 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKumoRFM-2: Scaling Foundation Models for Relational Learning
Apr 14, 2026We introduce KumoRFM-2, the next iteration of a pre-trained foundation model for relational data. KumoRFM-2 supports in-context learning as well as fine-tuning and is applicable to a wide range of predictive tasks. In contrast to tabular foundation models, KumoRFM-2 natively operates on relational data, processing one or more connected tables simultaneously without manual table flattening or target variable generation, all while preserving temporal consistency. KumoRFM-2 leverages a large corpus of synthetic and real-world data to pre-train across four axes: the row and column dimensions at the individual table level, and the foreign key and cross-sample dimensions at the database level. In contrast to its predecessor, KumoRFM-2 injects task information as early as possible, enabling sharper selection of task-relevant columns and improved robustness to noisy data. Through extensive experiments on 41 challenging benchmarks and analysis around expressivity and sensitivity, we demonstrate that KumoRFM-2 outperforms supervised and foundational approaches by up to 8%, while maintaining strong performance under extreme settings of cold start and noisy data. To our knowledge, this is the first time a few-shot foundation model has been shown to surpass supervised approaches on common benchmark tasks, with performance further improving upon fine-tuning. Finally, while KumoRFM-1 was limited to small-scale in-memory datasets, KumoRFM-2 scales to billion-scale relational datasets.
Predictive Query Language: A Domain-Specific Language for Predictive Modeling on Relational Databases
Feb 16, 2026The purpose of predictive modeling on relational data is to predict future or missing values in a relational database, for example, future purchases of a user, risk of readmission of the patient, or the likelihood that a financial transaction is fraudulent. Typically powered by machine learning methods, predictive models are used in recommendations, financial fraud detection, supply chain optimization, and other systems, providing billions of predictions every day. However, training a machine learning model requires manual work to extract the required training examples - prediction entities and target labels - from the database, which is slow, laborious, and prone to mistakes. Here, we present the Predictive Query Language (PQL), an SQL-inspired declarative language for defining predictive tasks on relational databases. PQL allows specifying a predictive task in a single declarative query, enabling the automatic computation of training labels for a large variety of machine learning tasks, such as regression, classification, time-series forecasting, and recommender systems. PQL is already successfully integrated and used in a collection of use cases as part of a predictive AI platform. The versatility of the language can be demonstrated through its many ongoing use cases, including financial fraud, item recommendations, and workload prediction. We demonstrate its versatile design through two implementations; one for small-scale, low-latency use and one that can handle large-scale databases.
PyG 2.0: Scalable Learning on Real World Graphs
Jul 22, 2025PyG (PyTorch Geometric) has evolved significantly since its initial release, establishing itself as a leading framework for Graph Neural Networks. In this paper, we present Pyg 2.0 (and its subsequent minor versions), a comprehensive update that introduces substantial improvements in scalability and real-world application capabilities. We detail the framework's enhanced architecture, including support for heterogeneous and temporal graphs, scalable feature/graph stores, and various optimizations, enabling researchers and practitioners to tackle large-scale graph learning problems efficiently. Over the recent years, PyG has been supporting graph learning in a large variety of application areas, which we will summarize, while providing a deep dive into the important areas of relational deep learning and large language modeling.
PyTorch Frame: A Modular Framework for Multi-Modal Tabular Learning
Mar 31, 2024



We present PyTorch Frame, a PyTorch-based framework for deep learning over multi-modal tabular data. PyTorch Frame makes tabular deep learning easy by providing a PyTorch-based data structure to handle complex tabular data, introducing a model abstraction to enable modular implementation of tabular models, and allowing external foundation models to be incorporated to handle complex columns (e.g., LLMs for text columns). We demonstrate the usefulness of PyTorch Frame by implementing diverse tabular models in a modular way, successfully applying these models to complex multi-modal tabular data, and integrating our framework with PyTorch Geometric, a PyTorch library for Graph Neural Networks (GNNs), to perform end-to-end learning over relational databases.
