 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnrolled Neural Networks for Constrained Optimization
Jan 24, 2026In this paper, we develop unrolled neural networks to solve constrained optimization problems, offering accelerated, learnable counterparts to dual ascent (DA) algorithms. Our framework, termed constrained dual unrolling (CDU), comprises two coupled neural networks that jointly approximate the saddle point of the Lagrangian. The primal network emulates an iterative optimizer that finds a stationary point of the Lagrangian for a given dual multiplier, sampled from an unknown distribution. The dual network generates trajectories towards the optimal multipliers across its layers while querying the primal network at each layer. Departing from standard unrolling, we induce DA dynamics by imposing primal-descent and dual-ascent constraints through constrained learning. We formulate training the two networks as a nested optimization problem and propose an alternating procedure that updates the primal and dual networks in turn, mitigating uncertainty in the multiplier distribution required for primal network training. We numerically evaluate the framework on mixed-integer quadratic programs (MIQPs) and power allocation in wireless networks. In both cases, our approach yields near-optimal near-feasible solutions and exhibits strong out-of-distribution (OOD) generalization.
A Constrained Optimization Perspective of Unrolled Transformers
Jan 24, 2026We introduce a constrained optimization framework for training transformers that behave like optimization descent algorithms. Specifically, we enforce layerwise descent constraints on the objective function and replace standard empirical risk minimization (ERM) with a primal-dual training scheme. This approach yields models whose intermediate representations decrease the loss monotonically in expectation across layers. We apply our method to both unrolled transformer architectures and conventional pretrained transformers on tasks of video denoising and text classification. Across these settings, we observe constrained transformers achieve stronger robustness to perturbations and maintain higher out-of-distribution generalization, while preserving in-distribution performance.
Generative Diffusion Models for Resource Allocation in Wireless Networks
Apr 28, 2025This paper proposes a supervised training algorithm for learning stochastic resource allocation policies with generative diffusion models (GDMs). We formulate the allocation problem as the maximization of an ergodic utility function subject to ergodic Quality of Service (QoS) constraints. Given samples from a stochastic expert policy that yields a near-optimal solution to the problem, we train a GDM policy to imitate the expert and generate new samples from the optimal distribution. We achieve near-optimal performance through sequential execution of the generated samples. To enable generalization to a family of network configurations, we parameterize the backward diffusion process with a graph neural network (GNN) architecture. We present numerical results in a case study of power control in multi-user interference networks.
