 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndustry-Aligned Granular Topic Modeling
Jan 16, 2026Topic modeling has extensive applications in text mining and data analysis across various industrial sectors. Although the concept of granularity holds significant value for business applications by providing deeper insights, the capability of topic modeling methods to produce granular topics has not been thoroughly explored. In this context, this paper introduces a framework called TIDE, which primarily provides a novel granular topic modeling method based on large language models (LLMs) as a core feature, along with other useful functionalities for business applications, such as summarizing long documents, topic parenting, and distillation. Through extensive experiments on a variety of public and real-world business datasets, we demonstrate that TIDE's topic modeling approach outperforms modern topic modeling methods, and our auxiliary components provide valuable support for dealing with industrial business scenarios. The TIDE framework is currently undergoing the process of being open sourced.
Pre-training and Diagnosing Knowledge Base Completion Models
Jan 27, 2024



In this work, we introduce and analyze an approach to knowledge transfer from one collection of facts to another without the need for entity or relation matching. The method works for both canonicalized knowledge bases and uncanonicalized or open knowledge bases, i.e., knowledge bases where more than one copy of a real-world entity or relation may exist. The main contribution is a method that can make use of large-scale pre-training on facts, which were collected from unstructured text, to improve predictions on structured data from a specific domain. The introduced method is most impactful on small datasets such as ReVerb20k, where a 6% absolute increase of mean reciprocal rank and 65% relative decrease of mean rank over the previously best method was achieved, despite not relying on large pre-trained models like Bert. To understand the obtained pre-trained models better, we then introduce a novel dataset for the analysis of pre-trained models for Open Knowledge Base Completion, called Doge (Diagnostics of Open knowledge Graph Embeddings). It consists of 6 subsets and is designed to measure multiple properties of a pre-trained model: robustness against synonyms, ability to perform deductive reasoning, presence of gender stereotypes, consistency with reverse relations, and coverage of different areas of general knowledge. Using the introduced dataset, we show that the existing OKBC models lack consistency in the presence of synonyms and inverse relations and are unable to perform deductive reasoning. Moreover, their predictions often align with gender stereotypes, which persist even when presented with counterevidence. We additionally investigate the role of pre-trained word embeddings and demonstrate that avoiding biased word embeddings is not a sufficient measure to prevent biased behavior of OKBC models.
Improving Language Models Meaning Understanding and Consistency by Learning Conceptual Roles from Dictionary
Oct 24, 2023

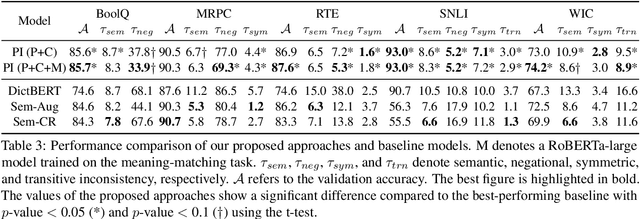

The non-humanlike behaviour of contemporary pre-trained language models (PLMs) is a leading cause undermining their trustworthiness. A striking phenomenon of such faulty behaviours is the generation of inconsistent predictions, which produces logically contradictory results, such as generating different predictions for texts delivering the same meaning or violating logical properties. Previous studies exploited data augmentation or implemented specialised loss functions to alleviate the issue. However, their usage is limited, because they consume expensive training resources for large-sized PLMs and can only handle a certain consistency type. To this end, we propose a practical approach that alleviates the inconsistent behaviour issue by fundamentally improving PLMs' meaning awareness. Based on the conceptual role theory, our method allows PLMs to capture accurate meaning by learning precise interrelationships between concepts from word-definition pairs in a dictionary. Next, we propose an efficient parameter integration technique that updates only a few additional parameters to combine the learned interrelationship with PLMs' pre-trained knowledge. Our experimental results reveal that the approach can concurrently improve multiple types of consistency, enables efficient knowledge integration, and easily applies to other languages.
* 15 pages