 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExons-Detect: Identifying and Amplifying Exonic Tokens via Hidden-State Discrepancy for Robust AI-Generated Text Detection
Mar 26, 2026The rapid advancement of large language models has increasingly blurred the boundary between human-written and AI-generated text, raising societal risks such as misinformation dissemination, authorship ambiguity, and threats to intellectual property rights. These concerns highlight the urgent need for effective and reliable detection methods. While existing training-free approaches often achieve strong performance by aggregating token-level signals into a global score, they typically assume uniform token contributions, making them less robust under short sequences or localized token modifications. To address these limitations, we propose Exons-Detect, a training-free method for AI-generated text detection based on an exon-aware token reweighting perspective. Exons-Detect identifies and amplifies informative exonic tokens by measuring hidden-state discrepancy under a dual-model setting, and computes an interpretable translation score from the resulting importance-weighted token sequence. Empirical evaluations demonstrate that Exons-Detect achieves state-of-the-art detection performance and exhibits strong robustness to adversarial attacks and varying input lengths. In particular, it attains a 2.2\% relative improvement in average AUROC over the strongest prior baseline on DetectRL.
DualGuard: Dual-stream Large Language Model Watermarking Defense against Paraphrase and Spoofing Attack
Dec 18, 2025With the rapid development of cloud-based services, large language models (LLMs) have become increasingly accessible through various web platforms. However, this accessibility has also led to growing risks of model abuse. LLM watermarking has emerged as an effective approach to mitigate such misuse and protect intellectual property. Existing watermarking algorithms, however, primarily focus on defending against paraphrase attacks while overlooking piggyback spoofing attacks, which can inject harmful content, compromise watermark reliability, and undermine trust in attribution. To address this limitation, we propose DualGuard, the first watermarking algorithm capable of defending against both paraphrase and spoofing attacks. DualGuard employs the adaptive dual-stream watermarking mechanism, in which two