 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLUNA: Linear Universal Neural Attention with Generalization Guarantees
Dec 08, 2025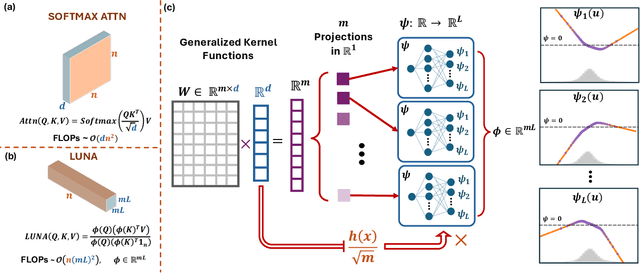
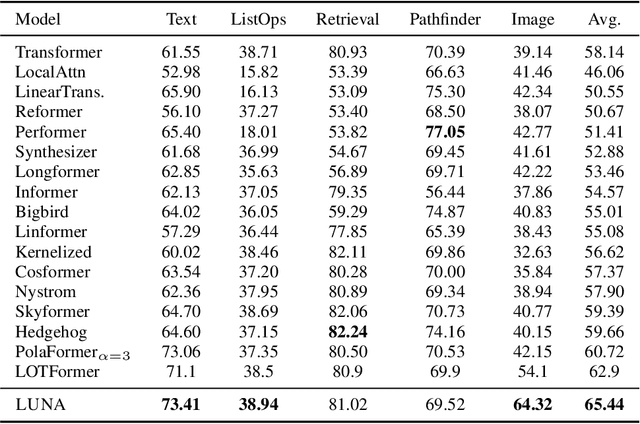
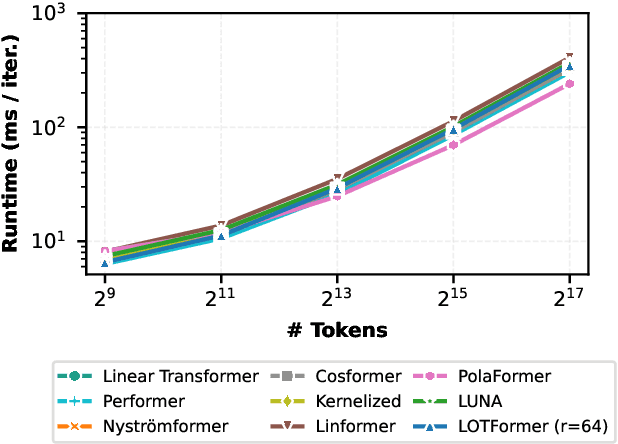
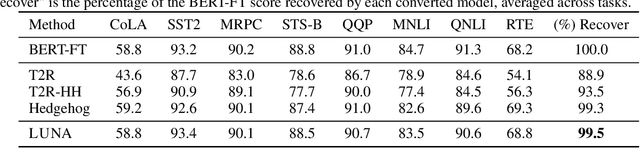
Scaling attention faces a critical bottleneck: the $\mathcal{O}(n^2)$ quadratic computational cost of softmax attention, which limits its application in long-sequence domains. While linear attention mechanisms reduce this cost to $\mathcal{O}(n)$, they typically rely on fixed random feature maps, such as random Fourier features or hand-crafted functions. This reliance on static, data-agnostic kernels creates a fundamental trade-off, forcing practitioners to sacrifice significant model accuracy for computational efficiency. We introduce \textsc{LUNA}, a kernelized linear attention mechanism that eliminates this trade-off, retaining linear cost while matching and surpassing the accuracy of quadratic attention. \textsc{LUNA} is built on the key insight that the kernel feature map itself should be learned rather than fixed a priori. By parameterizing the kernel, \textsc{LUNA} learns a feature basis tailored to the specific data and task, overcoming the expressive limitations of fixed-feature methods. \textsc{Luna} implements this with a learnable feature map that induces a positive-definite kernel and admits a streaming form, yielding linear time and memory scaling in the sequence length. Empirical evaluations validate our approach across diverse settings. On the Long Range Arena (LRA), \textsc{Luna} achieves state-of-the-art average accuracy among efficient Transformers under compute parity, using the same parameter count, training steps, and approximate FLOPs. \textsc{Luna} also excels at post-hoc conversion: replacing softmax in fine-tuned BERT and ViT-B/16 checkpoints and briefly fine-tuning recovers most of the original performance, substantially outperforming fixed linearizations.
