 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiases in the Blind Spot: Detecting What LLMs Fail to Mention
Feb 11, 2026Large Language Models (LLMs) often provide chain-of-thought (CoT) reasoning traces that appear plausible, but may hide internal biases. We call these *unverbalized biases*. Monitoring models via their stated reasoning is therefore unreliable, and existing bias evaluations typically require predefined categories and hand-crafted datasets. In this work, we introduce a fully automated, black-box pipeline for detecting task-specific unverbalized biases. Given a task dataset, the pipeline uses LLM autoraters to generate candidate bias concepts. It then tests each concept on progressively larger input samples by generating positive and negative variations, and applies statistical techniques for multiple testing and early stopping. A concept is flagged as an unverbalized bias if it yields statistically significant performance differences while not being cited as justification in the model's CoTs. We evaluate our pipeline across six LLMs on three decision tasks (hiring, loan approval, and university admissions). Our technique automatically discovers previously unknown biases in these models (e.g., Spanish fluency, English proficiency, writing formality). In the same run, the pipeline also validates biases that were manually identified by prior work (gender, race, religion, ethnicity). More broadly, our proposed approach provides a practical, scalable path to automatic task-specific bias discovery.
Faithfulness of LLM Self-Explanations for Commonsense Tasks: Larger Is Better, and Instruction-Tuning Allows Trade-Offs but Not Pareto Dominance
Mar 17, 2025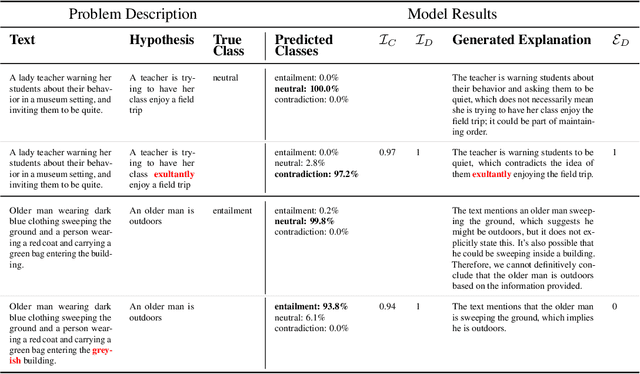
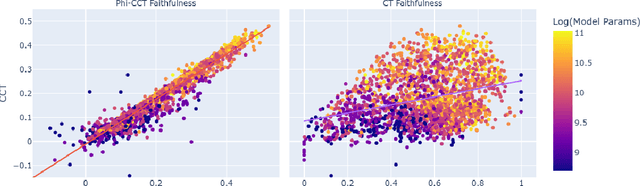
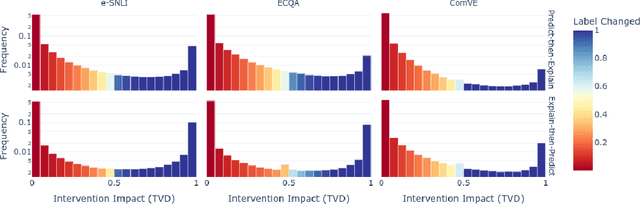
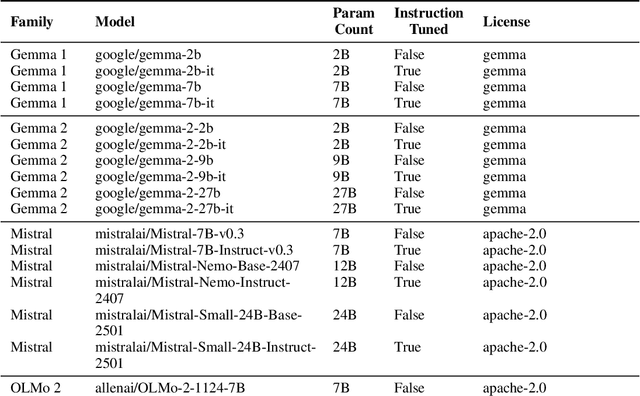
As large language models (LLMs) become increasingly capable, ensuring that their self-generated explanations are faithful to their internal decision-making process is critical for safety and oversight. In this work, we conduct a comprehensive counterfactual faithfulness analysis across 62 models from 8 families, encompassing both pretrained and instruction-tuned variants and significantly extending prior studies of counterfactual tests. We introduce phi-CCT, a simplified variant of the Correlational Counterfactual Test, which avoids the need for token probabilities while explaining most of the variance of the original test. Our findings reveal clear scaling trends: larger models are consistently more faithful on our metrics. However, when comparing instruction-tuned and human-imitated explanations, we find that observed differences in faithfulness can often be attributed to explanation verbosity, leading to shifts along the true-positive/false-positive Pareto frontier. While instruction-tuning and prompting can influence this trade-off, we find limited evidence that they fundamentally expand the frontier of explanatory faithfulness beyond what is achievable with pretrained models of comparable size. Our analysis highlights the nuanced relationship between instruction-tuning, verbosity, and the faithful representation of model decision processes.