complementary watermark signals are dynamically injected based on the semantic content. This design enables DualGuard not only to detect but also to trace spoofing attacks, thereby ensuring reliable and trustworthy watermark detection. Extensive experiments conducted across multiple datasets and language models demonstrate that DualGuard achieves excellent detectability, robustness, traceability, and text quality, effectively advancing the state of LLM watermarking for real-world applications.
PathMind: A Retrieve-Prioritize-Reason Framework for Knowledge Graph Reasoning with Large Language Models
Nov 18, 2025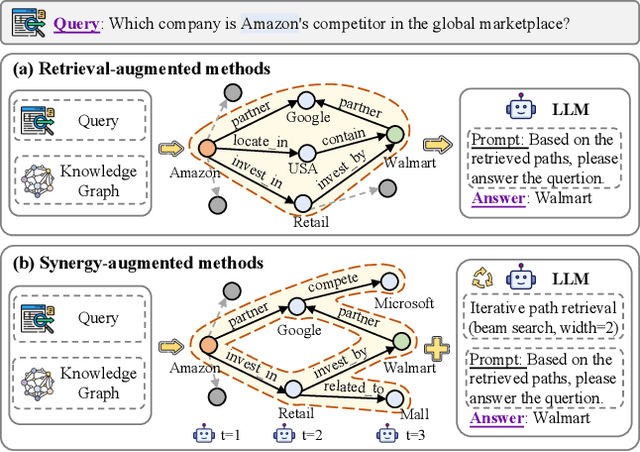
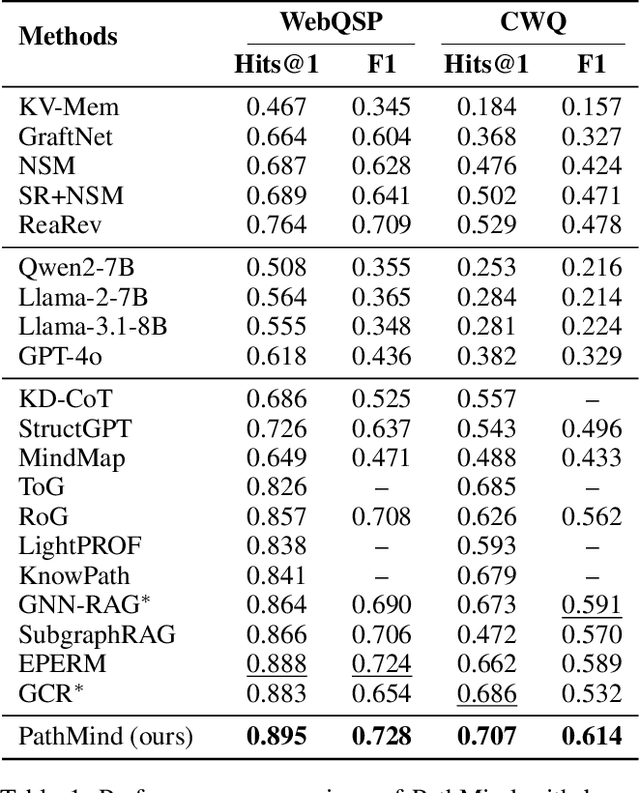
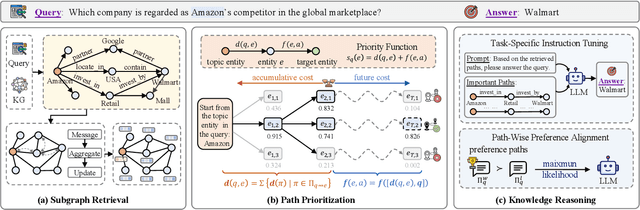
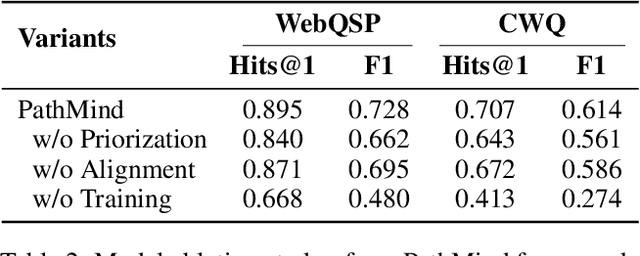
Knowledge graph reasoning (KGR) is the task of inferring new knowledge by performing logical deductions on knowledge graphs. Recently, large language models (LLMs) have demonstrated remarkable performance in complex reasoning tasks. Despite promising success, current LLM-based KGR methods still face two critical limitations. First, existing methods often extract reasoning paths indiscriminately, without assessing their different importance, which may introduce irrelevant noise that misleads LLMs. Second, while many methods leverage LLMs to dynamically explore potential reasoning paths, they require high retrieval demands and frequent LLM calls. To address these limitations, we propose PathMind, a novel framework designed to enhance faithful and interpretable reasoning by selectively guiding LLMs with important reasoning paths. Specifically, PathMind follows a "Retrieve-Prioritize-Reason" paradigm. First, it retrieves a query subgraph from KG through the retrieval module. Next, it introduces a path prioritization mechanism that identifies important reasoning paths using a semantic-aware path priority function, which simultaneously considers the accumulative cost and the estimated future cost for reaching the target. Finally, PathMind generates accurate and logically consistent responses via a dual-phase training strategy, including task-specific instruction tuning and path-wise preference alignment. Extensive experiments on benchmark datasets demonstrate that PathMind consistently outperforms competitive baselines, particularly on complex reasoning tasks with fewer input tokens, by identifying essential reasoning paths.
