 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Message-passing and spectral GNNs are two sides of the same coin
Feb 10, 2026Graph neural networks (GNNs) are commonly divided into message-passing neural networks (MPNNs) and spectral graph neural networks, reflecting two largely separate research traditions in machine learning and signal processing. This paper argues that this divide is mostly artificial, hindering progress in the field. We propose a viewpoint in which both MPNNs and spectral GNNs are understood as different parametrizations of permutation-equivariant operators acting on graph signals. From this perspective, many popular architectures are equivalent in expressive power, while genuine gaps arise only in specific regimes. We further argue that MPNNs and spectral GNNs offer complementary strengths. That is, MPNNs provide a natural language for discrete structure and expressivity analysis using tools from logic and graph isomorphism research, while the spectral perspective provides principled tools for understanding smoothing, bottlenecks, stability, and community structure. Overall, we posit that progress in graph learning will be accelerated by clearly understanding the key similarities and differences between these two types of GNNs, and by working towards unifying these perspectives within a common theoretical and conceptual framework rather than treating them as competing paradigms.
Relational Graph Transformer
May 16, 2025Relational Deep Learning (RDL) is a promising approach for building state-of-the-art predictive models on multi-table relational data by representing it as a heterogeneous temporal graph. However, commonly used Graph Neural Network models suffer from fundamental limitations in capturing complex structural patterns and long-range dependencies that are inherent in relational data. While Graph Transformers have emerged as powerful alternatives to GNNs on general graphs, applying them to relational entity graphs presents unique challenges: (i) Traditional positional encodings fail to generalize to massive, heterogeneous graphs; (ii) existing architectures cannot model the temporal dynamics and schema constraints of relational data; (iii) existing tokenization schemes lose critical structural information. Here we introduce the Relational Graph Transformer (RelGT), the first graph transformer architecture designed specifically for relational tables. RelGT employs a novel multi-element tokenization strategy that decomposes each node into five components (features, type, hop distance, time, and local structure), enabling efficient encoding of heterogeneity, temporality, and topology without expensive precomputation. Our architecture combines local attention over sampled subgraphs with global attention to learnable centroids, incorporating both local and database-wide representations. Across 21 tasks from the RelBench benchmark, RelGT consistently matches or outperforms GNN baselines by up to 18%, establishing Graph Transformers as a powerful architecture for Relational Deep Learning.
Learning Efficient Positional Encodings with Graph Neural Networks
Feb 03, 2025



Positional encodings (PEs) are essential for effective graph representation learning because they provide position awareness in inherently position-agnostic transformer architectures and increase the expressive capacity of Graph Neural Networks (GNNs). However, designing powerful and efficient PEs for graphs poses significant challenges due to the absence of canonical node ordering and the scale of the graph. {In this work, we identify four key properties that graph PEs should satisfy}: stability, expressive power, scalability, and genericness. We find that existing eigenvector-based PE methods often fall short of jointly satisfying these criteria. To address this gap, we introduce PEARL, a novel framework of learnable PEs for graphs. Our primary insight is that message-passing GNNs function as nonlinear mappings of eigenvectors, enabling the design of GNN architectures for generating powerful and efficient PEs. A crucial challenge lies in initializing node attributes in a manner that is both expressive and permutation equivariant. We tackle this by initializing GNNs with random node inputs or standard basis vectors, thereby unlocking the expressive power of message-passing operations, while employing statistical pooling functions to maintain permutation equivariance. Our analysis demonstrates that PEARL approximates equivariant functions of eigenvectors with linear complexity, while rigorously establishing its stability and high expressive power. Experimental evaluations show that PEARL outperforms lightweight versions of eigenvector-based PEs and achieves comparable performance to full eigenvector-based PEs, but with one or two orders of magnitude lower complexity. Our code is available at https://github.com/ehejin/Pearl-PE.