Fool Me Once? Contrasting Textual and Visual Explanations in a Clinical Decision-Support Setting
Oct 16, 2024



The growing capabilities of AI models are leading to their wider use, including in safety-critical domains. Explainable AI (XAI) aims to make these models safer to use by making their inference process more transparent. However, current explainability methods are seldom evaluated in the way they are intended to be used: by real-world end users. To address this, we conducted a large-scale user study with 85 healthcare practitioners in the context of human-AI collaborative chest X-ray analysis. We evaluated three types of explanations: visual explanations (saliency maps), natural language explanations, and a combination of both modalities. We specifically examined how different explanation types influence users depending on whether the AI advice and explanations are factually correct. We find that text-based explanations lead to significant over-reliance, which is alleviated by combining them with saliency maps. We also observe that the quality of explanations, that is, how much factually correct information they entail, and how much this aligns with AI correctness, significantly impacts the usefulness of the different explanation types.
From Explanations to Action: A Zero-Shot, Theory-Driven LLM Framework for Student Performance Feedback
Sep 12, 2024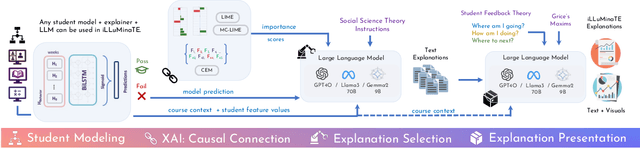
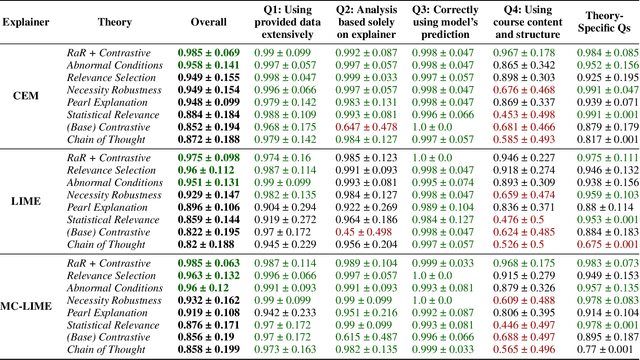
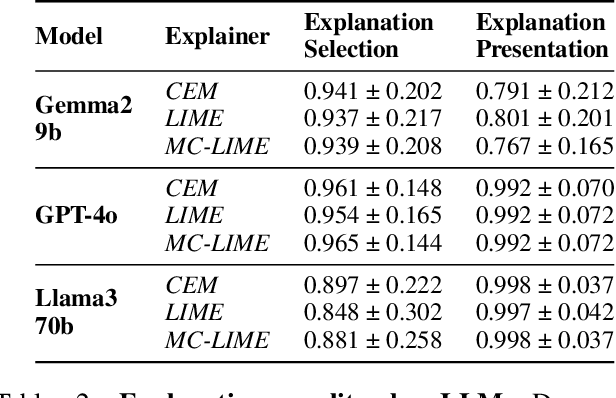
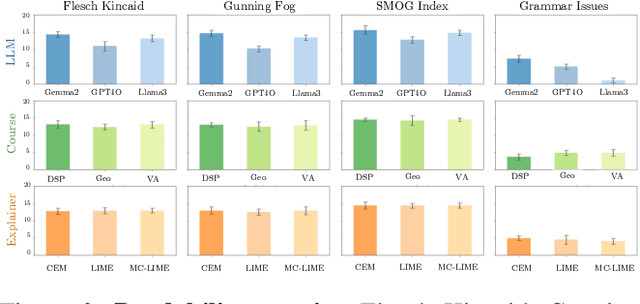
Recent advances in eXplainable AI (XAI) for education have highlighted a critical challenge: ensuring that explanations for state-of-the-art AI models are understandable for non-technical users such as educators and students. In response, we introduce iLLuMinaTE, a zero-shot, chain-of-prompts LLM-XAI pipeline inspired by Miller's cognitive model of explanation. iLLuMinaTE is designed to deliver theory-driven, actionable feedback to students in online courses. iLLuMinaTE navigates three main stages - causal connection, explanation selection, and explanation presentation - with variations drawing from eight social science theories (e.g. Abnormal Conditions, Pearl's Model of Explanation, Necessity and Robustness Selection, Contrastive Explanation). We extensively evaluate 21,915 natural language explanations of iLLuMinaTE extracted from three LLMs (GPT-4o, Gemma2-9B, Llama3-70B), with three different underlying XAI methods (LIME, Counterfactuals, MC-LIME), across students from three diverse online courses. Our evaluation involves analyses of explanation alignment to the social science theory, understandability of the explanation, and a real-world user preference study with 114 university students containing a novel actionability simulation. We find that students prefer iLLuMinaTE explanations over traditional explainers 89.52% of the time. Our work provides a robust, ready-to-use framework for effectively communicating hybrid XAI-driven insights in education, with significant generalization potential for other human-centric fields.