Wireless Link Scheduling with State-Augmented Graph Neural Networks
May 12, 2025We consider the problem of optimal link scheduling in large-scale wireless ad hoc networks. We specifically aim for the maximum long-term average performance, subject to a minimum transmission requirement for each link to ensure fairness. With a graph structure utilized to represent the conflicts of links, we formulate a constrained optimization problem to learn the scheduling policy, which is parameterized with a graph neural network (GNN). To address the challenge of long-term performance, we use the state-augmentation technique. In particular, by augmenting the Lagrangian dual variables as dynamic inputs to the scheduling policy, the GNN can be trained to gradually adapt the scheduling decisions to achieve the minimum transmission requirements. We verify the efficacy of our proposed policy through numerical simulations and compare its performance with several baselines in various network settings.
Opportunistic Routing in Wireless Communications via Learnable State-Augmented Policies
Mar 05, 2025This paper addresses the challenge of packet-based information routing in large-scale wireless communication networks. The problem is framed as a constrained statistical learning task, where each network node operates using only local information. Opportunistic routing exploits the broadcast nature of wireless communication to dynamically select optimal forwarding nodes, enabling the information to reach the destination through multiple relay nodes simultaneously. To solve this, we propose a State-Augmentation (SA) based distributed optimization approach aimed at maximizing the total information handled by the source nodes in the network. The problem formulation leverages Graph Neural Networks (GNNs), which perform graph convolutions based on the topological connections between network nodes. Using an unsupervised learning paradigm, we extract routing policies from the GNN architecture, enabling optimal decisions for source nodes across various flows. Numerical experiments demonstrate that the proposed method achieves superior performance when training a GNN-parameterized model, particularly when compared to baseline algorithms. Additionally, applying the method to real-world network topologies and wireless ad-hoc network test beds validates its effectiveness, highlighting the robustness and transferability of GNNs.
Learning to Slice Wi-Fi Networks: A State-Augmented Primal-Dual Approach
May 09, 2024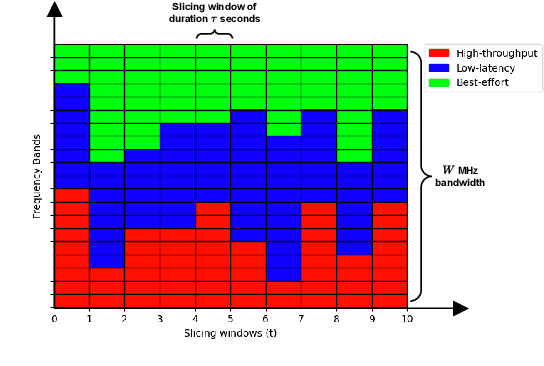
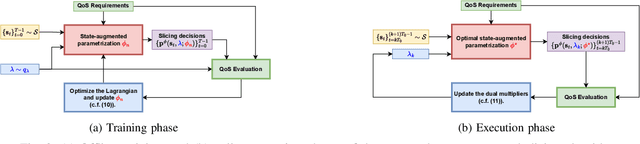
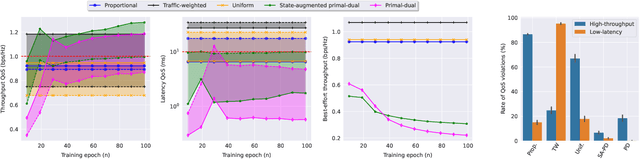
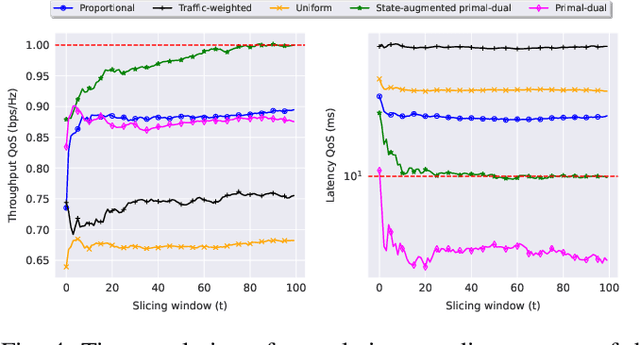
Network slicing is a key feature in 5G/NG cellular networks that creates customized slices for different service types with various quality-of-service (QoS) requirements, which can achieve service differentiation and guarantee service-level agreement (SLA) for each service type. In Wi-Fi networks, there is limited prior work on slicing, and a potential solution is based on a multi-tenant architecture on a single access point (AP) that dedicates different channels to different slices. In this paper, we define a flexible, constrained learning framework to enable slicing in Wi-Fi networks subject to QoS requirements. We specifically propose an unsupervised learning-based network slicing method that leverages a state-augmented primal-dual algorithm, where a neural network policy is trained offline to optimize a Lagrangian function and the dual variable dynamics are updated online in the execution phase. We show that state augmentation is crucial for generating slicing decisions that meet the ergodic QoS requirements.