Robust Stochastically-Descending Unrolled Networks
Dec 25, 2023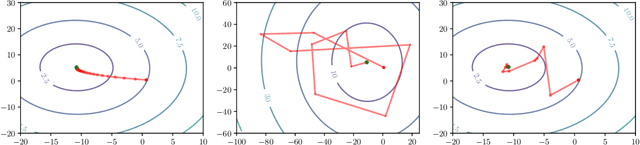
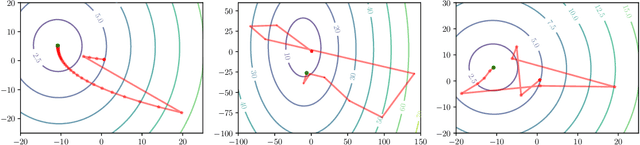
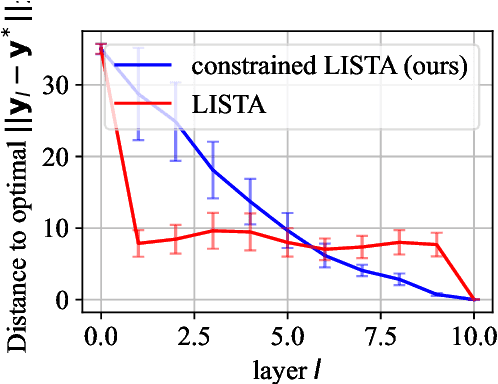
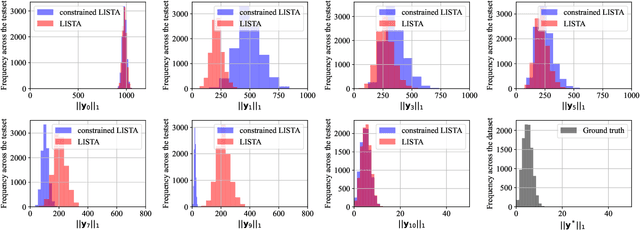
Deep unrolling, or unfolding, is an emerging learning-to-optimize method that unrolls a truncated iterative algorithm in the layers of a trainable neural network. However, the convergence guarantees and generalizability of the unrolled networks are still open theoretical problems. To tackle these problems, we provide deep unrolled architectures with a stochastic descent nature by imposing descending constraints during training. The descending constraints are forced layer by layer to ensure that each unrolled layer takes, on average, a descent step toward the optimum during training. We theoretically prove that the sequence constructed by the outputs of the unrolled layers is then guaranteed to converge for unseen problems, assuming no distribution shift between training and test problems. We also show that standard unrolling is brittle to perturbations, and our imposed constraints provide the unrolled networks with robustness to additive noise and perturbations. We numerically assess unrolled architectures trained under the proposed constraints in two different applications, including the sparse coding using learnable iterative shrinkage and thresholding algorithm (LISTA) and image inpainting using proximal generative flow (GLOW-Prox), and demonstrate the performance and robustness benefits of the proposed method.
Stochastic Unrolled Federated Learning
May 24, 2023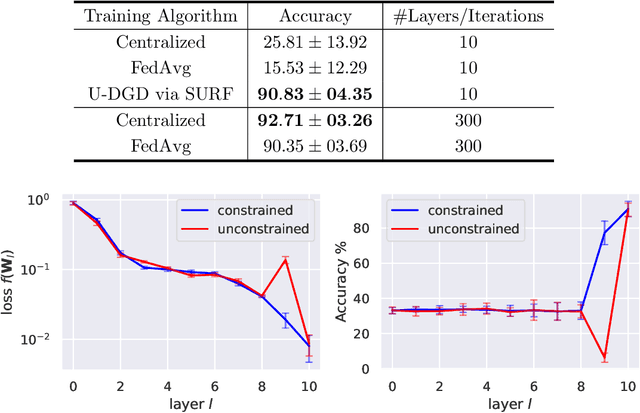
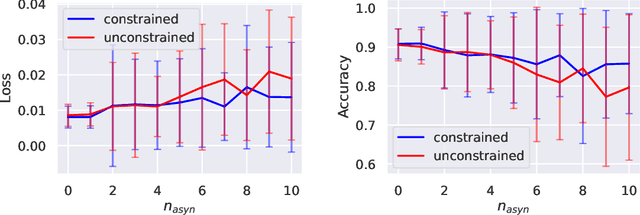


Algorithm unrolling has emerged as a learning-based optimization paradigm that unfolds truncated iterative algorithms in trainable neural-network optimizers. We introduce Stochastic UnRolled Federated learning (SURF), a method that expands algorithm unrolling to a federated learning scenario. Our proposed method tackles two challenges of this expansion, namely the need to feed whole datasets to the unrolled optimizers to find a descent direction and the decentralized nature of federated learning. We circumvent the former challenge by feeding stochastic mini-batches to each unrolled layer and imposing descent constraints to mitigate the randomness induced by using mini-batches. We address the latter challenge by unfolding the distributed gradient descent (DGD) algorithm in a graph neural network (GNN)-based unrolled architecture, which preserves the decentralized nature of training in federated learning. We theoretically prove that our proposed unrolled optimizer converges to a near-optimal region infinitely often. Through extensive numerical experiments, we also demonstrate the effectiveness of the proposed framework in collaborative training of image classifiers.
