 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvaTaR: Optimizing LLM Agents for Tool-Assisted Knowledge Retrieval
Jun 18, 2024



Large language model (LLM) agents have demonstrated impressive capability in utilizing external tools and knowledge to boost accuracy and reduce hallucinations. However, developing the prompting techniques that make LLM agents able to effectively use external tools and knowledge is a heuristic and laborious task. Here, we introduce AvaTaR, a novel and automatic framework that optimizes an LLM agent to effectively use the provided tools and improve its performance on a given task/domain. During optimization, we design a comparator module to iteratively provide insightful and holistic prompts to the LLM agent via reasoning between positive and negative examples sampled from training data. We demonstrate AvaTaR on four complex multimodal retrieval datasets featuring textual, visual, and relational information. We find AvaTaR consistently outperforms state-of-the-art approaches across all four challenging tasks and exhibits strong generalization ability when applied to novel cases, achieving an average relative improvement of 14% on the Hit@1 metric. Code and dataset are available at https://github.com/zou-group/avatar.
STaRK: Benchmarking LLM Retrieval on Textual and Relational Knowledge Bases
Apr 19, 2024



Answering real-world user queries, such as product search, often requires accurate retrieval of information from semi-structured knowledge bases or databases that involve blend of unstructured (e.g., textual descriptions of products) and structured (e.g., entity relations of products) information. However, previous works have mostly studied textual and relational retrieval tasks as separate topics. To address the gap, we develop STARK, a large-scale Semi-structure retrieval benchmark on Textual and Relational Knowledge Bases. We design a novel pipeline to synthesize natural and realistic user queries that integrate diverse relational information and complex textual properties, as well as their ground-truth answers. Moreover, we rigorously conduct human evaluation to validate the quality of our benchmark, which covers a variety of practical applications, including product recommendations, academic paper searches, and precision medicine inquiries. Our benchmark serves as a comprehensive testbed for evaluating the performance of retrieval systems, with an emphasis on retrieval approaches driven by large language models (LLMs). Our experiments suggest that the STARK datasets present significant challenges to the current retrieval and LLM systems, indicating the demand for building more capable retrieval systems that can handle both textual and relational aspects.
PyTorch Frame: A Modular Framework for Multi-Modal Tabular Learning
Mar 31, 2024



We present PyTorch Frame, a PyTorch-based framework for deep learning over multi-modal tabular data. PyTorch Frame makes tabular deep learning easy by providing a PyTorch-based data structure to handle complex tabular data, introducing a model abstraction to enable modular implementation of tabular models, and allowing external foundation models to be incorporated to handle complex columns (e.g., LLMs for text columns). We demonstrate the usefulness of PyTorch Frame by implementing diverse tabular models in a modular way, successfully applying these models to complex multi-modal tabular data, and integrating our framework with PyTorch Geometric, a PyTorch library for Graph Neural Networks (GNNs), to perform end-to-end learning over relational databases.
GraphMETRO: Mitigating Complex Distribution Shifts in GNNs via Mixture of Aligned Experts
Dec 07, 2023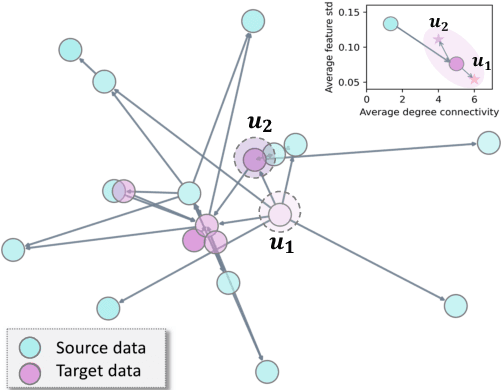
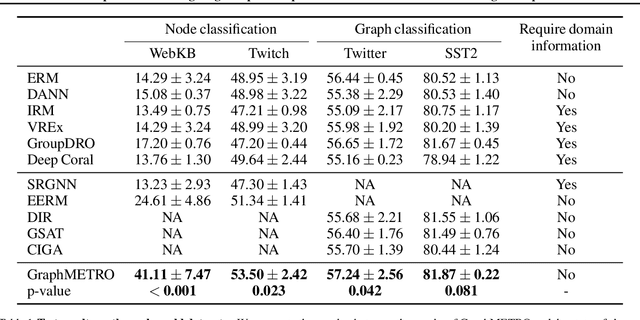
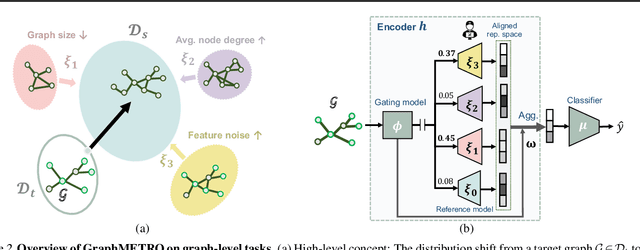
Graph Neural Networks' (GNNs) ability to generalize across complex distributions is crucial for real-world applications. However, prior research has primarily focused on specific types of distribution shifts, such as larger graph size, or inferred shifts from constructed data environments, which is highly limited when confronted with multiple and nuanced distribution shifts. For instance, in a social graph, a user node might experience increased interactions and content alterations, while other user nodes encounter distinct shifts. Neglecting such complexities significantly impedes generalization. To address it, we present GraphMETRO, a novel framework that enhances GNN generalization under complex distribution shifts in both node and graph-level tasks. Our approach employs a mixture-of-experts (MoE) architecture with a gating model and expert models aligned in a shared representation space. The gating model identifies key mixture components governing distribution shifts, while each expert generates invariant representations w.r.t. a mixture component. Finally, GraphMETRO aggregates representations from multiple experts to generate the final invariant representation. Our experiments on synthetic and realworld datasets demonstrate GraphMETRO's superiority and interpretability. To highlight, GraphMETRO achieves state-of-the-art performances on four real-world datasets from GOOD benchmark, outperforming the best baselines on WebKB and Twitch datasets by 67% and 4.2%, respectively.
TpuGraphs: A Performance Prediction Dataset on Large Tensor Computational Graphs
Aug 25, 2023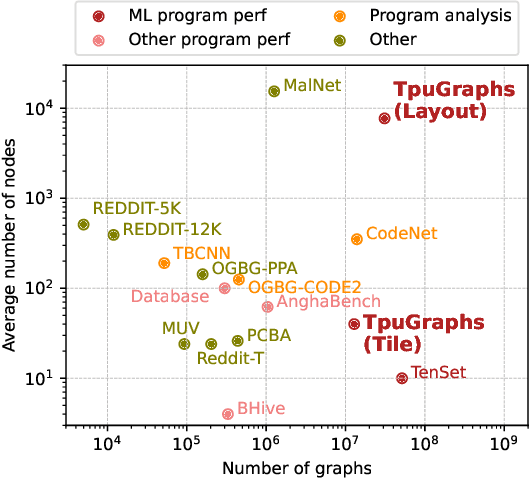