The Probabilities Also Matter: A More Faithful Metric for Faithfulness of Free-Text Explanations in Large Language Models
Apr 04, 2024



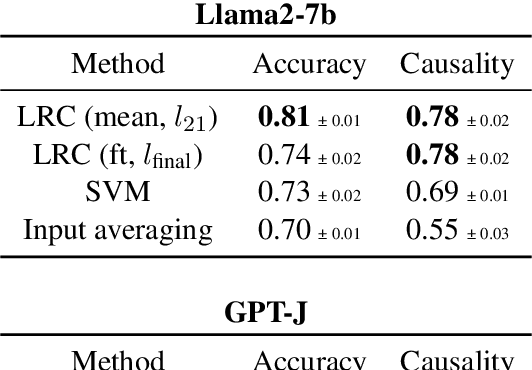
In order to oversee advanced AI systems, it is important to understand their underlying decision-making process. When prompted, large language models (LLMs) can provide natural language explanations or reasoning traces that sound plausible and receive high ratings from human annotators. However, it is unclear to what extent these explanations are faithful, i.e., truly capture the factors responsible for the model's predictions. In this work, we introduce Correlational Explanatory Faithfulness (CEF), a metric that can be used in faithfulness tests based on input interventions. Previous metrics used in such tests take into account only binary changes in the predictions. Our metric accounts for the total shift in the model's predicted label distribution, more accurately reflecting the explanations' faithfulness. We then introduce the Correlational Counterfactual Test (CCT) by instantiating CEF on the Counterfactual Test (CT) from Atanasova et al. (2023). We evaluate the faithfulness of free-text explanations generated by few-shot-prompted LLMs from the Llama2 family on three NLP tasks. We find that our metric measures aspects of faithfulness which the CT misses.
Identifying Linear Relational Concepts in Large Language Models
Nov 15, 2023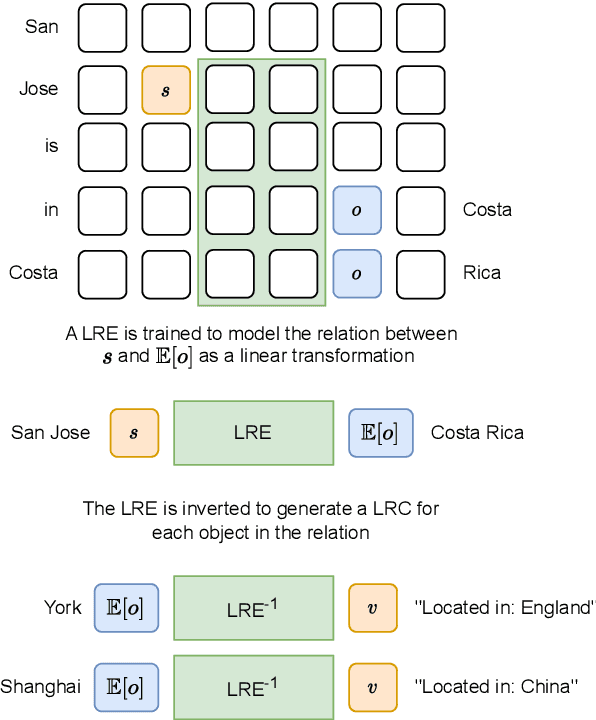


Transformer language models (LMs) have been shown to represent concepts as directions in the latent space of hidden activations. However, for any given human-interpretable concept, how can we find its direction in the latent space? We present a technique called linear relational concepts (LRC) for finding concept directions corresponding to human-interpretable concepts at a given hidden layer in a transformer LM by first modeling the relation between subject and object as a linear relational embedding (LRE). While the LRE work was mainly presented as an exercise in understanding model representations, we find that inverting the LRE while using earlier object layers results in a powerful technique to find concept directions that both work well as a classifier and causally influence model outputs.