Pre-training and Diagnosing Knowledge Base Completion Models
Jan 27, 2024



In this work, we introduce and analyze an approach to knowledge transfer from one collection of facts to another without the need for entity or relation matching. The method works for both canonicalized knowledge bases and uncanonicalized or open knowledge bases, i.e., knowledge bases where more than one copy of a real-world entity or relation may exist. The main contribution is a method that can make use of large-scale pre-training on facts, which were collected from unstructured text, to improve predictions on structured data from a specific domain. The introduced method is most impactful on small datasets such as ReVerb20k, where a 6% absolute increase of mean reciprocal rank and 65% relative decrease of mean rank over the previously best method was achieved, despite not relying on large pre-trained models like Bert. To understand the obtained pre-trained models better, we then introduce a novel dataset for the analysis of pre-trained models for Open Knowledge Base Completion, called Doge (Diagnostics of Open knowledge Graph Embeddings). It consists of 6 subsets and is designed to measure multiple properties of a pre-trained model: robustness against synonyms, ability to perform deductive reasoning, presence of gender stereotypes, consistency with reverse relations, and coverage of different areas of general knowledge. Using the introduced dataset, we show that the existing OKBC models lack consistency in the presence of synonyms and inverse relations and are unable to perform deductive reasoning. Moreover, their predictions often align with gender stereotypes, which persist even when presented with counterevidence. We additionally investigate the role of pre-trained word embeddings and demonstrate that avoiding biased word embeddings is not a sufficient measure to prevent biased behavior of OKBC models.
Counter-GAP: Counterfactual Bias Evaluation through Gendered Ambiguous Pronouns
Feb 11, 2023



Bias-measuring datasets play a critical role in detecting biased behavior of language models and in evaluating progress of bias mitigation methods. In this work, we focus on evaluating gender bias through coreference resolution, where previous datasets are either hand-crafted or fail to reliably measure an explicitly defined bias. To overcome these shortcomings, we propose a novel method to collect diverse, natural, and minimally distant text pairs via counterfactual generation, and construct Counter-GAP, an annotated dataset consisting of 4008 instances grouped into 1002 quadruples. We further identify a bias cancellation problem in previous group-level metrics on Counter-GAP, and propose to use the difference between inconsistency across genders and within genders to measure bias at a quadruple level. Our results show that four pre-trained language models are significantly more inconsistent across different gender groups than within each group, and that a name-based counterfactual data augmentation method is more effective to mitigate such bias than an anonymization-based method.
The Defeat of the Winograd Schema Challenge
Jan 16, 2022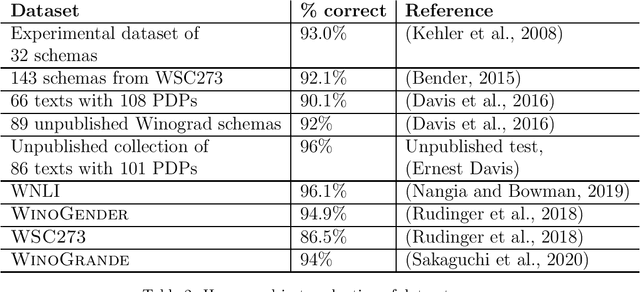

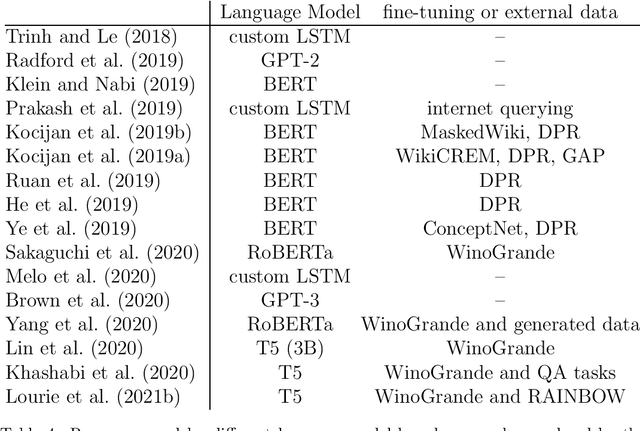
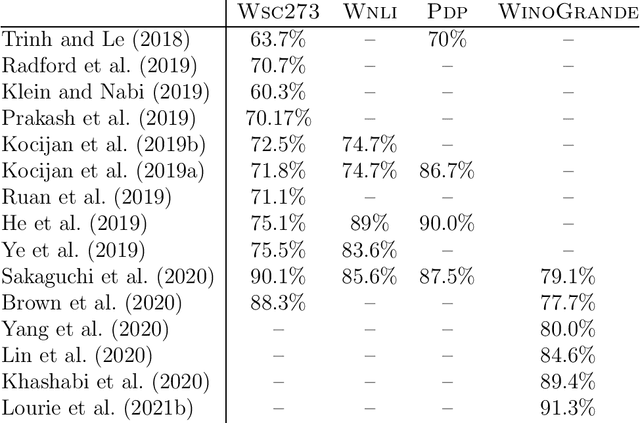
The Winograd Schema Challenge -- a set of twin sentences involving pronoun reference disambiguation that seem to require the use of commonsense knowledge -- was proposed by Hector Levesque in 2011. By 2019, a number of AI systems, based on large pre-trained transformer-based language models and fine-tuned on these kinds of problems, achieved better than 90% accuracy. In this paper, we review the history of the Winograd Schema Challenge and assess its significance.