DNA-DetectLLM: Unveiling AI-Generated Text via a DNA-Inspired Mutation-Repair Paradigm
Sep 19, 2025The rapid advancement of large language models (LLMs) has blurred the line between AI-generated and human-written text. This progress brings societal risks such as misinformation, authorship ambiguity, and intellectual property concerns, highlighting the urgent need for reliable AI-generated text detection methods. However, recent advances in generative language modeling have resulted in significant overlap between the feature distributions of human-written and AI-generated text, blurring classification boundaries and making accurate detection increasingly challenging. To address the above challenges, we propose a DNA-inspired perspective, leveraging a repair-based process to directly and interpretably capture the intrinsic differences between human-written and AI-generated text. Building on this perspective, we introduce DNA-DetectLLM, a zero-shot detection method for distinguishing AI-generated and human-written text. The method constructs an ideal AI-generated sequence for each input, iteratively repairs non-optimal tokens, and quantifies the cumulative repair effort as an interpretable detection signal. Empirical evaluations demonstrate that our method achieves state-of-the-art detection performance and exhibits strong robustness against various adversarial attacks and input lengths. Specifically, DNA-DetectLLM achieves relative improvements of 5.55% in AUROC and 2.08% in F1 score across multiple public benchmark datasets.
MixBridge: Heterogeneous Image-to-Image Backdoor Attack through Mixture of Schrödinger Bridges
May 12, 2025This paper focuses on implanting multiple heterogeneous backdoor triggers in bridge-based diffusion models designed for complex and arbitrary input distributions. Existing backdoor formulations mainly address single-attack scenarios and are limited to Gaussian noise input models. To fill this gap, we propose MixBridge, a novel diffusion Schr\"odinger bridge (DSB) framework to cater to arbitrary input distributions (taking I2I tasks as special cases). Beyond this trait, we demonstrate that backdoor triggers can be injected into MixBridge by directly training with poisoned image pairs. This eliminates the need for the cumbersome modifications to stochastic differential equations required in previous studies, providing a flexible tool to study backdoor behavior for bridge models. However, a key question arises: can a single DSB model train multiple backdoor triggers? Unfortunately, our theory shows that when attempting this, the model ends up following the geometric mean of benign and backdoored distributions, leading to performance conflict across backdoor tasks. To overcome this, we propose a Divide-and-Merge strategy to mix different bridges, where models are independently pre-trained for each specific objective (Divide) and then integrated into a unified model (Merge). In addition, a Weight Reallocation Scheme (WRS) is also designed to enhance the stealthiness of MixBridge. Empirical studies across diverse generation tasks speak to the efficacy of MixBridge.
ABKD: Pursuing a Proper Allocation of the Probability Mass in Knowledge Distillation via $α$-$β$-Divergence
May 07, 2025Knowledge Distillation (KD) transfers knowledge from a large teacher model to a smaller student model by minimizing the divergence between their output distributions, typically using forward Kullback-Leibler divergence (FKLD) or reverse KLD (RKLD). It has become an effective training paradigm due to the broader supervision information provided by the teacher distribution compared to one-hot labels. We identify that the core challenge in KD lies in balancing two mode-concentration effects: the \textbf{\textit{Hardness-Concentration}} effect, which refers to focusing on modes with large errors, and the \textbf{\textit{Confidence-Concentration}} effect, which refers to focusing on modes with high student confidence. Through an analysis of how probabilities are reassigned during gradient updates, we observe that these two effects are entangled in FKLD and RKLD, but in extreme forms. Specifically, both are too weak in FKLD, causing the student to fail to concentrate on the target class. In contrast, both are too strong in RKLD, causing the student to overly emphasize the target class while ignoring the broader distributional information from the teacher. To address this imbalance, we propose ABKD, a generic framework with $\alpha$-$\beta$-divergence. Our theoretical results show that ABKD offers a smooth interpolation between FKLD and RKLD, achieving an effective trade-off between these effects. Extensive experiments on 17 language/vision datasets with 12 teacher-student settings confirm its efficacy. The code is available at https://github.com/ghwang-s/abkd.
