 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Emotion Regression with Multi-Objective Optimization and VAD-Aware Audio Modeling for the 10th ABAW EMI Track
Mar 14, 2026We participated in the 10th ABAW Challenge, focusing on the Emotional Mimicry Intensity (EMI) Estimation track on the Hume-Vidmimic2 dataset. This task aims to predict six continuous emotion dimensions: Admiration, Amusement, Determination, Empathic Pain, Excitement, and Joy. Through systematic multimodal exploration of pretrained high-level features, we found that, under our pretrained feature setting, direct feature concatenation outperformed the more complex fusion strategies we tested. This empirical finding motivated us to design a systematic approach built upon three core principles: (i) preserving modality-specific attributes through feature-level concatenation; (ii) improving training stability and metric alignment via multi-objective optimization; and (iii) enriching acoustic representations with a VAD-inspired latent prior. Our final framework integrates concatenation-based multimodal fusion, a shared six-dimensional regression head, multi-objective optimization with MSE, Pearson-correlation, and auxiliary branch supervision, EMA for parameter stabilization, and a VAD-inspired latent prior for the acoustic branch. On the official validation set, the proposed scheme achieved our best mean Pearson Correlation Coefficient of 0.478567.
Foundation Models for Music: A Survey
Aug 27, 2024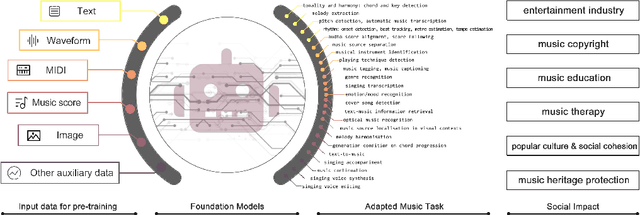

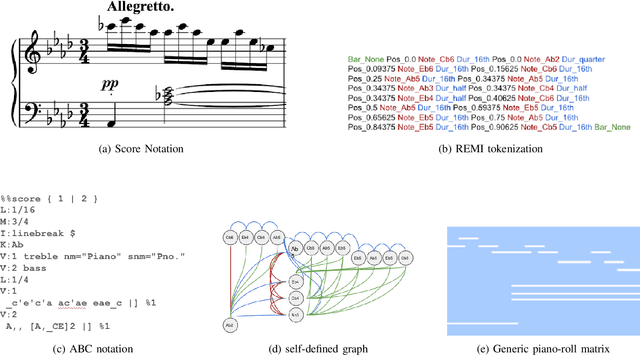
In recent years, foundation models (FMs) such as large language models (LLMs) and latent diffusion models (LDMs) have profoundly impacted diverse sectors, including music. This comprehensive review examines state-of-the-art (SOTA) pre-trained models and foundation models in music, spanning from representation learning, generative learning and multimodal learning. We first contextualise the significance of music in various industries and trace the evolution of AI in music. By delineating the modalities targeted by foundation models, we discover many of the music representations are underexplored in FM development. Then, emphasis is placed on the lack of versatility of previous methods on diverse music applications, along with the potential of FMs in music understanding, generation and medical application. By comprehensively exploring the details of the model pre-training paradigm, architectural choices, tokenisation, finetuning methodologies and controllability, we emphasise the important topics that should have been well explored, like instruction tuning and in-context learning, scaling law and emergent ability, as well as long-sequence modelling etc. A dedicated section presents insights into music agents, accompanied by a thorough analysis of datasets and evaluations essential for pre-training and downstream tasks. Finally, by underscoring the vital importance of ethical considerations, we advocate that following research on FM for music should focus more on such issues as interpretability, transparency, human responsibility, and copyright issues. The paper offers insights into future challenges and trends on FMs for music, aiming to shape the trajectory of human-AI collaboration in the music realm.
