 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Learning Strategies for Estimation Error Minimization with Graph Neural Networks
Paper and Code
Apr 04, 2024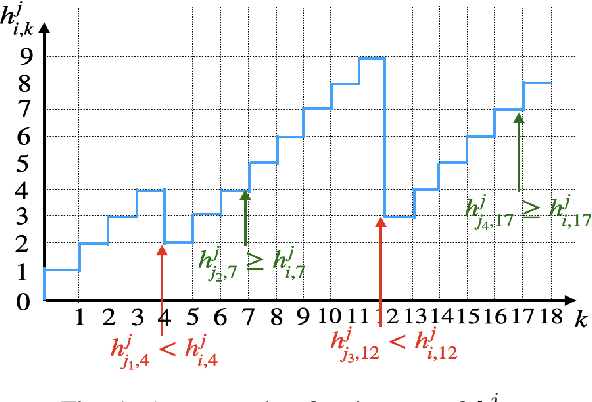
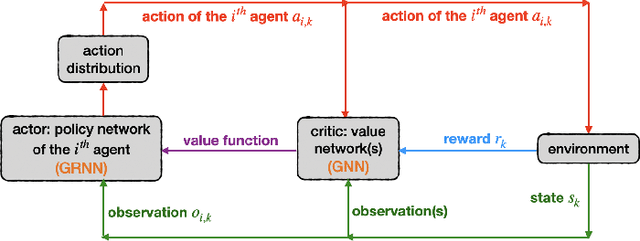
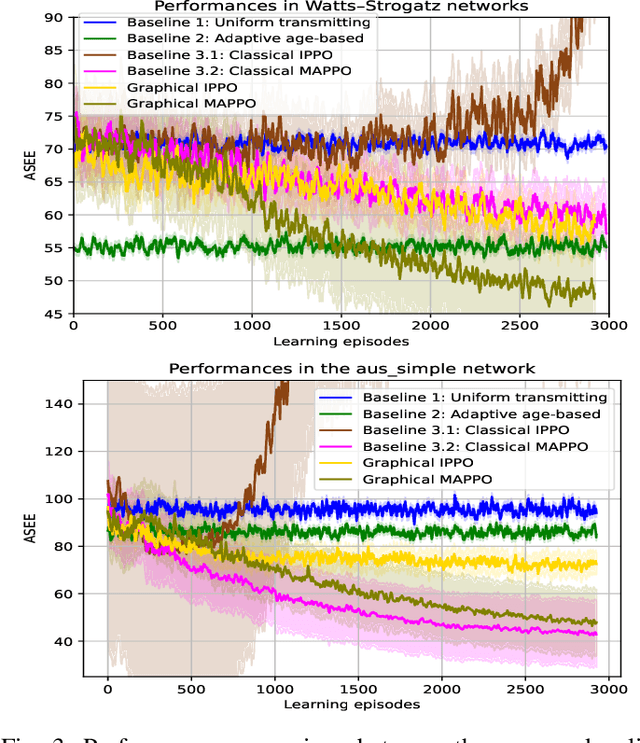
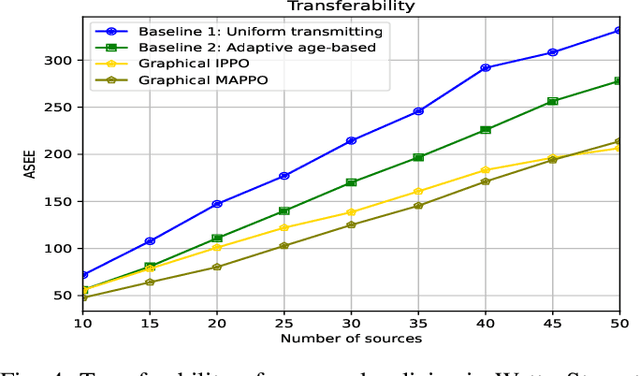
We address the challenge of sampling and remote estimation for autoregressive Markovian processes in a multi-hop wireless network with statistically-identical agents. Agents cache the most recent samples from others and communicate over wireless collision channels governed by an underlying graph topology. Our goal is to minimize time-average estimation error and/or age of information with decentralized scalable sampling and transmission policies, considering both oblivious (where decision-making is independent of the physical processes) and non-oblivious policies (where decision-making depends on physical processes). We prove that in oblivious policies, minimizing estimation error is equivalent to minimizing the age of information. The complexity of the problem, especially the multi-dimensional action spaces and arbitrary network topologies, makes theoretical methods for finding optimal transmission policies intractable. We optimize the policies using a graphical multi-agent reinforcement learning framework, where each agent employs a permutation-equivariant graph neural network architecture. Theoretically, we prove that our proposed framework exhibits desirable transferability properties, allowing transmission policies trained on small- or moderate-size networks to be executed effectively on large-scale topologies. Numerical experiments demonstrate that (i) Our proposed framework outperforms state-of-the-art baselines; (ii) The trained policies are transferable to larger networks, and their performance gains increase with the number of agents; (iii) The training procedure withstands non-stationarity even if we utilize independent learning techniques; and, (iv) Recurrence is pivotal in both independent learning and centralized training and decentralized execution, and improves the resilience to non-stationarity in independent learning.