 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKumoRFM-2: Scaling Foundation Models for Relational Learning
Apr 14, 2026We introduce KumoRFM-2, the next iteration of a pre-trained foundation model for relational data. KumoRFM-2 supports in-context learning as well as fine-tuning and is applicable to a wide range of predictive tasks. In contrast to tabular foundation models, KumoRFM-2 natively operates on relational data, processing one or more connected tables simultaneously without manual table flattening or target variable generation, all while preserving temporal consistency. KumoRFM-2 leverages a large corpus of synthetic and real-world data to pre-train across four axes: the row and column dimensions at the individual table level, and the foreign key and cross-sample dimensions at the database level. In contrast to its predecessor, KumoRFM-2 injects task information as early as possible, enabling sharper selection of task-relevant columns and improved robustness to noisy data. Through extensive experiments on 41 challenging benchmarks and analysis around expressivity and sensitivity, we demonstrate that KumoRFM-2 outperforms supervised and foundational approaches by up to 8%, while maintaining strong performance under extreme settings of cold start and noisy data. To our knowledge, this is the first time a few-shot foundation model has been shown to surpass supervised approaches on common benchmark tasks, with performance further improving upon fine-tuning. Finally, while KumoRFM-1 was limited to small-scale in-memory datasets, KumoRFM-2 scales to billion-scale relational datasets.
Predictive Query Language: A Domain-Specific Language for Predictive Modeling on Relational Databases
Feb 16, 2026The purpose of predictive modeling on relational data is to predict future or missing values in a relational database, for example, future purchases of a user, risk of readmission of the patient, or the likelihood that a financial transaction is fraudulent. Typically powered by machine learning methods, predictive models are used in recommendations, financial fraud detection, supply chain optimization, and other systems, providing billions of predictions every day. However, training a machine learning model requires manual work to extract the required training examples - prediction entities and target labels - from the database, which is slow, laborious, and prone to mistakes. Here, we present the Predictive Query Language (PQL), an SQL-inspired declarative language for defining predictive tasks on relational databases. PQL allows specifying a predictive task in a single declarative query, enabling the automatic computation of training labels for a large variety of machine learning tasks, such as regression, classification, time-series forecasting, and recommender systems. PQL is already successfully integrated and used in a collection of use cases as part of a predictive AI platform. The versatility of the language can be demonstrated through its many ongoing use cases, including financial fraud, item recommendations, and workload prediction. We demonstrate its versatile design through two implementations; one for small-scale, low-latency use and one that can handle large-scale databases.
PyG 2.0: Scalable Learning on Real World Graphs
Jul 22, 2025PyG (PyTorch Geometric) has evolved significantly since its initial release, establishing itself as a leading framework for Graph Neural Networks. In this paper, we present Pyg 2.0 (and its subsequent minor versions), a comprehensive update that introduces substantial improvements in scalability and real-world application capabilities. We detail the framework's enhanced architecture, including support for heterogeneous and temporal graphs, scalable feature/graph stores, and various optimizations, enabling researchers and practitioners to tackle large-scale graph learning problems efficiently. Over the recent years, PyG has been supporting graph learning in a large variety of application areas, which we will summarize, while providing a deep dive into the important areas of relational deep learning and large language modeling.
Relational Graph Transformer
May 16, 2025Relational Deep Learning (RDL) is a promising approach for building state-of-the-art predictive models on multi-table relational data by representing it as a heterogeneous temporal graph. However, commonly used Graph Neural Network models suffer from fundamental limitations in capturing complex structural patterns and long-range dependencies that are inherent in relational data. While Graph Transformers have emerged as powerful alternatives to GNNs on general graphs, applying them to relational entity graphs presents unique challenges: (i) Traditional positional encodings fail to generalize to massive, heterogeneous graphs; (ii) existing architectures cannot model the temporal dynamics and schema constraints of relational data; (iii) existing tokenization schemes lose critical structural information. Here we introduce the Relational Graph Transformer (RelGT), the first graph transformer architecture designed specifically for relational tables. RelGT employs a novel multi-element tokenization strategy that decomposes each node into five components (features, type, hop distance, time, and local structure), enabling efficient encoding of heterogeneity, temporality, and topology without expensive precomputation. Our architecture combines local attention over sampled subgraphs with global attention to learnable centroids, incorporating both local and database-wide representations. Across 21 tasks from the RelBench benchmark, RelGT consistently matches or outperforms GNN baselines by up to 18%, establishing Graph Transformers as a powerful architecture for Relational Deep Learning.
ContextGNN: Beyond Two-Tower Recommendation Systems
Nov 29, 2024