Towards Building an End-to-End Multilingual Automatic Lyrics Transcription Model
Jun 25, 2024

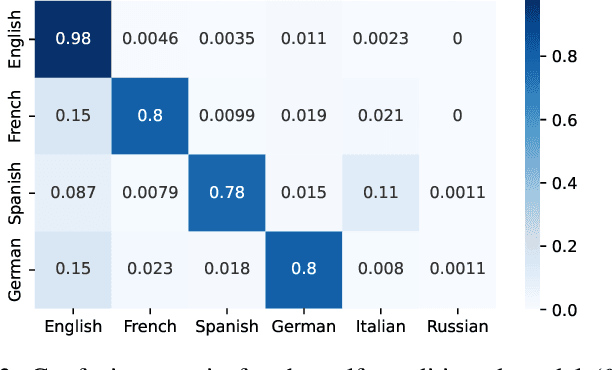

Multilingual automatic lyrics transcription (ALT) is a challenging task due to the limited availability of labelled data and the challenges introduced by singing, compared to multilingual automatic speech recognition. Although some multilingual singing datasets have been released recently, English continues to dominate these collections. Multilingual ALT remains underexplored due to the scale of data and annotation quality. In this paper, we aim to create a multilingual ALT system with available datasets. Inspired by architectures that have been proven effective for English ALT, we adapt these techniques to the multilingual scenario by expanding the target vocabulary set. We then evaluate the performance of the multilingual model in comparison to its monolingual counterparts. Additionally, we explore various conditioning methods to incorporate language information into the model. We apply analysis by language and combine it with the language classification performance. Our findings reveal that the multilingual model performs consistently better than the monolingual models trained on the language subsets. Furthermore, we demonstrate that incorporating language information significantly enhances performance.
MARBLE: Music Audio Representation Benchmark for Universal Evaluation
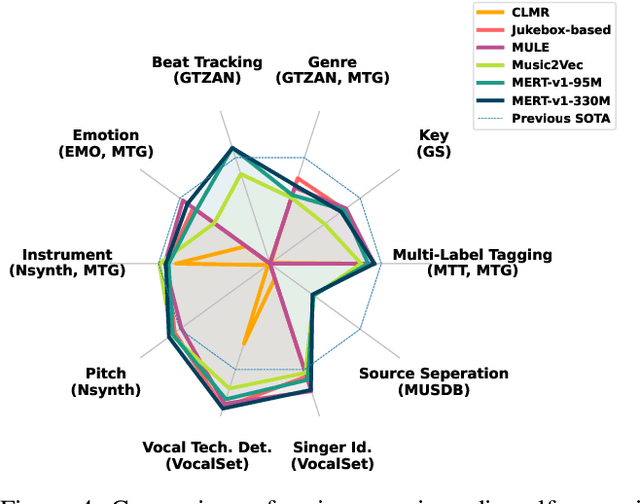
Jul 12, 2023In the era of extensive intersection between art and Artificial Intelligence (AI), such as image generation and fiction co-creation, AI for music remains relatively nascent, particularly in music understanding. This is evident in the limited work on deep music representations, the scarcity of large-scale datasets, and the absence of a universal and community-driven benchmark. To address this issue, we introduce the Music Audio Representation Benchmark for universaL Evaluation, termed MARBLE. It aims to provide a benchmark for various Music Information Retrieval (MIR) tasks by defining a comprehensive taxonomy with four hierarchy levels, including acoustic, performance, score, and high-level description. We then establish a unified protocol based on 14 tasks on 8 public-available datasets, providing a fair and standard assessment of representations of all open-sourced pre-trained models developed on music recordings as baselines. Besides, MARBLE offers an easy-to-use, extendable, and reproducible suite for the community, with a clear statement on copyright issues on datasets. Results suggest recently proposed large-scale pre-trained musical language models perform the best in most tasks, with room for further improvement. The leaderboard and toolkit repository are published at https://marble-bm.shef.ac.uk to promote future music AI research.