HQCC: A Hybrid Quantum-Classical Classifier with Adaptive Structure
Apr 02, 2025Parameterized Quantum Circuits (PQCs) with fixed structures severely degrade the performance of Quantum Machine Learning (QML). To address this, a Hybrid Quantum-Classical Classifier (HQCC) is proposed. It opens a practical way to advance QML in the Noisy Intermediate-Scale Quantum (NISQ) era by adaptively optimizing the PQC through a Long Short-Term Memory (LSTM) driven dynamic circuit generator, utilizing a local quantum filter for scalable feature extraction, and exploiting architectural plasticity to balance the entanglement depth and noise robustness. We realize the HQCC on the TensorCircuit platform and run simulations on the MNIST and Fashion MNIST datasets, achieving up to 97.12\% accuracy on MNIST and outperforming several alternative methods.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
GIEBench: Towards Holistic Evaluation of Group Identity-based Empathy for Large Language Models
Jun 24, 2024
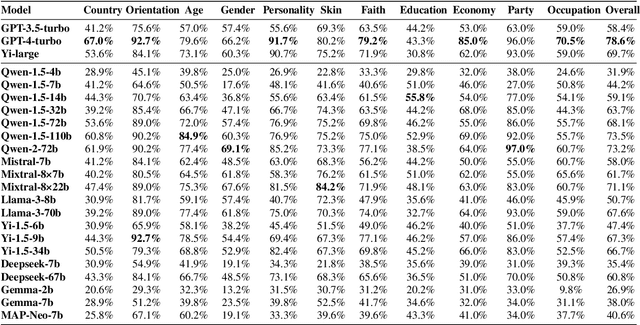

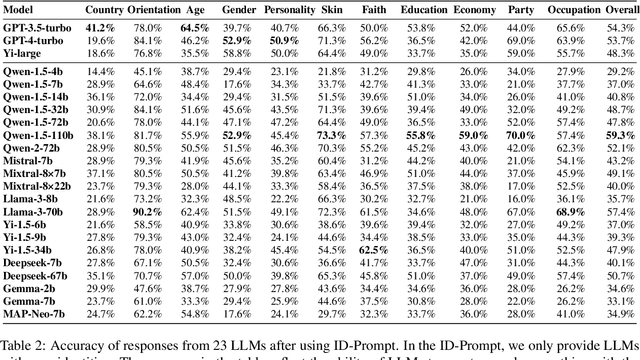
As large language models (LLMs) continue to develop and gain widespread application, the ability of LLMs to exhibit empathy towards diverse group identities and understand their perspectives is increasingly recognized as critical. Most existing benchmarks for empathy evaluation of LLMs focus primarily on universal human emotions, such as sadness and pain, often overlooking the context of individuals' group identities. To address this gap, we introduce GIEBench, a comprehensive benchmark that includes 11 identity dimensions, covering 97 group identities with a total of 999 single-choice questions related to specific group identities. GIEBench is designed to evaluate the empathy of LLMs when presented with specific group identities such as gender, age, occupation, and race, emphasizing their ability to respond from the standpoint of the identified group. This supports the ongoing development of empathetic LLM applications tailored to users with different identities. Our evaluation of 23 LLMs revealed that while these LLMs understand different identity standpoints, they fail to consistently exhibit equal empathy across these identities without explicit instructions to adopt those perspectives. This highlights the need for improved alignment of LLMs with diverse values to better accommodate the multifaceted nature of human identities. Our datasets are available at https://github.com/GIEBench/GIEBench.