Recommendation systems predominantly utilize two-tower architectures, which evaluate user-item rankings through the inner product of their respective embeddings. However, one key limitation of two-tower models is that they learn a pair-agnostic representation of users and items. In contrast, pair-wise representations either scale poorly due to their quadratic complexity or are too restrictive on the candidate pairs to rank. To address these issues, we introduce Context-based Graph Neural Networks (ContextGNNs), a novel deep learning architecture for link prediction in recommendation systems. The method employs a pair-wise representation technique for familiar items situated within a user's local subgraph, while leveraging two-tower representations to facilitate the recommendation of exploratory items. A final network then predicts how to fuse both pair-wise and two-tower recommendations into a single ranking of items. We demonstrate that ContextGNN is able to adapt to different data characteristics and outperforms existing methods, both traditional and GNN-based, on a diverse set of practical recommendation tasks, improving performance by 20% on average.
RelBench: A Benchmark for Deep Learning on Relational Databases
Jul 29, 2024
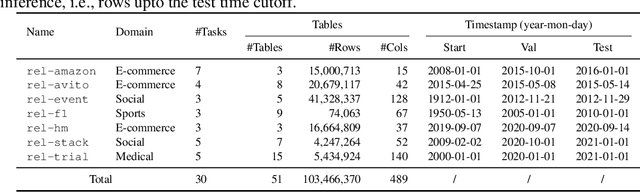


We present RelBench, a public benchmark for solving predictive tasks over relational databases with graph neural networks. RelBench provides databases and tasks spanning diverse domains and scales, and is intended to be a foundational infrastructure for future research. We use RelBench to conduct the first comprehensive study of Relational Deep Learning (RDL) (Fey et al., 2024), which combines graph neural network predictive models with (deep) tabular models that extract initial entity-level representations from raw tables. End-to-end learned RDL models fully exploit the predictive signal encoded in primary-foreign key links, marking a significant shift away from the dominant paradigm of manual feature engineering combined with tabular models. To thoroughly evaluate RDL against this prior gold-standard, we conduct an in-depth user study where an experienced data scientist manually engineers features for each task. In this study, RDL learns better models whilst reducing human work needed by more than an order of magnitude. This demonstrates the power of deep learning for solving predictive tasks over relational databases, opening up many new research opportunities enabled by RelBench.
PyTorch Frame: A Modular Framework for Multi-Modal Tabular Learning
Mar 31, 2024



We present PyTorch Frame, a PyTorch-based framework for deep learning over multi-modal tabular data. PyTorch Frame makes tabular deep learning easy by providing a PyTorch-based data structure to handle complex tabular data, introducing a model abstraction to enable modular implementation of tabular models, and allowing external foundation models to be incorporated to handle complex columns (e.g., LLMs for text columns). We demonstrate the usefulness of PyTorch Frame by implementing diverse tabular models in a modular way, successfully applying these models to complex multi-modal tabular data, and integrating our framework with PyTorch Geometric, a PyTorch library for Graph Neural Networks (GNNs), to perform end-to-end learning over relational databases.
From Similarity to Superiority: Channel Clustering for Time Series Forecasting
Mar 31, 2024