Decentralized Learning Strategies for Estimation Error Minimization with Graph Neural Networks
Apr 04, 2024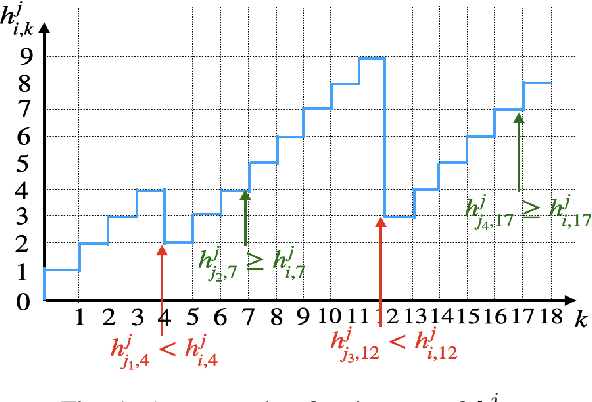
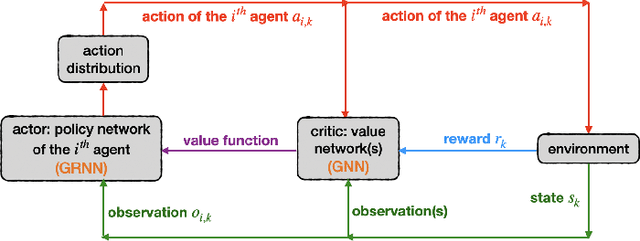
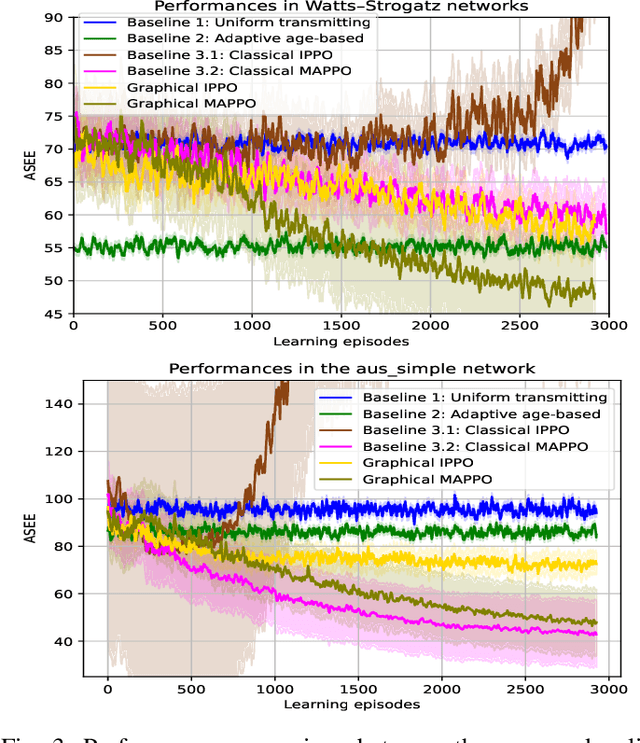
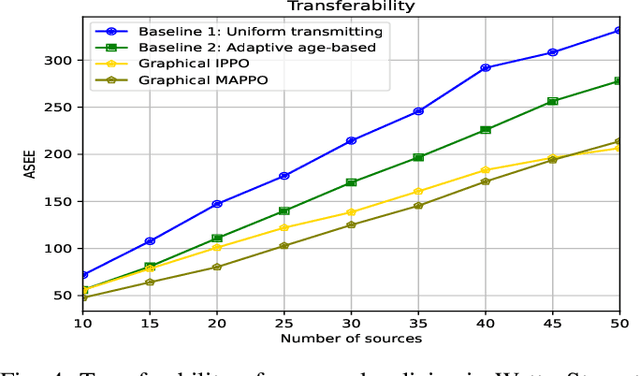
We address the challenge of sampling and remote estimation for autoregressive Markovian processes in a multi-hop wireless network with statistically-identical agents. Agents cache the most recent samples from others and communicate over wireless collision channels governed by an underlying graph topology. Our goal is to minimize time-average estimation error and/or age of information with decentralized scalable sampling and transmission policies, considering both oblivious (where decision-making is independent of the physical processes) and non-oblivious policies (where decision-making depends on physical processes). We prove that in oblivious policies, minimizing estimation error is equivalent to minimizing the age of information. The complexity of the problem, especially the multi-dimensional action spaces and arbitrary network topologies, makes theoretical methods for finding optimal transmission policies intractable. We optimize the policies using a graphical multi-agent reinforcement learning framework, where each agent employs a permutation-equivariant graph neural network architecture. Theoretically, we prove that our proposed framework exhibits desirable transferability properties, allowing transmission policies trained on small- or moderate-size networks to be executed effectively on large-scale topologies. Numerical experiments demonstrate that (i) Our proposed framework outperforms state-of-the-art baselines; (ii) The trained policies are transferable to larger networks, and their performance gains increase with the number of agents; (iii) The training procedure withstands non-stationarity even if we utilize independent learning techniques; and, (iv) Recurrence is pivotal in both independent learning and centralized training and decentralized execution, and improves the resilience to non-stationarity in independent learning.