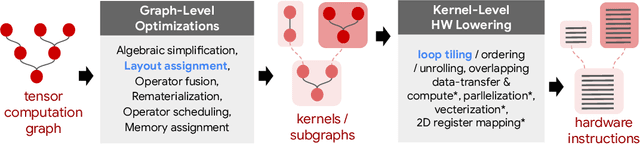
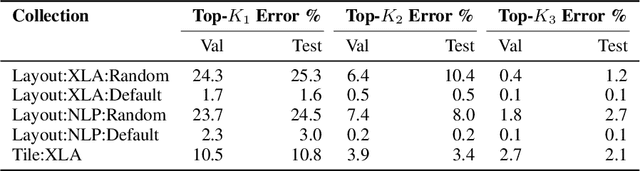
Precise hardware performance models play a crucial role in code optimizations. They can assist compilers in making heuristic decisions or aid autotuners in identifying the optimal configuration for a given program. For example, the autotuner for XLA, a machine learning compiler, discovered 10-20% speedup on state-of-the-art models serving substantial production traffic at Google. Although there exist a few datasets for program performance prediction, they target small sub-programs such as basic blocks or kernels. This paper introduces TpuGraphs, a performance prediction dataset on full tensor programs, represented as computational graphs, running on Tensor Processing Units (TPUs). Each graph in the dataset represents the main computation of a machine learning workload, e.g., a training epoch or an inference step. Each data sample contains a computational graph, a compilation configuration, and the execution time of the graph when compiled with the configuration. The graphs in the dataset are collected from open-source machine learning programs, featuring popular model architectures, e.g., ResNet, EfficientNet, Mask R-CNN, and Transformer. TpuGraphs provides 25x more graphs than the largest graph property prediction dataset (with comparable graph sizes), and 770x larger graphs on average compared to existing performance prediction datasets on machine learning programs. This graph-level prediction task on large graphs introduces new challenges in learning, ranging from scalability, training efficiency, to model quality.
Communication-Free Distributed GNN Training with Vertex Cut
Aug 06, 2023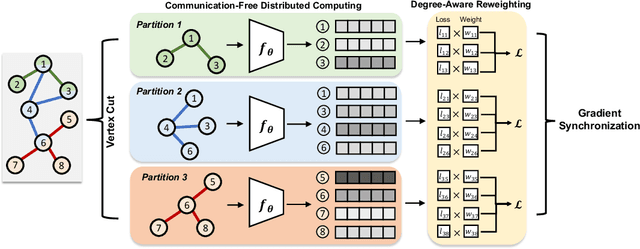
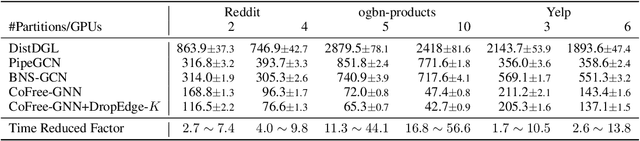
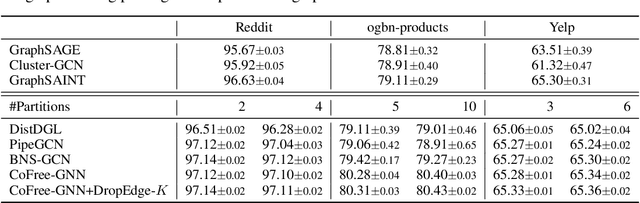