Generalizability of Graph Neural Networks for Decentralized Unlabeled Motion Planning
Sep 29, 2024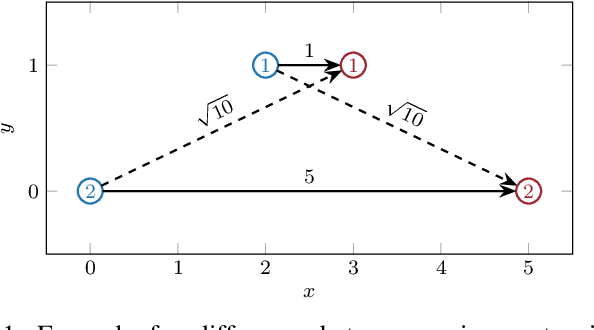
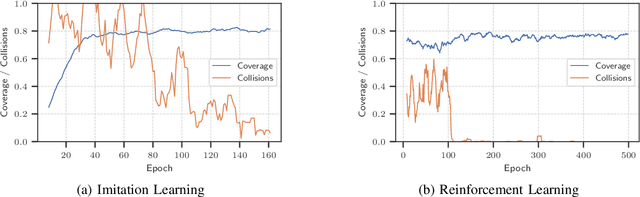
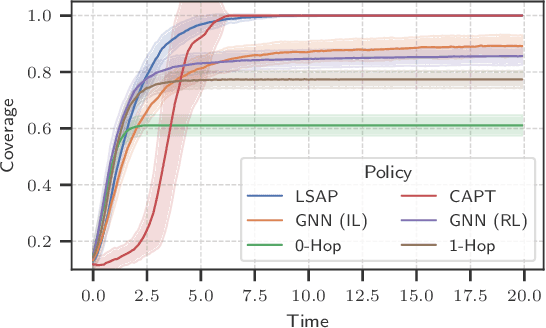
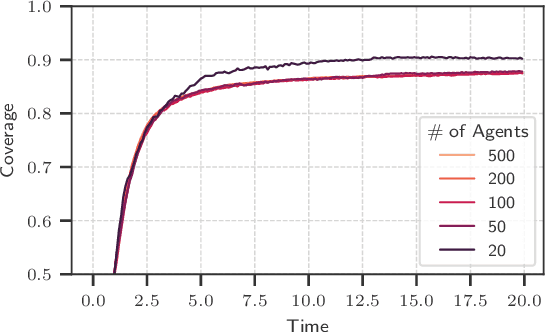
Unlabeled motion planning involves assigning a set of robots to target locations while ensuring collision avoidance, aiming to minimize the total distance traveled. The problem forms an essential building block for multi-robot systems in applications such as exploration, surveillance, and transportation. We address this problem in a decentralized setting where each robot knows only the positions of its $k$-nearest robots and $k$-nearest targets. This scenario combines elements of combinatorial assignment and continuous-space motion planning, posing significant scalability challenges for traditional centralized approaches. To overcome these challenges, we propose a decentralized policy learned via a Graph Neural Network (GNN). The GNN enables robots to determine (1) what information to communicate to neighbors and (2) how to integrate received information with local observations for decision-making. We train the GNN using imitation learning with the centralized Hungarian algorithm as the expert policy, and further fine-tune it using reinforcement learning to avoid collisions and enhance performance. Extensive empirical evaluations demonstrate the scalability and effectiveness of our approach. The GNN policy trained on 100 robots generalizes to scenarios with up to 500 robots, outperforming state-of-the-art solutions by 8.6\% on average and significantly surpassing greedy decentralized methods. This work lays the foundation for solving multi-robot coordination problems in settings where scalability is important.
Network Alignment with Transferable Graph Autoencoders
Oct 05, 2023Network alignment is the task of establishing one-to-one correspondences between the nodes of different graphs and finds a plethora of applications in high-impact domains. However, this task is known to be NP-hard in its general form, and existing algorithms do not scale up as the size of the graphs increases. To tackle both challenges we propose a novel generalized graph autoencoder architecture, designed to extract powerful and robust node embeddings, that are tailored to the alignment task. We prove that the generated embeddings are associated with the eigenvalues and eigenvectors of the graphs and can achieve more accurate alignment compared to classical spectral methods. Our proposed framework also leverages transfer learning and data augmentation to achieve efficient network alignment at a very large scale without retraining. Extensive experiments on both network and sub-network alignment with real-world graphs provide corroborating evidence supporting the effectiveness and scalability of the proposed approach.
Transferability of Convolutional Neural Networks in Stationary Learning Tasks
Jul 21, 2023



Recent advances in hardware and big data acquisition have accelerated the development of deep learning techniques. For an extended period of time, increasing the model complexity has led to performance improvements for various tasks. However, this trend is becoming unsustainable and there is a need for alternative, computationally lighter methods. In this paper, we introduce a novel framework for efficient training of convolutional neural networks (CNNs) for large-scale spatial problems. To accomplish this we investigate the properties of CNNs for tasks where the underlying signals are stationary. We show that a CNN trained on small windows of such signals achieves a nearly performance on much larger windows without retraining. This claim is supported by our theoretical analysis, which provides a bound on the performance degradation. Additionally, we conduct thorough experimental analysis on two tasks: multi-target tracking and mobile infrastructure on demand. Our results show that the CNN is able to tackle problems with many hundreds of agents after being trained with fewer than ten. Thus, CNN architectures provide solutions to these problems at previously computationally intractable scales.
Solving Large-scale Spatial Problems with Convolutional Neural Networks
Jun 14, 2023Over the past decade, deep learning research has been accelerated by increasingly powerful hardware, which facilitated rapid growth in the model complexity and the amount of data ingested. This is becoming unsustainable and therefore refocusing on efficiency is necessary. In this paper, we employ transfer learning to improve training efficiency for large-scale spatial problems. We propose that a convolutional neural network (CNN) can be trained on small windows of signals, but evaluated on arbitrarily large signals with little to no performance degradation, and provide a theoretical bound on the resulting generalization error. Our proof leverages shift-equivariance of CNNs, a property that is underexploited in transfer learning. The theoretical results are experimentally supported in the context of mobile infrastructure on demand (MID). The proposed approach is able to tackle MID at large scales with hundreds of agents, which was computationally intractable prior to this work.
