 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Requesting in Decentralized Edge Networks via Non-Stationary Bandits
Jan 13, 2026We study a decentralized collaborative requesting problem that aims to optimize the information freshness of time-sensitive clients in edge networks consisting of multiple clients, access nodes (ANs), and servers. Clients request content through ANs acting as gateways, without observing AN states or the actions of other clients. We define the reward as the age of information reduction resulting from a client's selection of an AN, and formulate the problem as a non-stationary multi-armed bandit. In this decentralized and partially observable setting, the resulting reward process is history-dependent and coupled across clients, and exhibits both abrupt and gradual changes in expected rewards, rendering classical bandit-based approaches ineffective. To address these challenges, we propose the AGING BANDIT WITH ADAPTIVE RESET algorithm, which combines adaptive windowing with periodic monitoring to track evolving reward distributions. We establish theoretical performance guarantees showing that the proposed algorithm achieves near-optimal performance, and we validate the theoretical results through simulations.
Self-Creating Random Walks for Decentralized Learning under Pac-Man Attacks
Jan 12, 2026Random walk (RW)-based algorithms have long been popular in distributed systems due to low overheads and scalability, with recent growing applications in decentralized learning. However, their reliance on local interactions makes them inherently vulnerable to malicious behavior. In this work, we investigate an adversarial threat that we term the ``Pac-Man'' attack, in which a malicious node probabilistically terminates any RW that visits it. This stealthy behavior gradually eliminates active RWs from the network, effectively halting the learning process without triggering failure alarms. To counter this threat, we propose the CREATE-IF-LATE (CIL) algorithm, which is a fully decentralized, resilient mechanism that enables self-creating RWs and prevents RW extinction in the presence of Pac-Man. Our theoretical analysis shows that the CIL algorithm guarantees several desirable properties, such as (i) non-extinction of the RW population, (ii) almost sure boundedness of the RW population, and (iii) convergence of RW-based stochastic gradient descent even in the presence of Pac-Man with a quantifiable deviation from the true optimum. Moreover, the learning process experiences at most a linear time delay due to Pac-Man interruptions and RW regeneration. Our extensive empirical results on both synthetic and public benchmark datasets validate our theoretical findings.
A Unified Framework for Inference with General Missingness Patterns and Machine Learning Imputation
Aug 21, 2025

Pre-trained machine learning (ML) predictions have been increasingly used to complement incomplete data to enable downstream scientific inquiries, but their naive integration risks biased inferences. Recently, multiple methods have been developed to provide valid inference with ML imputations regardless of prediction quality and to enhance efficiency relative to complete-case analyses. However, existing approaches are often limited to missing outcomes under a missing-completely-at-random (MCAR) assumption, failing to handle general missingness patterns under the more realistic missing-at-random (MAR) assumption. This paper develops a novel method which delivers valid statistical inference framework for general Z-estimation problems using ML imputations under the MAR assumption and for general missingness patterns. The core technical idea is to stratify observations by distinct missingness patterns and construct an estimator by appropriately weighting and aggregating pattern-specific information through a masking-and-imputation procedure on the complete cases. We provide theoretical guarantees of asymptotic normality of the proposed estimator and efficiency dominance over weighted complete-case analyses. Practically, the method affords simple implementations by leveraging existing weighted complete-case analysis software. Extensive simulations are carried out to validate theoretical results. The paper concludes with a brief discussion on practical implications, limitations, and potential future directions.
