 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCKG: Dynamic Representation Based on Context and Knowledge Graph
Dec 09, 2022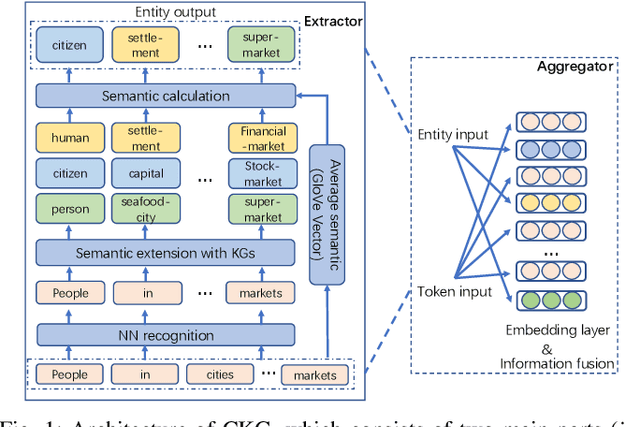



Recently, neural language representation models pre-trained on large corpus can capture rich co-occurrence information and be fine-tuned in downstream tasks to improve the performance. As a result, they have achieved state-of-the-art results in a large range of language tasks. However, there exists other valuable semantic information such as similar, opposite, or other possible meanings in external knowledge graphs (KGs). We argue that entities in KGs could be used to enhance the correct semantic meaning of language sentences. In this paper, we propose a new method CKG: Dynamic Representation Based on \textbf{C}ontext and \textbf{K}nowledge \textbf{G}raph. On the one side, CKG can extract rich semantic information of large corpus. On the other side, it can make full use of inside information such as co-occurrence in large corpus and outside information such as similar entities in KGs. We conduct extensive experiments on a wide range of tasks, including QQP, MRPC, SST-5, SQuAD, CoNLL 2003, and SNLI. The experiment results show that CKG achieves SOTA 89.2 on SQuAD compared with SAN (84.4), ELMo (85.8), and BERT$_{Base}$ (88.5).
Moto: Enhancing Embedding with Multiple Joint Factors for Chinese Text Classification
Dec 09, 2022
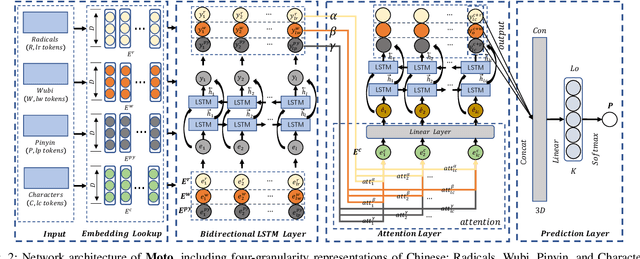


Recently, language representation techniques have achieved great performances in text classification. However, most existing representation models are specifically designed for English materials, which may fail in Chinese because of the huge difference between these two languages. Actually, few existing methods for Chinese text classification process texts at a single level. However, as a special kind of hieroglyphics, radicals of Chinese characters are good semantic carriers. In addition, Pinyin codes carry the semantic of tones, and Wubi reflects the stroke structure information, \textit{etc}. Unfortunately, previous researches neglected to find an effective way to distill the useful parts of these four factors and to fuse them. In our works, we propose a novel model called Moto: Enhancing Embedding with \textbf{M}ultiple J\textbf{o}int Fac\textbf{to}rs. Specifically, we design an attention mechanism to distill the useful parts by fusing the four-level information above more effectively. We conduct extensive experiments on four popular tasks. The empirical results show that our Moto achieves SOTA 0.8316 ($F_1$-score, 2.11\% improvement) on Chinese news titles, 96.38 (1.24\% improvement) on Fudan Corpus and 0.9633 (3.26\% improvement) on THUCNews.