Training Graph Neural Networks (GNNs) on real-world graphs consisting of billions of nodes and edges is quite challenging, primarily due to the substantial memory needed to store the graph and its intermediate node and edge features, and there is a pressing need to speed up the training process. A common approach to achieve speed up is to divide the graph into many smaller subgraphs, which are then distributed across multiple GPUs in one or more machines and processed in parallel. However, existing distributed methods require frequent and substantial cross-GPU communication, leading to significant time overhead and progressively diminishing scalability. Here, we introduce CoFree-GNN, a novel distributed GNN training framework that significantly speeds up the training process by implementing communication-free training. The framework utilizes a Vertex Cut partitioning, i.e., rather than partitioning the graph by cutting the edges between partitions, the Vertex Cut partitions the edges and duplicates the node information to preserve the graph structure. Furthermore, the framework maintains high model accuracy by incorporating a reweighting mechanism to handle a distorted graph distribution that arises from the duplicated nodes. We also propose a modified DropEdge technique to further speed up the training process. Using an extensive set of experiments on real-world networks, we demonstrate that CoFree-GNN speeds up the GNN training process by up to 10 times over the existing state-of-the-art GNN training approaches.
Learning Large Graph Property Prediction via Graph Segment Training
May 21, 2023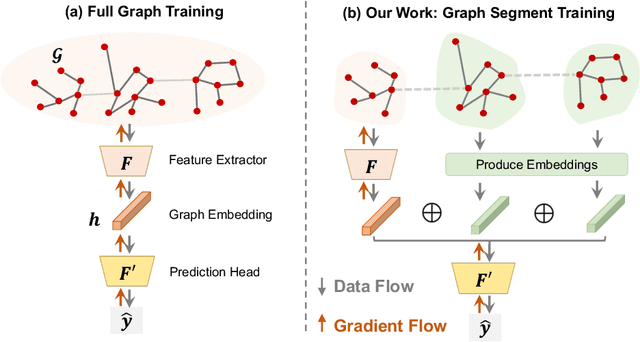
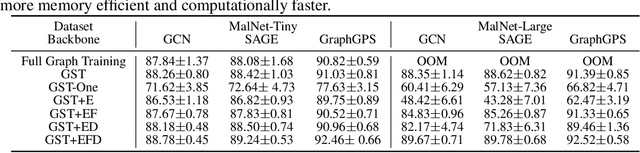

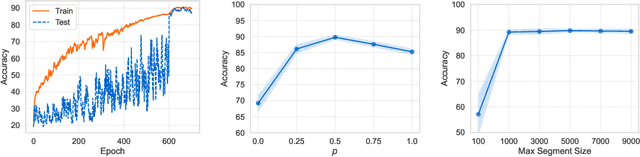
Learning to predict properties of large graphs is challenging because each prediction requires the knowledge of an entire graph, while the amount of memory available during training is bounded. Here we propose Graph Segment Training (GST), a general framework that utilizes a divide-and-conquer approach to allow learning large graph property prediction with a constant memory footprint. GST first divides a large graph into segments and then backpropagates through only a few segments sampled per training iteration. We refine the GST paradigm by introducing a historical embedding table to efficiently obtain embeddings for segments not sampled for backpropagation. To mitigate the staleness of historical embeddings, we design two novel techniques. First, we finetune the prediction head to fix the input distribution shift. Second, we introduce Stale Embedding Dropout to drop some stale embeddings during training to reduce bias. We evaluate our complete method GST-EFD (with all the techniques together) on two large graph property prediction benchmarks: MalNet and TpuGraphs. Our experiments show that GST-EFD is both memory-efficient and fast, while offering a slight boost on test accuracy over a typical full graph training regime.
Relational Multi-Task Learning: Modeling Relations between Data and Tasks
Mar 14, 2023