Robust Stochastically-Descending Unrolled Networks
Dec 25, 2023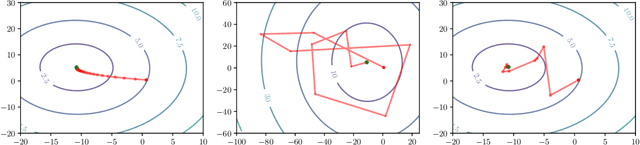
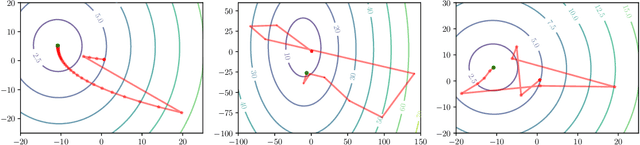
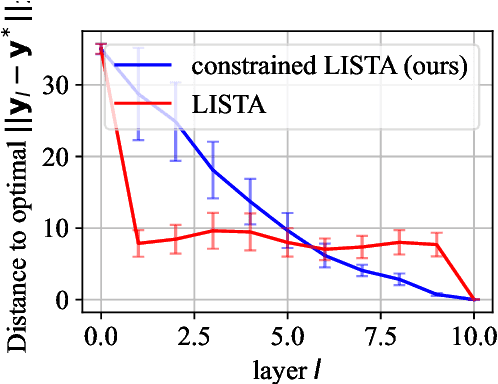
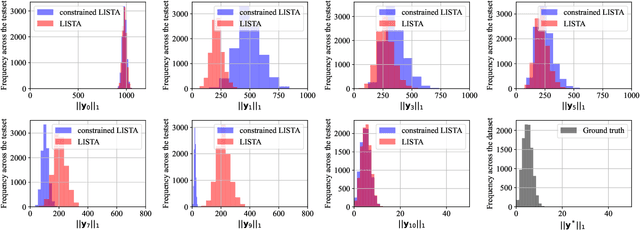
Deep unrolling, or unfolding, is an emerging learning-to-optimize method that unrolls a truncated iterative algorithm in the layers of a trainable neural network. However, the convergence guarantees and generalizability of the unrolled networks are still open theoretical problems. To tackle these problems, we provide deep unrolled architectures with a stochastic descent nature by imposing descending constraints during training. The descending constraints are forced layer by layer to ensure that each unrolled layer takes, on average, a descent step toward the optimum during training. We theoretically prove that the sequence constructed by the outputs of the unrolled layers is then guaranteed to converge for unseen problems, assuming no distribution shift between training and test problems. We also show that standard unrolling is brittle to perturbations, and our imposed constraints provide the unrolled networks with robustness to additive noise and perturbations. We numerically assess unrolled architectures trained under the proposed constraints in two different applications, including the sparse coding using learnable iterative shrinkage and thresholding algorithm (LISTA) and image inpainting using proximal generative flow (GLOW-Prox), and demonstrate the performance and robustness benefits of the proposed method.
