUCNews.
AI-driven Mobile Apps: an Explorative Study
Dec 03, 2022Recent years have witnessed an astonishing explosion in the evolution of mobile applications powered by AI technologies. The rapid growth of AI frameworks enables the transition of AI technologies to mobile devices, significantly prompting the adoption of AI apps (i.e., apps that integrate AI into their functions) among smartphone devices. In this paper, we conduct the most extensive empirical study on 56,682 published AI apps from three perspectives: dataset characteristics, development issues, and user feedback and privacy. To this end, we build an automated AI app identification tool, AI Discriminator, that detects eligible AI apps from 7,259,232 mobile apps. First, we carry out a dataset analysis, where we explore the AndroZoo large repository to identify AI apps and their core characteristics. Subsequently, we pinpoint key issues in AI app development (e.g., model protection). Finally, we focus on user reviews and user privacy protection. Our paper provides several notable findings. Some essential ones involve revealing the issue of insufficient model protection by presenting the lack of model encryption, and demonstrating the risk of user privacy data being leaked. We published our large-scale AI app datasets to inspire more future research.
MetaTPTrans: A Meta Learning Approach for Multilingual Code Representation Learning
Jun 13, 2022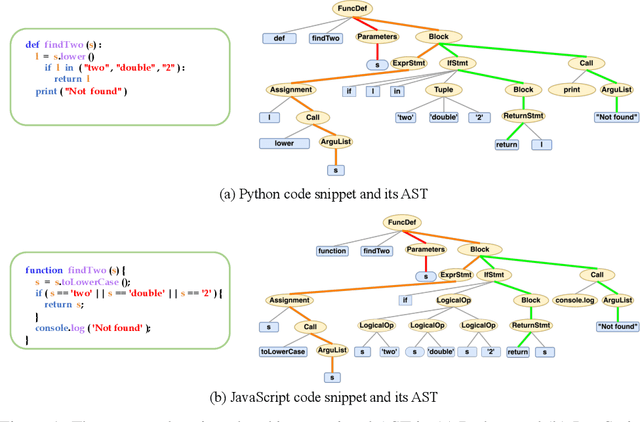
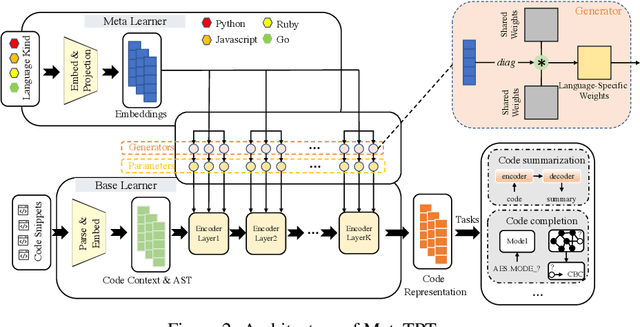
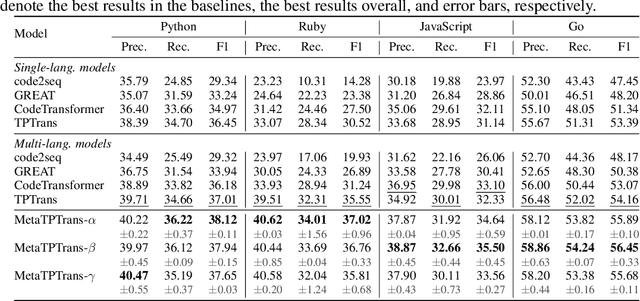
Representation learning of source code is essential for applying machine learning to software engineering tasks. Learning code representation across different programming languages has been shown to be more effective than learning from single-language datasets, since more training data from multi-language datasets improves the model's ability to extract language-agnostic information from source code. However, existing multi-language models overlook the language-specific information which is crucial for downstream tasks that is training on multi-language datasets, while only focusing on learning shared parameters among the different languages. To address this problem, we propose MetaTPTrans, a meta learning approach for multilingual code representation learning. MetaTPTrans generates different parameters for the feature extractor according to the specific programming language of the input source code snippet, enabling the model to learn both language-agnostics and language-specific information. Experimental results show that MetaTPTrans improves the F1 score of state-of-the-art approaches significantly by up to 2.40 percentage points for code summarization, a language-agnostic task; and the prediction accuracy of Top-1 (Top-5) by up to 7.32 (13.15) percentage points for code completion, a language-specific task.