Improving Lyrics Alignment through Joint Pitch Detection
Feb 03, 2022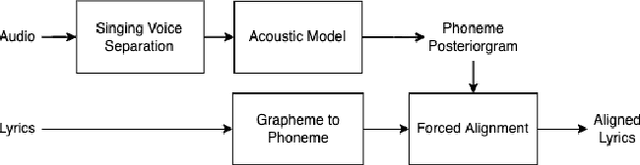
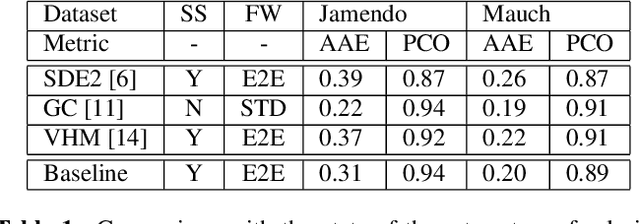
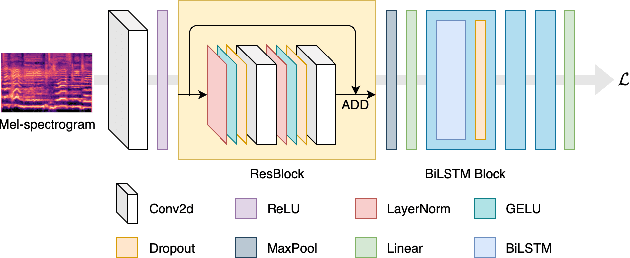
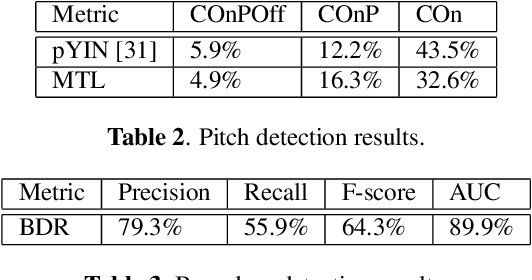
In recent years, the accuracy of automatic lyrics alignment methods has increased considerably. Yet, many current approaches employ frameworks designed for automatic speech recognition (ASR) and do not exploit properties specific to music. Pitch is one important musical attribute of singing voice but it is often ignored by current systems as the lyrics content is considered independent of the pitch. In practice, however, there is a temporal correlation between the two as note starts often correlate with phoneme starts. At the same time the pitch is usually annotated with high temporal accuracy in ground truth data while the timing of lyrics is often only available at the line (or word) level. In this paper, we propose a multi-task learning approach for lyrics alignment that incorporates pitch and thus can make use of a new source of highly accurate temporal information. Our results show that the accuracy of the alignment result is indeed improved by our approach. As an additional contribution, we show that integrating boundary detection in the forced-alignment algorithm reduces cross-line errors, which improves the accuracy even further.
Modeling the Compatibility of Stem Tracks to Generate Music Mashups
Mar 26, 2021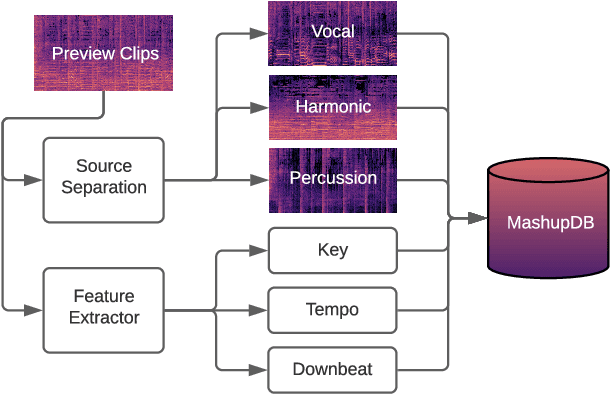
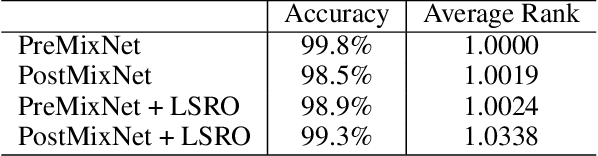
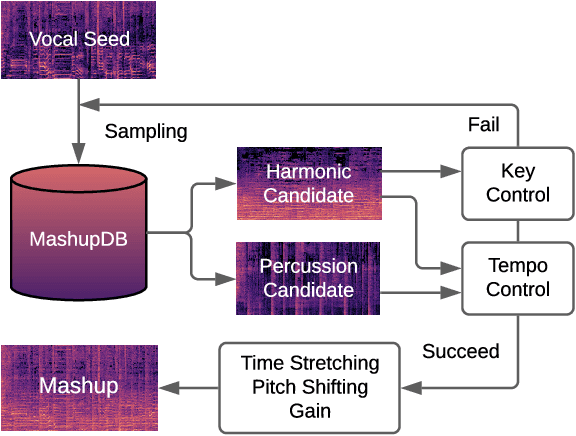
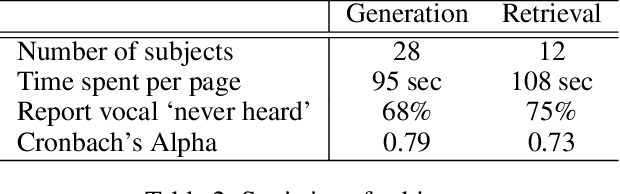
A music mashup combines audio elements from two or more songs to create a new work. To reduce the time and effort required to make them, researchers have developed algorithms that predict the compatibility of audio elements. Prior work has focused on mixing unaltered excerpts, but advances in source separation enable the creation of mashups from isolated stems (e.g., vocals, drums, bass, etc.). In this work, we take advantage of separated stems not just for creating mashups, but for training a model that predicts the mutual compatibility of groups of excerpts, using self-supervised and semi-supervised methods. Specifically, we