A key assumption in multi-task learning is that at the inference time the multi-task model only has access to a given data point but not to the data point's labels from other tasks. This presents an opportunity to extend multi-task learning to utilize data point's labels from other auxiliary tasks, and this way improves performance on the new task. Here we introduce a novel relational multi-task learning setting where we leverage data point labels from auxiliary tasks to make more accurate predictions on the new task. We develop MetaLink, where our key innovation is to build a knowledge graph that connects data points and tasks and thus allows us to leverage labels from auxiliary tasks. The knowledge graph consists of two types of nodes: (1) data nodes, where node features are data embeddings computed by the neural network, and (2) task nodes, with the last layer's weights for each task as node features. The edges in this knowledge graph capture data-task relationships, and the edge label captures the label of a data point on a particular task. Under MetaLink, we reformulate the new task as a link label prediction problem between a data node and a task node. The MetaLink framework provides flexibility to model knowledge transfer from auxiliary task labels to the task of interest. We evaluate MetaLink on 6 benchmark datasets in both biochemical and vision domains. Experiments demonstrate that MetaLink can successfully utilize the relations among different tasks, outperforming the state-of-the-art methods under the proposed relational multi-task learning setting, with up to 27% improvement in ROC AUC.
AutoTransfer: AutoML with Knowledge Transfer -- An Application to Graph Neural Networks
Mar 14, 2023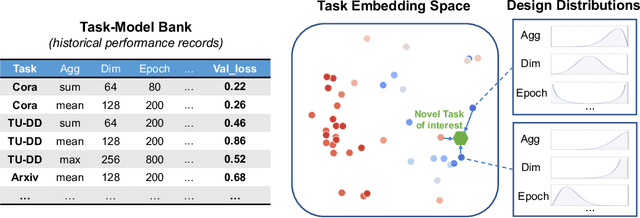
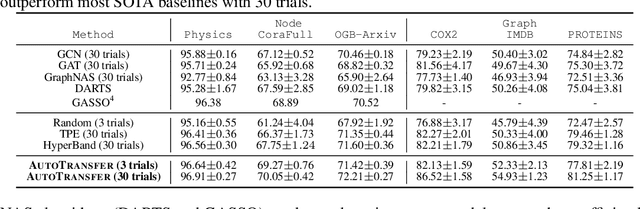


AutoML has demonstrated remarkable success in finding an effective neural architecture for a given machine learning task defined by a specific dataset and an evaluation metric. However, most present AutoML techniques consider each task independently from scratch, which requires exploring many architectures, leading to high computational cost. Here we propose AutoTransfer, an AutoML solution that improves search efficiency by transferring the prior architectural design knowledge to the novel task of interest. Our key innovation includes a task-model bank that captures the model performance over a diverse set of GNN architectures and tasks, and a computationally efficient task embedding that can accurately measure the similarity among different tasks. Based on the task-model bank and the task embeddings, we estimate the design priors of desirable models of the novel task, by aggregating a similarity-weighted sum of the top-K design distributions on tasks that are similar to the task of interest. The computed design priors can be used with any AutoML search algorithm. We evaluate AutoTransfer on six datasets in the graph machine learning domain. Experiments demonstrate that (i) our proposed task embedding can be computed efficiently, and that tasks with similar embeddings have similar best-performing architectures; (ii) AutoTransfer significantly improves search efficiency with the transferred design priors, reducing the number of explored architectures by an order of magnitude. Finally, we release GNN-Bank-101, a large-scale dataset of detailed GNN training information of 120,000 task-model combinations to facilitate and inspire future research.
TuneUp: A Training Strategy for Improving Generalization of Graph Neural Networks
Oct 26, 2022



Despite many advances in Graph Neural Networks (GNNs), their training strategies simply focus on minimizing a loss over nodes in a graph. However, such simplistic training strategies may be sub-optimal as they neglect that certain nodes are much harder to make accurate predictions on than others. Here we present TuneUp, a curriculum learning strategy for better training GNNs. Crucially, TuneUp trains a GNN in two stages. The first stage aims to produce a strong base GNN. Such base GNNs tend to perform well on head nodes (nodes with large degrees) but less so on tail nodes (nodes with small degrees). So, the second stage of TuneUp specifically focuses on improving prediction on tail nodes. Concretely, TuneUp synthesizes many additional supervised tail node data by dropping edges from head nodes and reusing the supervision on the original head nodes. TuneUp then minimizes the loss over the synthetic tail nodes to finetune the base GNN. TuneUp is a general training strategy that can be used with any GNN architecture and any loss, making TuneUp applicable to a wide range of prediction tasks. Extensive evaluation of TuneUp on two GNN architectures, three types of prediction tasks, and both inductive and transductive settings shows that TuneUp significantly improves the performance of the base GNN on tail nodes, while often even improving the performance on head nodes, which together leads up to 58.5% relative improvement in GNN predictive performance. Moreover, TuneUp significantly outperforms its variants without the two-stage curriculum learning, existing graph data augmentation techniques, as well as other specialized methods for tail nodes.