Generating Synthetic Electronic Health Record (EHR) Data: A Review with Benchmarking
Nov 06, 2024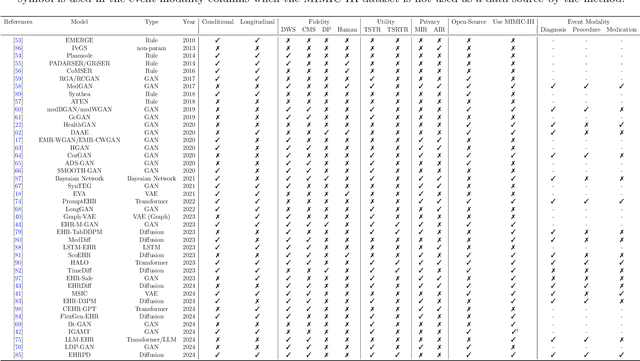
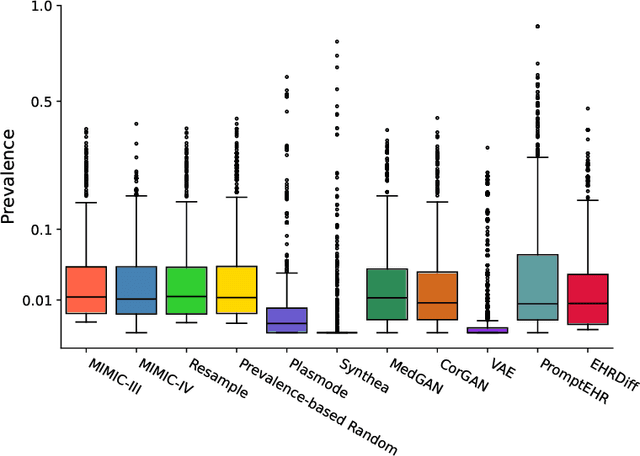
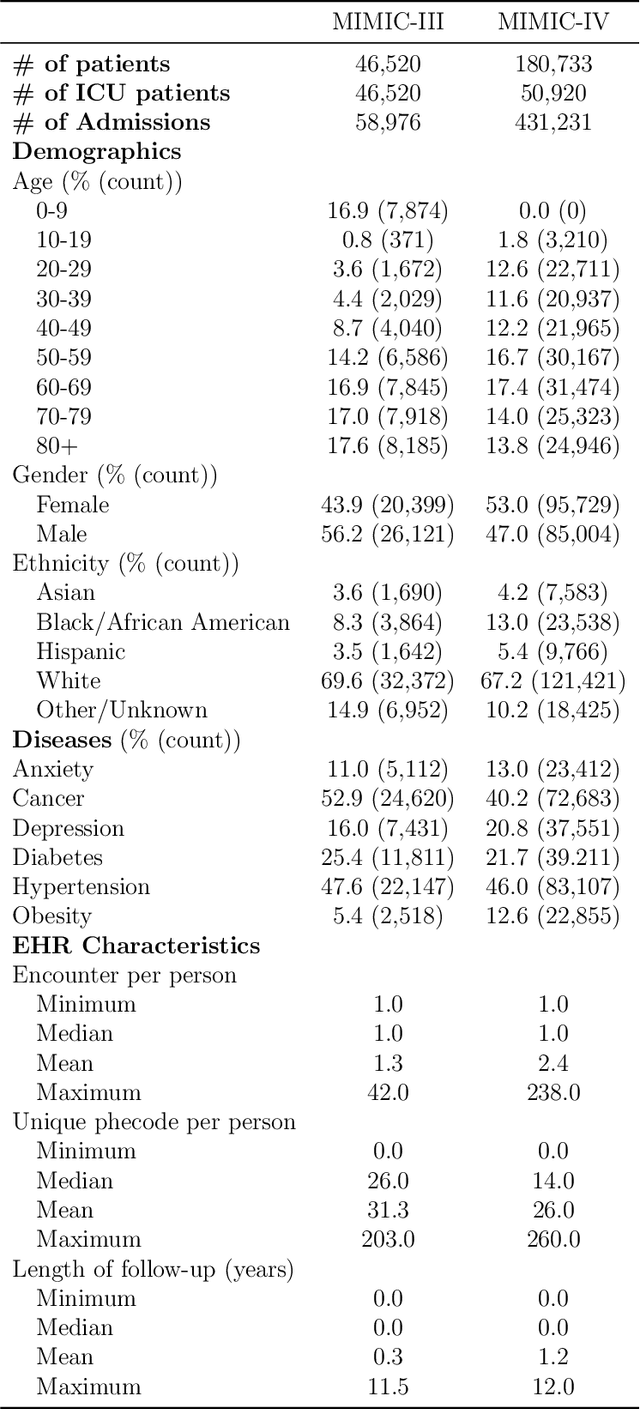
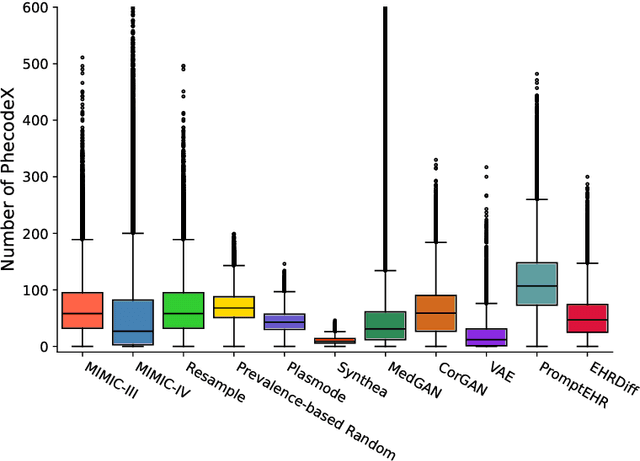
We conduct a scoping review of existing approaches for synthetic EHR data generation, and benchmark major methods with proposed open-source software to offer recommendations for practitioners. We search three academic databases for our scoping review. Methods are benchmarked on open-source EHR datasets, MIMIC-III/IV. Seven existing methods covering major categories and two baseline methods are implemented and compared. Evaluation metrics concern data fidelity, downstream utility, privacy protection, and computational cost. 42 studies are identified and classified into five categories. Seven open-source methods covering all categories are selected, trained on MIMIC-III, and evaluated on MIMIC-III or MIMIC-IV for transportability considerations. Among them, GAN-based methods demonstrate competitive performance in fidelity and utility on MIMIC-III; rule-based methods excel in privacy protection. Similar findings are observed on MIMIC-IV, except that GAN-based methods further outperform the baseline methods in preserving fidelity. A Python package, ``SynthEHRella'', is provided to integrate various choices of approaches and evaluation metrics, enabling more streamlined exploration and evaluation of multiple methods. We found that method choice is governed