Few-Shot Out-of-Domain Transfer Learning of Natural Language Explanations
Dec 12, 2021
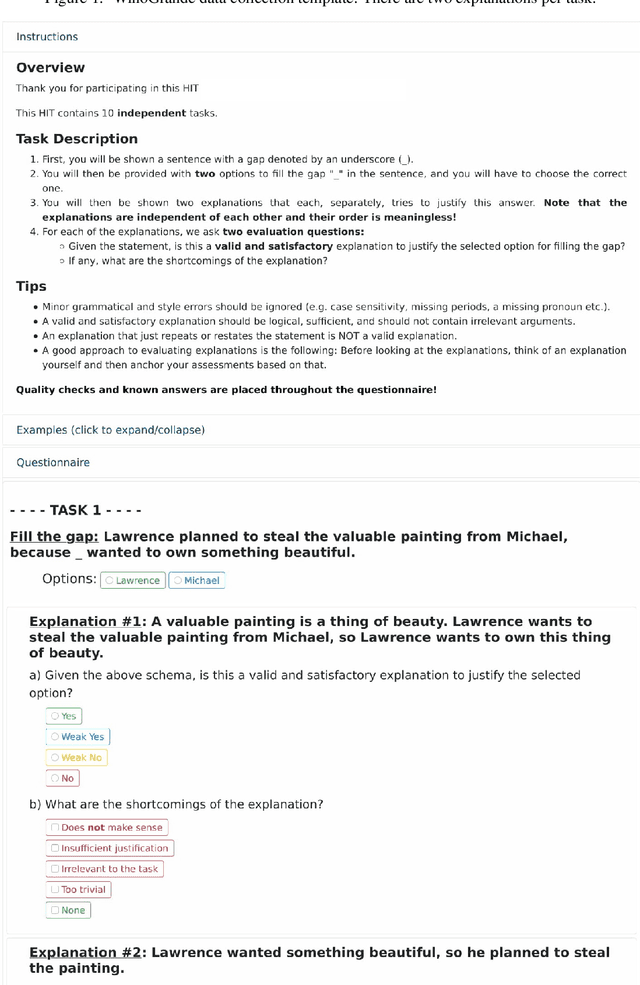

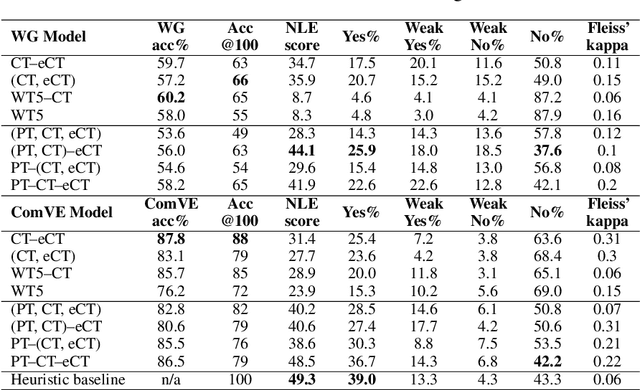
Recently, there has been an increasing interest in models that generate natural language explanations (NLEs) for their decisions. However, training a model to provide NLEs requires the acquisition of task-specific NLEs, which is time- and resource-consuming. A potential solution is the out-of-domain transfer of NLEs from a domain with a large number of NLEs to a domain with scarce NLEs but potentially a large number of labels, via few-shot transfer learning. In this work, we introduce three vanilla approaches for few-shot transfer learning of NLEs for the case of few NLEs but abundant labels, along with an adaptation of an existing vanilla fine-tuning approach. We transfer explainability from the natural language inference domain, where a large dataset of human-written NLEs exists (e-SNLI), to the domains of (1) hard cases of pronoun resolution, where we introduce a small dataset of NLEs on top of the WinoGrande dataset (small-e-WinoGrande), and (2) commonsense validation (ComVE). Our results demonstrate that the transfer of NLEs outperforms the single-task methods, and establish the best strategies out of the four identified training regimes. We also investigate the scalability of the best methods, both in terms of training data and model size.