Graph Neural Networks Are More Powerful Than we Think
May 19, 2022
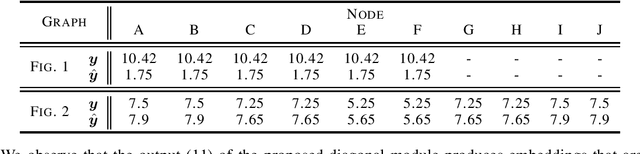
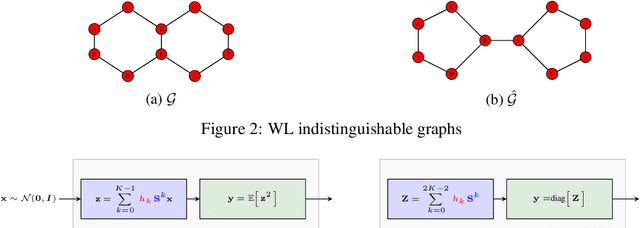

Graph Neural Networks (GNNs) are powerful convolutional architectures that have shown remarkable performance in various node-level and graph-level tasks. Despite their success, the common belief is that the expressive power of GNNs is limited and that they are at most as discriminative as the Weisfeiler-Lehman (WL) algorithm. In this paper we argue the opposite and show that the WL algorithm is the upper bound only when the input to the GNN is the vector of all ones. In this direction, we derive an alternative analysis that employs linear algebraic tools and characterize the representational power of GNNs with respect to the eigenvalue decomposition of the graph operators. We show that GNNs can distinguish between any graphs that differ in at least one eigenvalue and design simple GNN architectures that are provably more expressive than the WL algorithm. Thorough experimental analysis on graph isomorphism and graph classification datasets corroborates our theoretical results and demonstrates the effectiveness of the proposed architectures.
Space-Time Graph Neural Networks
Oct 06, 2021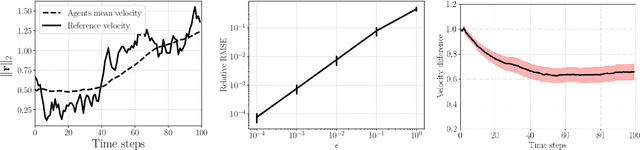
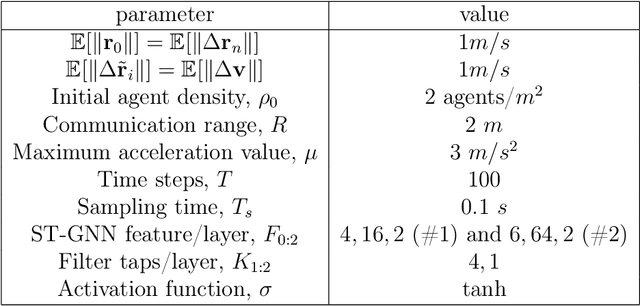
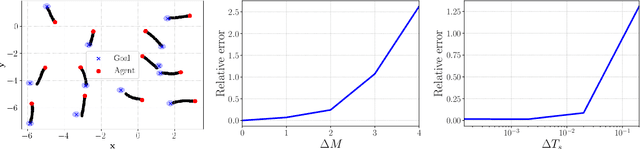
We introduce space-time graph neural network (ST-GNN), a novel GNN architecture, tailored to jointly process the underlying space-time topology of time-varying network data. The cornerstone of our proposed architecture is the composition of time and graph convolutional filters followed by pointwise nonlinear activation functions. We introduce a generic definition of convolution operators that mimic the diffusion process of signals over its underlying support. On top of this definition, we propose space-time graph convolutions that are built upon a composition of time and graph shift operators. We prove that ST-GNNs with multivariate integral Lipschitz filters are stable to small perturbations in the underlying graphs as well as small perturbations in the time domain caused by time warping. Our analysis shows that small variations in the network topology and time evolution of a system does not significantly affect the performance of ST-GNNs. Numerical experiments with decentralized control systems showcase the effectiveness and stability of the proposed ST-GNNs.
GAGE: Geometry Preserving Attributed Graph Embeddings
Nov 03, 2020


Node representation learning is the task of extracting concise and informative feature embeddings of certain entities that are connected in a network. Many real world network datasets include information about both node connectivity and certain node attributes, in the form of features or time-series data. Modern representation learning techniques utilize both connectivity and attribute information of the nodes to produce embeddings in an unsupervised manner. In this context, deriving embeddings that preserve the geometry of the network and the attribute vectors would be highly desirable, as they would reflect both the topological neighborhood structure and proximity in feature space. While this is fairly straightforward to maintain when only observing the connectivity or attributed information of the network, preserving the geometry of both types of information is challenging. A novel tensor factorization approach for node embedding in attributed networks that preserves the distances of both the connections and the attributes is proposed in this paper, along with an effective and lightweight algorithm to tackle the learning task. Judicious experiments with multiple state-of-art baselines suggest that the proposed algorithm offers significant performance improvements in node classification and link prediction tasks.