by the relative importance of the evaluation metrics in downstream use cases. We provide a decision tree to guide the choice among the benchmarked methods. Based on the decision tree, GAN-based methods excel when distributional shifts exist between the training and testing populations. Otherwise, CorGAN and MedGAN are most suitable for association modeling and predictive modeling, respectively. Future research should prioritize enhancing fidelity of the synthetic data while controlling privacy exposure, and comprehensive benchmarking of longitudinal or conditional generation methods.
Timely Requesting for Time-Critical Content Users in Decentralized F-RANs
Jul 03, 2024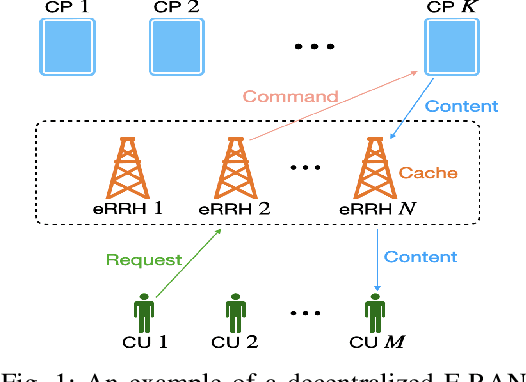
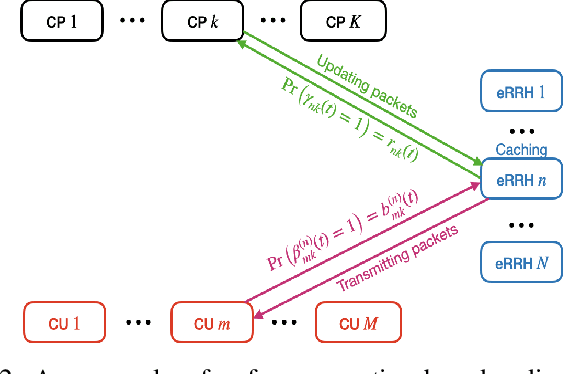
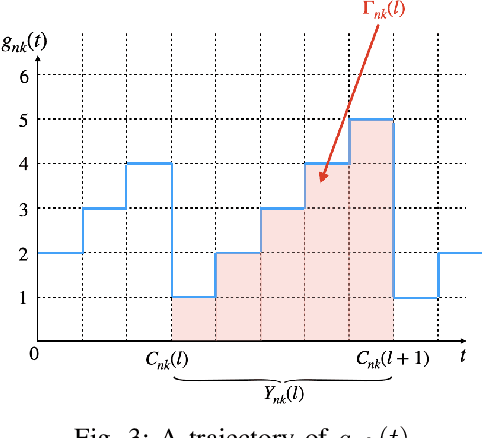
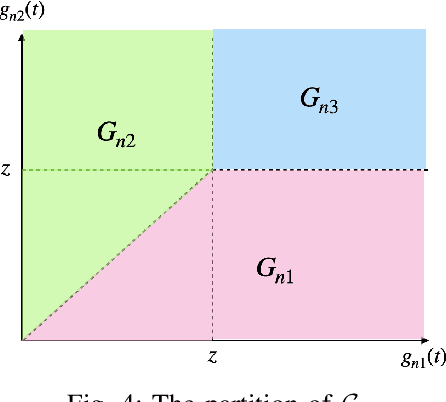
With the rising demand for high-rate and timely communications, fog radio access networks (F-RANs) offer a promising solution. This work investigates age of information (AoI) performance in F-RANs, consisting of multiple content users (CUs), enhanced remote radio heads (eRRHs), and content providers (CPs). Time-critical CUs need rapid content updates from CPs but cannot communicate directly with them; instead, eRRHs act as intermediaries. CUs decide whether to request content from a CP and which eRRH to send the request to, while eRRHs decide whether to command CPs to update content or use cached content. We study two general classes of policies: (i) oblivious policies, where