Knowledge Base Completion Meets Transfer Learning
Aug 30, 2021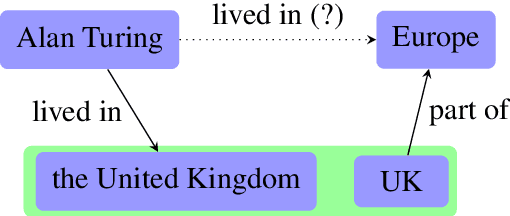

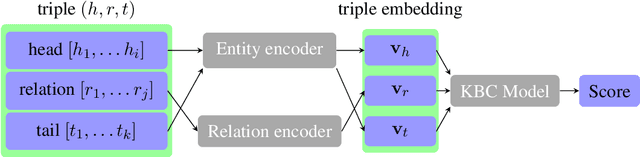
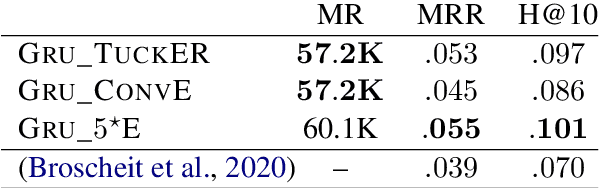
The aim of knowledge base completion is to predict unseen facts from existing facts in knowledge bases. In this work, we introduce the first approach for transfer of knowledge from one collection of facts to another without the need for entity or relation matching. The method works for both canonicalized knowledge bases and uncanonicalized or open knowledge bases, i.e., knowledge bases where more than one copy of a real-world entity or relation may exist. Such knowledge bases are a natural output of automated information extraction tools that extract structured data from unstructured text. Our main contribution is a method that can make use of a large-scale pre-training on facts, collected from unstructured text, to improve predictions on structured data from a specific domain. The introduced method is the most impactful on small datasets such as ReVerb20K, where we obtained 6% absolute increase of mean reciprocal rank and 65% relative decrease of mean rank over the previously best method, despite not relying on large pre-trained models like BERT.
* Presented at EMNLP 2021
The Gap on GAP: Tackling the Problem of Differing Data Distributions in Bias-Measuring Datasets
Nov 12, 2020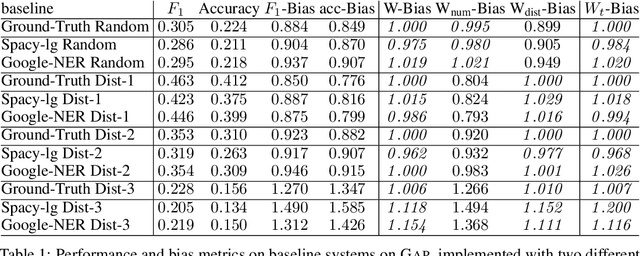
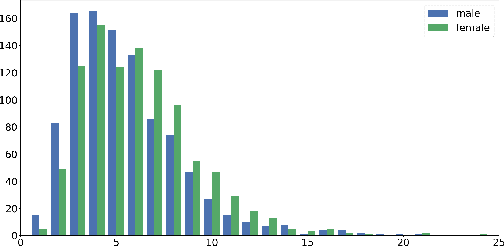
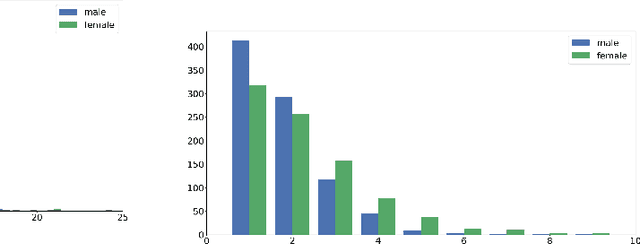
Diagnostic datasets that can detect biased models are an important prerequisite for bias reduction within natural language processing. However, undesired patterns in the collected data can make such tests incorrect. For example, if the feminine subset of a gender-bias-measuring coreference resolution dataset contains sentences with a longer average distance between the pronoun and the correct candidate, an RNN-based model may perform worse on this subset due to long-term dependencies. In this work, we introduce a theoretically grounded method for weighting test samples to cope with such patterns in the test data. We demonstrate the method on the GAP dataset for coreference resolution. We annotate GAP with spans of all personal names and show that examples in the female subset contain more personal names and a longer distance between pronouns and their referents, potentially affecting the bias score in an undesired way. Using our weighting method, we find the set of weights on the test instances that should be used for coping with these correlations, and we re-evaluate 16 recently released coreference models.