Learning State-Augmented Policies for Information Routing in Communication Networks
Sep 30, 2023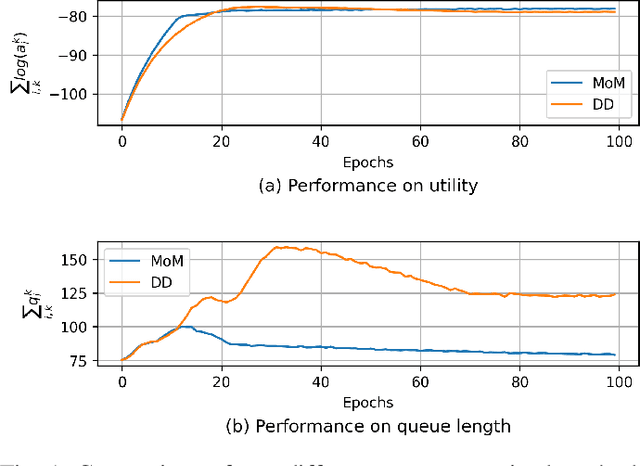
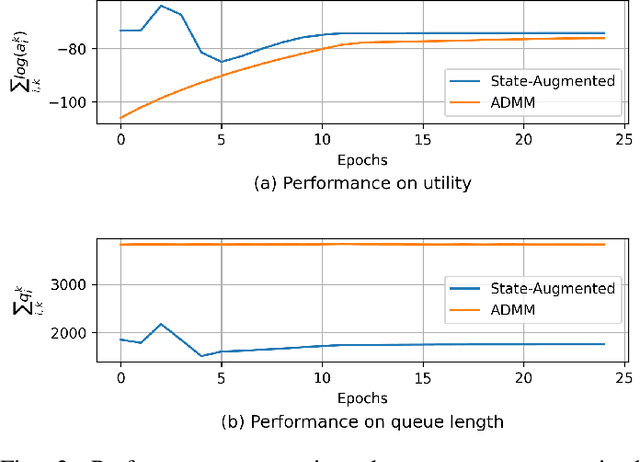
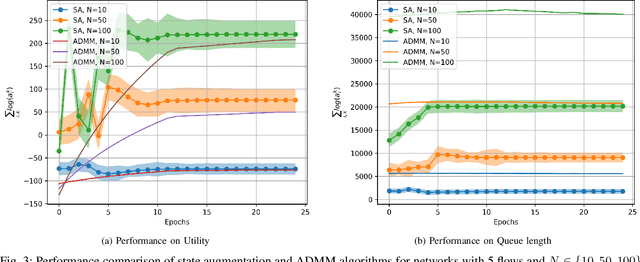
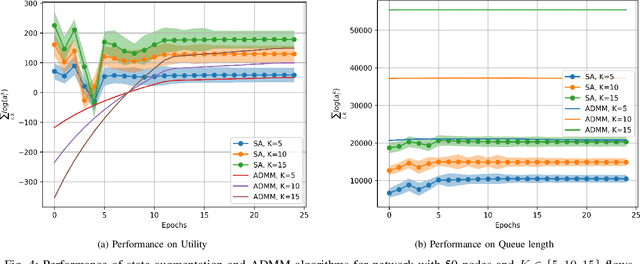
This paper examines the problem of information routing in a large-scale communication network, which can be formulated as a constrained statistical learning problem having access to only local information. We delineate a novel State Augmentation (SA) strategy to maximize the aggregate information at source nodes using graph neural network (GNN) architectures, by deploying graph convolutions over the topological links of the communication network. The proposed technique leverages only the local information available at each node and efficiently routes desired information to the destination nodes. We leverage an unsupervised learning procedure to convert the output of the GNN architecture to optimal information routing strategies. In the experiments, we perform the evaluation on real-time network topologies to validate our algorithms. Numerical simulations depict the improved performance of the proposed method in training a GNN parameterization as compared to baseline algorithms.
Primal-Dual Continual Learning: Stability and Plasticity through Lagrange Multipliers
Sep 29, 2023



Continual learning is inherently a constrained learning problem. The goal is to learn a predictor under a \emph{no-forgetting} requirement. Although several prior studies formulate it as such, they do not solve the constrained problem explicitly. In this work, we show that it is both possible and beneficial to undertake the constrained optimization problem directly. To do this, we leverage recent results in constrained learning through Lagrangian duality. We focus on memory-based methods, where a small subset of samples from previous tasks can be stored in a replay buffer. In this setting, we analyze two versions of the continual learning problem: a coarse approach with constraints at the task level and a fine approach with constraints at the sample level. We show that dual variables indicate the sensitivity of the optimal value with respect to constraint perturbations. We then leverage this result to partition the buffer in the coarse approach, allocating more resources to harder tasks, and to populate the buffer in the fine approach, including only impactful samples. We derive sub-optimality bounds, and empirically corroborate our theoretical results in various continual learning benchmarks. We also discuss the limitations of these methods with respect to the amount of memory available and the number of constraints involved in the optimization problem.