first produce a random mashup creation pipeline that combines stem tracks obtained via source separation, with key and tempo automatically adjusted to match, since these are prerequisites for high-quality mashups. To train a model to predict compatibility, we use stem tracks obtained from the same song as positive examples, and random combinations of stems with key and/or tempo unadjusted as negative examples. To improve the model and use more data, we also train on "average" examples: random combinations with matching key and tempo, where we treat them as unlabeled data as their true compatibility is unknown. To determine whether the combined signal or the set of stem signals is more indicative of the quality of the result, we experiment on two model architectures and train them using semi-supervised learning technique. Finally, we conduct objective and subjective evaluations of the system, comparing them to a standard rule-based system.
Score-informed Networks for Music Performance Assessment
Aug 01, 2020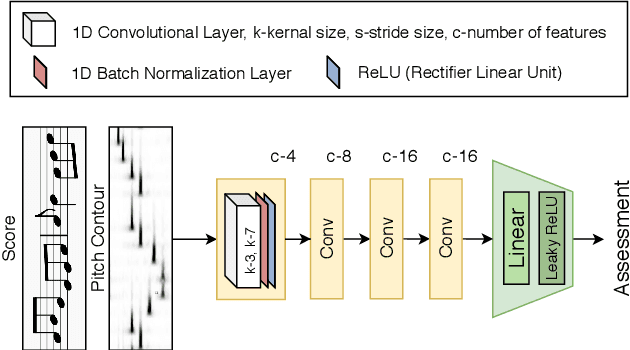
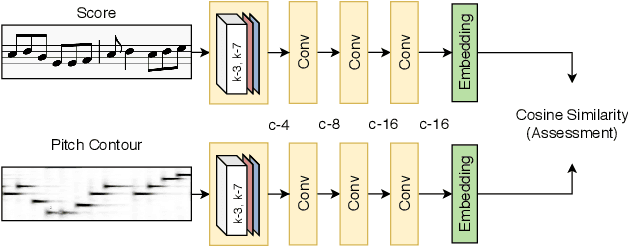
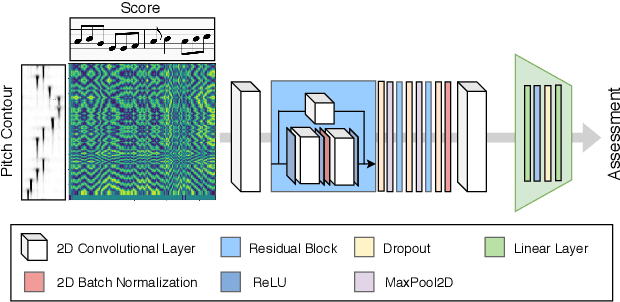
The assessment of music performances in most cases takes into account the underlying musical score being performed. While there have been several automatic approaches for objective music performance assessment (MPA) based on extracted features from both the performance audio and the score, deep neural network-based methods incorporating score information into MPA models have not yet been investigated. In this paper, we introduce three different models capable of score-informed performance assessment. These are (i) a convolutional neural network that utilizes a simple time-series input comprising of aligned pitch contours and score, (ii) a joint embedding model which learns a joint latent space for pitch contours and scores, and (iii) a distance matrix-based convolutional neural network which utilizes patterns in the distance matrix between pitch contours and musical score to predict assessment ratings. Our results provide insights into the suitability of different architectures and input representations and demonstrate the benefits of score-informed models as compared to score-independent models.