decision-making is independent of historical information, and (ii) non-oblivious policies, where decisions are influenced by historical information. First, we obtain closed-form expressions for the average AoI of eRRHs under both policy types. Due to the complexity of calculating closed-form expressions for CUs, we then derive general upper bounds for their average AoI. Next, we identify optimal policies for both types. Under both optimal policies, each CU requests content from each CP at an equal rate, consolidating all requests to a single eRRH when demand is low or resources are limited, and distributing requests evenly among eRRHs when demand is high and resources are ample. eRRHs command content from each CP at an equal rate under an optimal oblivious policy, while prioritize the CP with the highest age under an optimal non-oblivious policy. Our numerical results validate these theoretical findings.
Decentralized Learning Strategies for Estimation Error Minimization with Graph Neural Networks
Apr 04, 2024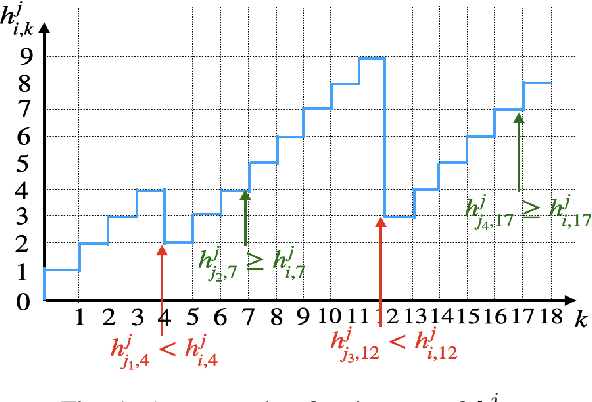
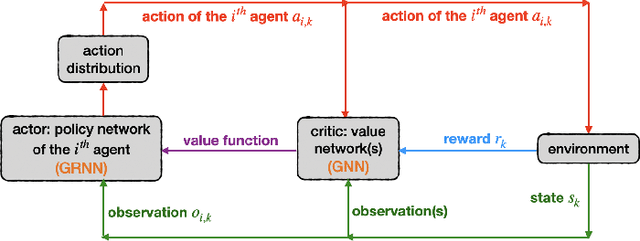
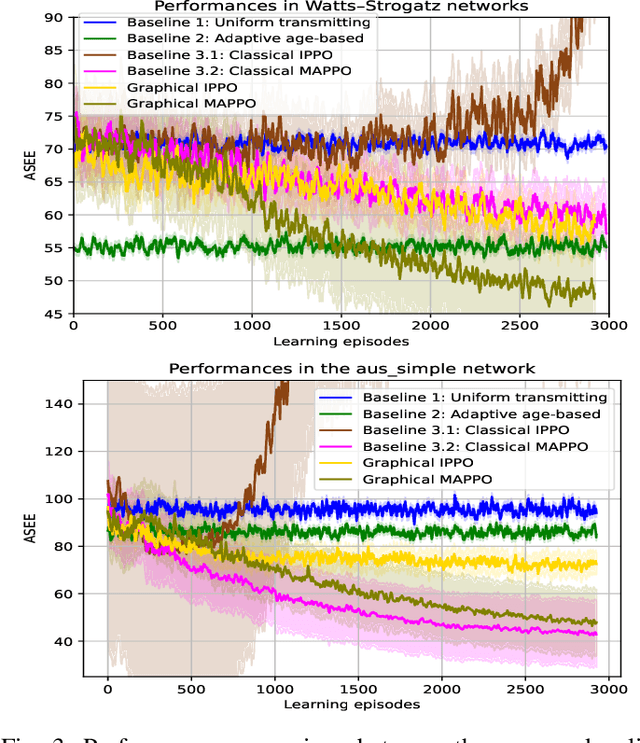
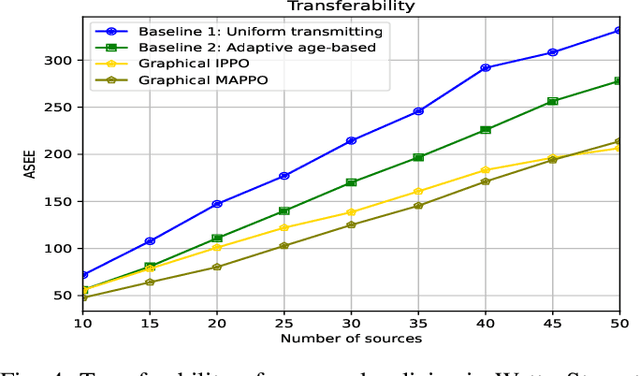
We address the challenge of sampling and remote estimation for autoregressive Markovian processes in a multi-hop wireless network with statistically-identical agents. Agents cache the most recent samples from others and communicate over wireless collision channels governed by an underlying graph topology. Our goal is to minimize time-average estimation error and/or age of information with decentralized scalable sampling and transmission policies, considering both oblivious (where decision-making is independent of the physical processes) and non-oblivious policies (where decision-making depends on physical processes). We prove that in oblivious policies, minimizing estimation error is equivalent to minimizing the age of information. The complexity of the problem, especially the multi-dimensional action spaces and arbitrary network topologies, makes theoretical methods for finding optimal transmission policies intractable. We optimize the policies using a graphical multi-agent reinforcement learning framework, where each agent employs a permutation-equivariant graph neural network architecture. Theoretically, we prove that our proposed framework exhibits desirable transferability properties, allowing transmission policies trained on small- or moderate-size networks to be executed effectively on large-scale topologies. Numerical experiments demonstrate that (i) Our proposed framework outperforms state-of-the-art baselines; (ii) The trained policies are transferable to larger networks, and their performance gains increase with the number of agents; (iii) The training procedure withstands non-stationarity even if we utilize independent learning techniques; and, (iv) Recurrence is pivotal in both independent learning and centralized training and decentralized execution, and improves the resilience to non-stationarity in independent learning.