Quantum Adjoint Convolutional Layers for Effective Data Representation
Apr 26, 2024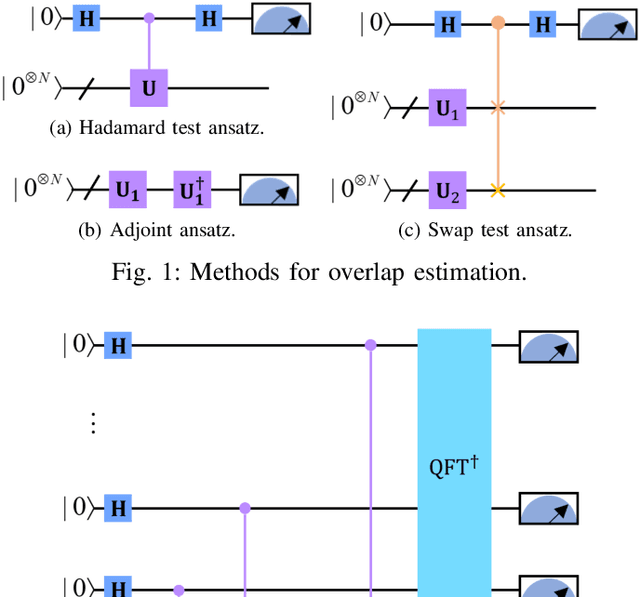
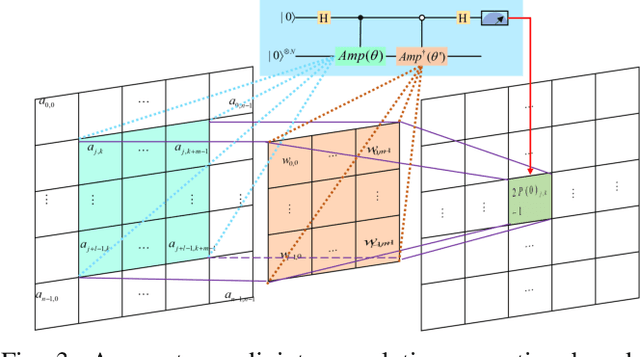
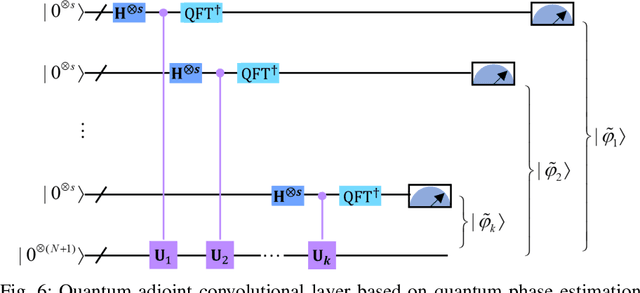
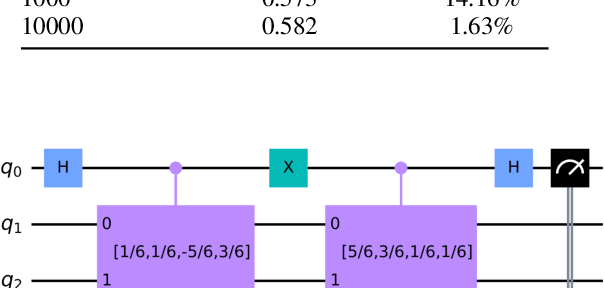
Quantum Convolutional Layer (QCL) is considered as one of the core of Quantum Convolutional Neural Networks (QCNNs) due to its efficient data feature extraction capability. However, the current principle of QCL is not as mathematically understandable as Classical Convolutional Layer (CCL) due to its black-box structure. Moreover, classical data mapping in many QCLs is inefficient. To this end, firstly, the Quantum Adjoint Convolution Operation (QACO) consisting of a quantum amplitude encoding and its inverse is theoretically shown to be equivalent to the quantum normalization of the convolution operation based on the Frobenius inner product while achieving an efficient characterization of the data. Subsequently, QACO is extended into a Quantum Adjoint Convolutional Layer (QACL) by Quantum Phase Estimation (QPE) to compute all Frobenius inner products in parallel. At last, comparative simulation experiments are carried out on PennyLane and TensorFlow platforms, mainly for the two cases of kernel fixed and unfixed in QACL. The results demonstrate that QACL with the insight of special quantum properties for the same images, provides higher training accuracy in MNIST and Fashion MNIST classification experiments, but sacrifices the learning performance to some extent. Predictably, our research lays the foundation for the development of efficient and interpretable quantum convolutional networks and also advances the field of quantum machine vision.