Space-Time Graph Neural Networks with Stochastic Graph Perturbations
Oct 28, 2022

Space-time graph neural networks (ST-GNNs) are recently developed architectures that learn efficient graph representations of time-varying data. ST-GNNs are particularly useful in multi-agent systems, due to their stability properties and their ability to respect communication delays between the agents. In this paper we revisit the stability properties of ST-GNNs and prove that they are stable to stochastic graph perturbations. Our analysis suggests that ST-GNNs are suitable for transfer learning on time-varying graphs and enables the design of generalized convolutional architectures that jointly process time-varying graphs and time-varying signals. Numerical experiments on decentralized control systems validate our theoretical results and showcase the benefits of traditional and generalized ST-GNN architectures.
Space-Time Graph Neural Networks
Oct 06, 2021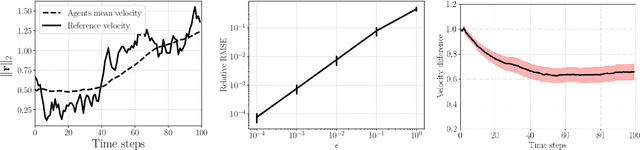
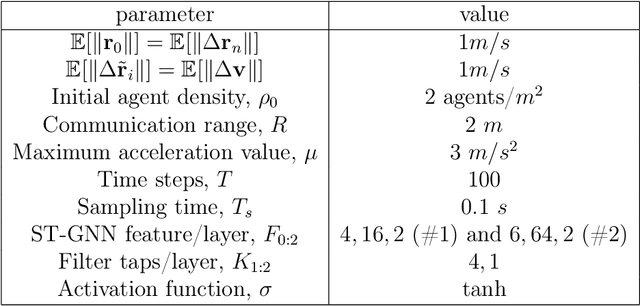
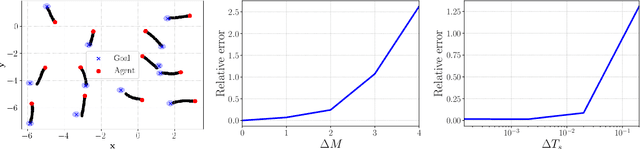
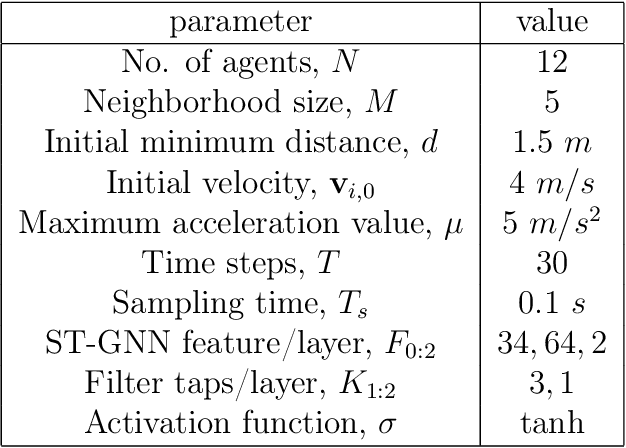
We introduce space-time graph neural network (ST-GNN), a novel GNN architecture, tailored to jointly process the underlying space-time topology of time-varying network data. The cornerstone of our proposed architecture is the composition of time and graph convolutional filters followed by pointwise nonlinear activation functions. We introduce a generic definition of convolution operators that mimic the diffusion process of signals over its underlying support. On top of this definition, we propose space-time graph convolutions that are built upon a composition of time and graph shift operators. We prove that ST-GNNs with multivariate integral Lipschitz filters are stable to small perturbations in the underlying graphs as well as small perturbations in the time domain caused by time warping. Our analysis shows that small variations in the network topology and time evolution of a system does not significantly affect the performance of ST-GNNs. Numerical experiments with decentralized control systems showcase the effectiveness and stability of the proposed ST-GNNs.