MARBLE: Music Audio Representation Benchmark for Universal Evaluation
Jul 12, 2023In the era of extensive intersection between art and Artificial Intelligence (AI), such as image generation and fiction co-creation, AI for music remains relatively nascent, particularly in music understanding. This is evident in the limited work on deep music representations, the scarcity of large-scale datasets, and the absence of a universal and community-driven benchmark. To address this issue, we introduce the Music Audio Representation Benchmark for universaL Evaluation, termed MARBLE. It aims to provide a benchmark for various Music Information Retrieval (MIR) tasks by defining a comprehensive taxonomy with four hierarchy levels, including acoustic, performance, score, and high-level description. We then establish a unified protocol based on 14 tasks on 8 public-available datasets, providing a fair and standard assessment of representations of all open-sourced pre-trained models developed on music recordings as baselines. Besides, MARBLE offers an easy-to-use, extendable, and reproducible suite for the community, with a clear statement on copyright issues on datasets. Results suggest recently proposed large-scale pre-trained musical language models perform the best in most tasks, with room for further improvement. The leaderboard and toolkit repository are published at https://marble-bm.shef.ac.uk to promote future music AI research.
On the Effectiveness of Speech Self-supervised Learning for Music
Jul 11, 2023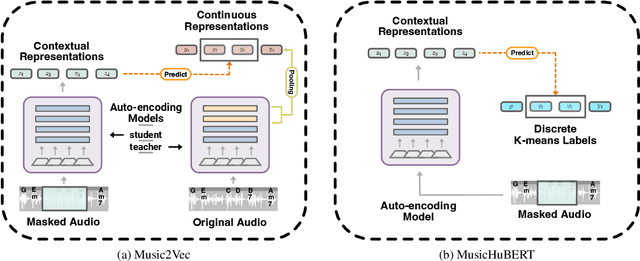
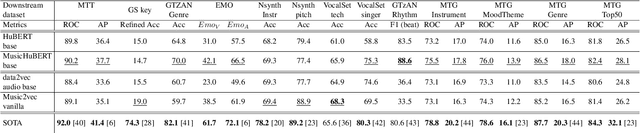

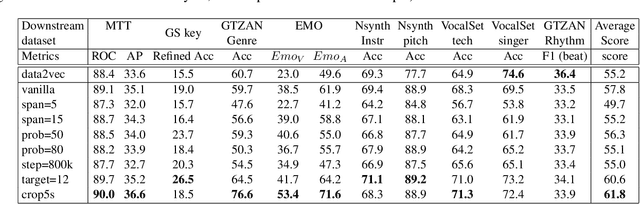
Self-supervised learning (SSL) has shown promising results in various speech and natural language processing applications. However, its efficacy in music information retrieval (MIR) still remains largely unexplored. While previous SSL models pre-trained on music recordings may have been mostly closed-sourced, recent speech models such as wav2vec2.0 have shown promise in music modelling. Nevertheless, research exploring the effectiveness of applying speech SSL models to music recordings has been limited. We explore the music adaption of SSL with two distinctive speech-related models, data2vec1.0 and Hubert, and refer to them as music2vec and musicHuBERT, respectively. We train $12$ SSL models with 95M parameters under various pre-training configurations and systematically evaluate the MIR task performances with 13 different MIR tasks. Our findings suggest that training with music data can generally improve performance on MIR tasks, even when models are trained using paradigms designed for speech. However, we identify the limitations of such existing speech-oriented designs, especially in modelling polyphonic information. Based on the experimental results, empirical suggestions are also given for designing future musical SSL strategies and paradigms.