Stochastic Unrolled Federated Learning
May 24, 2023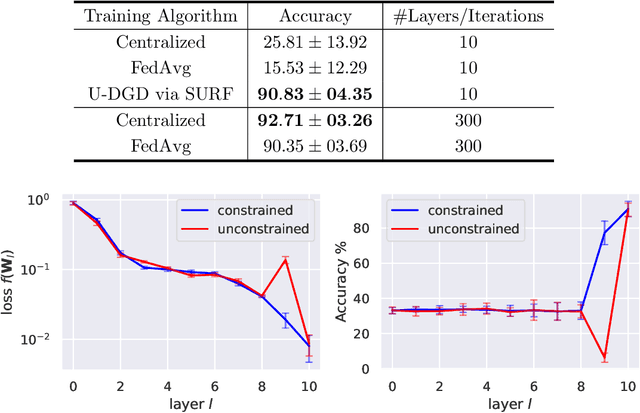
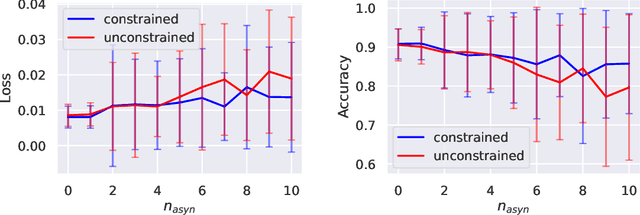


Algorithm unrolling has emerged as a learning-based optimization paradigm that unfolds truncated iterative algorithms in trainable neural-network optimizers. We introduce Stochastic UnRolled Federated learning (SURF), a method that expands algorithm unrolling to a federated learning scenario. Our proposed method tackles two challenges of this expansion, namely the need to feed whole datasets to the unrolled optimizers to find a descent direction and the decentralized nature of federated learning. We circumvent the former challenge by feeding stochastic mini-batches to each unrolled layer and imposing descent constraints to mitigate the randomness induced by using mini-batches. We address the latter challenge by unfolding the distributed gradient descent (DGD) algorithm in a graph neural network (GNN)-based unrolled architecture, which preserves the decentralized nature of training in federated learning. We theoretically prove that our proposed unrolled optimizer converges to a near-optimal region infinitely often. Through extensive numerical experiments, we also demonstrate the effectiveness of the proposed framework in collaborative training of image classifiers.
A State-Augmented Approach for Learning Optimal Resource Management Decisions in Wireless Networks
Nov 09, 2022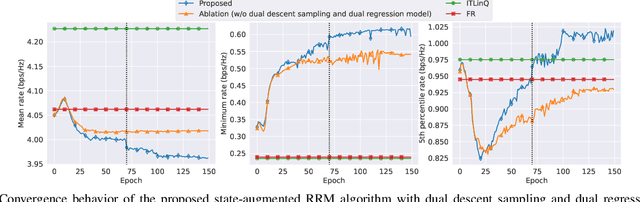
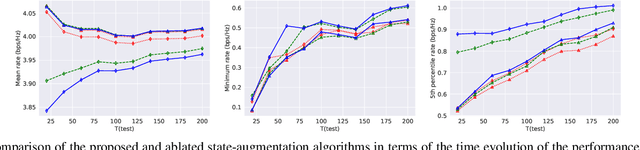
We consider a radio resource management (RRM) problem in a multi-user wireless network, where the goal is to optimize a network-wide utility function subject to constraints on the ergodic average performance of users. We propose a state-augmented parameterization for the RRM policy, where alongside the instantaneous network states, the RRM policy takes as input the set of dual variables corresponding to the constraints. We provide theoretical justification for the feasibility and near-optimality of the RRM decisions generated by the proposed state-augmented algorithm. Focusing on the power allocation problem with RRM policies parameterized by a graph neural network (GNN) and dual variables sampled from the dual descent dynamics, we numerically demonstrate that the proposed approach achieves a superior trade-off between mean, minimum, and 5th percentile rates than baseline methods.