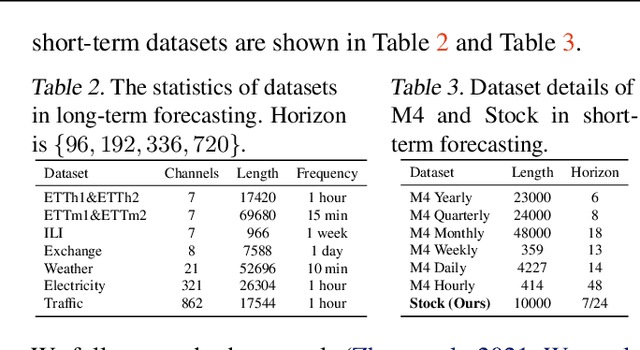

Time series forecasting has attracted significant attention in recent decades. Previous studies have demonstrated that the Channel-Independent (CI) strategy improves forecasting performance by treating different channels individually, while it leads to poor generalization on unseen instances and ignores potentially necessary interactions between channels. Conversely, the Channel-Dependent (CD) strategy mixes all channels with even irrelevant and indiscriminate information, which, however, results in oversmoothing issues and limits forecasting accuracy. There is a lack of channel strategy that effectively balances individual channel treatment for improved forecasting performance without overlooking essential interactions between channels. Motivated by our observation of a correlation between the time series model's performance boost against channel mixing and the intrinsic similarity on a pair of channels, we developed a novel and adaptable Channel Clustering Module (CCM). CCM dynamically groups channels characterized by intrinsic similarities and leverages cluster identity instead of channel identity, combining the best of CD and CI worlds. Extensive experiments on real-world datasets demonstrate that CCM can (1) boost the performance of CI and CD models by an average margin of 2.4% and 7.2% on long-term and short-term forecasting, respectively; (2) enable zero-shot forecasting with mainstream time series forecasting models; (3) uncover intrinsic time series patterns among channels and improve interpretability of complex time series models.
Relational Deep Learning: Graph Representation Learning on Relational Databases
Dec 07, 2023
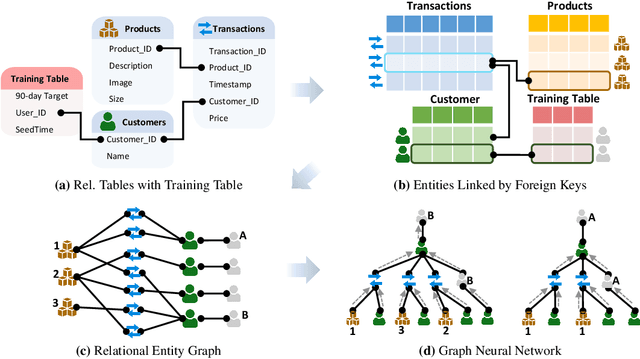


Much of the world's most valued data is stored in relational databases and data warehouses, where the data is organized into many tables connected by primary-foreign key relations. However, building machine learning models using this data is both challenging and time consuming. The core problem is that no machine learning method is capable of learning on multiple tables interconnected by primary-foreign key relations. Current methods can only learn from a single table, so the data must first be manually joined and aggregated into a single training table, the process known as feature engineering. Feature engineering is slow, error prone and leads to suboptimal models. Here we introduce an end-to-end deep representation learning approach to directly learn on data laid out across multiple tables. We name our approach Relational Deep Learning (RDL). The core idea is to view relational databases as a temporal, heterogeneous graph, with a node for each row in each table, and edges specified by primary-foreign key links. Message Passing Graph Neural Networks can then automatically learn across the graph to extract representations that leverage all input data, without any manual feature engineering. Relational Deep Learning leads to more accurate models that can be built much faster. To facilitate research in this area, we develop RelBench, a set of benchmark datasets and an implementation of Relational Deep Learning. The data covers a wide spectrum, from discussions on Stack Exchange to book reviews on the Amazon Product Catalog. Overall, we define a new research area that generalizes graph machine learning and broadens its applicability to a wide set of AI use cases.
Temporal Graph Benchmark for Machine Learning on Temporal Graphs
Jul 03, 2023



We present the Temporal Graph Benchmark (TGB), a collection of challenging and diverse benchmark datasets for realistic, reproducible, and robust evaluation of machine learning models on temporal graphs. TGB datasets are of large scale, spanning years in duration, incorporate both node and edge-level prediction tasks and cover a diverse set of domains including social, trade, transaction, and transportation networks. For both tasks, we design evaluation protocols based on realistic use-cases. We extensively benchmark each dataset and find that the performance of common models can vary drastically across datasets. In addition, on dynamic node property prediction tasks, we show that simple methods often achieve superior performance compared to existing temporal graph models. We believe that these findings open up opportunities for future research on temporal graphs. Finally, TGB provides an automated machine learning pipeline for reproducible and accessible temporal graph research, including data loading, experiment setup and performance evaluation. TGB will be maintained and updated on a regular basis and welcomes community feedback. TGB datasets, data loaders, example codes, evaluation setup, and leaderboards are publicly available at https://tgb.complexdatalab.com/ .