MERT: Acoustic Music Understanding Model with Large-Scale Self-supervised Training
Jun 06, 2023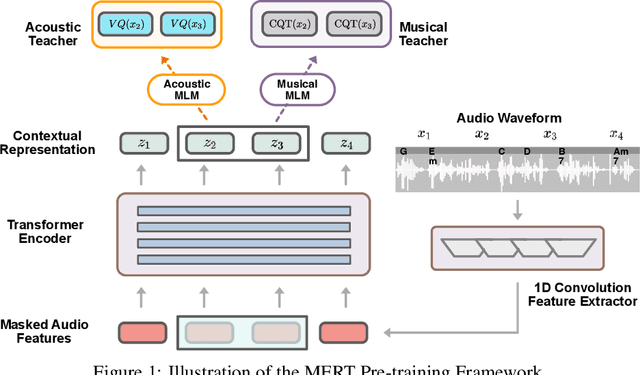
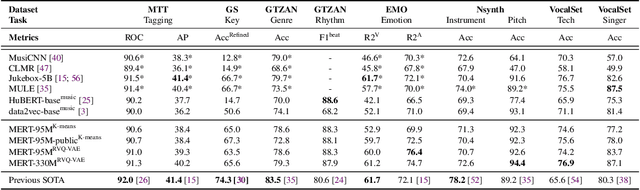
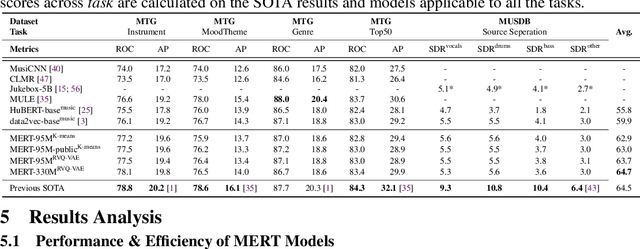
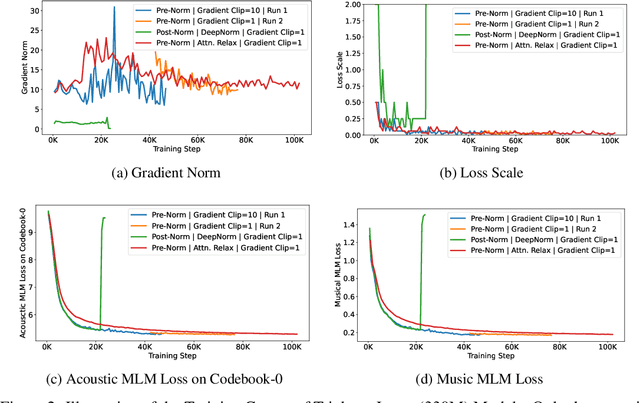
Self-supervised learning (SSL) has recently emerged as a promising paradigm for training generalisable models on large-scale data in the fields of vision, text, and speech. Although SSL has been proven effective in speech and audio, its application to music audio has yet to be thoroughly explored. This is primarily due to the distinctive challenges associated with modelling musical knowledge, particularly its tonal and pitched characteristics of music. To address this research gap, we propose an acoustic Music undERstanding model with large-scale self-supervised Training (MERT), which incorporates teacher models to provide pseudo labels in the masked language modelling (MLM) style acoustic pre-training. In our exploration, we identified a superior combination of teacher models, which outperforms conventional speech and audio approaches in terms of performance. This combination includes an acoustic teacher based on Residual Vector Quantization - Variational AutoEncoder (RVQ-VAE) and a musical teacher based on the Constant-Q Transform (CQT). These teachers effectively guide our student model, a BERT-style transformer encoder, to better model music audio. In addition, we introduce an in-batch noise mixture augmentation to enhance the representation robustness. Furthermore, we explore a wide range of settings to overcome the instability in acoustic language model pre-training, which allows our designed paradigm to scale from 95M to 330M parameters. Experimental results indicate that our model can generalise and perform well on 14 music understanding tasks and attains state-of-the-art (SOTA) overall scores. The code and models are online: https://github.com/yizhilll/MERT.
TPDM: Selectively Removing Positional Information for Zero-shot Translation via Token-Level Position Disentangle Module
May 31, 2023Due to Multilingual Neural Machine Translation's (MNMT) capability of zero-shot translation, many works have been carried out to fully exploit the potential of MNMT in zero-shot translation. It is often hypothesized that positional information may hinder the MNMT from outputting a robust encoded representation for decoding. However, previous approaches treat all the positional information equally and thus are unable to selectively remove certain positional information. In sharp contrast, this paper investigates how to learn to selectively preserve useful positional information. We describe the specific mechanism of positional information influencing MNMT from the perspective of linguistics at the token level. We design a token-level position disentangle module (TPDM) framework to disentangle positional information at the token level based on the explanation. Our experiments demonstrate that our framework improves zero-shot translation by a large margin while reducing the performance loss in the supervised direction compared to previous works.