Using Natural Language Explanations to Improve Robustness of In-context Learning for Natural Language Inference
Nov 13, 2023



Recent studies have demonstrated that large language models (LLMs) excel in diverse tasks through in-context learning (ICL) facilitated by task-specific prompts and examples. However, the existing literature shows that ICL encounters performance deterioration when exposed to adversarial inputs. Enhanced performance has been observed when ICL is augmented with natural language explanations (NLEs) (we refer to it as X-ICL). Thus, this work investigates whether X-ICL can improve the robustness of LLMs on a suite of seven adversarial and challenging natural language inference datasets. Moreover, we introduce a new approach to X-ICL by prompting an LLM (ChatGPT in our case) with few human-generated NLEs to produce further NLEs (we call it ChatGPT few-shot), which we show superior to both ChatGPT zero-shot and human-generated NLEs alone. We evaluate five popular LLMs (GPT3.5-turbo, LLaMa2, Vicuna, Zephyr, Mistral) and show that X-ICL with ChatGPT few-shot yields over 6% improvement over ICL. Furthermore, while prompt selection strategies were previously shown to significantly improve ICL on in-distribution test sets, we show that these strategies do not match the efficacy of the X-ICL paradigm in robustness-oriented evaluations.
KNOW How to Make Up Your Mind! Adversarially Detecting and Alleviating Inconsistencies in Natural Language Explanations
Jun 05, 2023



While recent works have been considerably improving the quality of the natural language explanations (NLEs) generated by a model to justify its predictions, there is very limited research in detecting and alleviating inconsistencies among generated NLEs. In this work, we leverage external knowledge bases to significantly improve on an existing adversarial attack for detecting inconsistent NLEs. We apply our attack to high-performing NLE models and show that models with higher NLE quality do not necessarily generate fewer inconsistencies. Moreover, we propose an off-the-shelf mitigation method to alleviate inconsistencies by grounding the model into external background knowledge. Our method decreases the inconsistencies of previous high-performing NLE models as detected by our attack.
* Short paper, ACL 2023
Faithfulness Tests for Natural Language Explanations
May 29, 2023
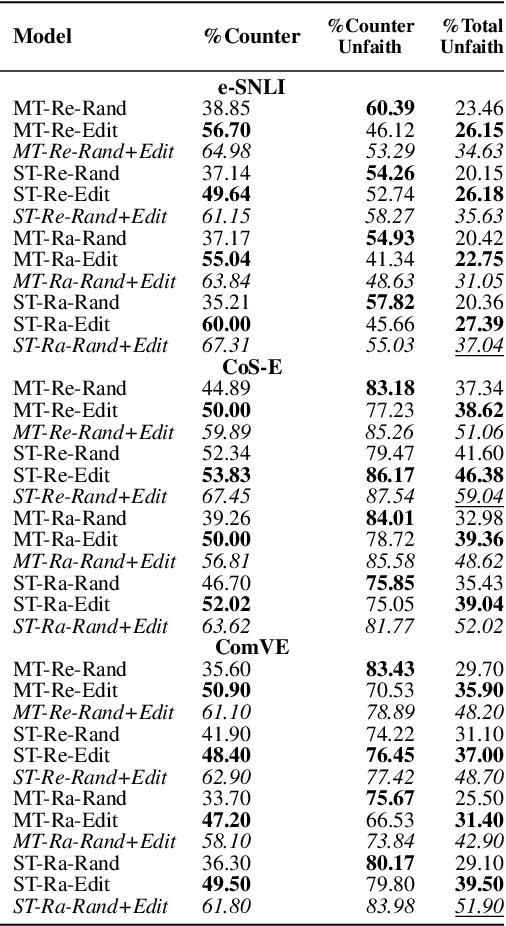
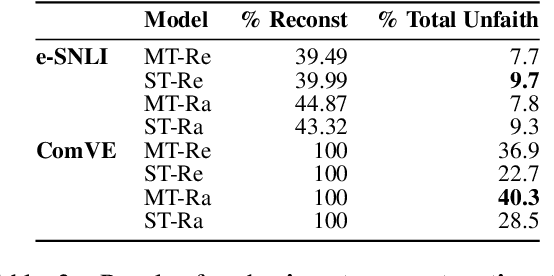

Explanations of neural models aim to reveal a model's decision-making process for its predictions. However, recent work shows that current methods giving explanations such as saliency maps or counterfactuals can be misleading, as they are prone to present reasons that are unfaithful to the model's inner workings. This work explores the challenging question of evaluating the faithfulness of natural language explanations (NLEs). To this end, we present two tests. First, we propose a counterfactual input editor for inserting reasons that lead to counterfactual predictions but are not reflected by the NLEs. Second, we reconstruct inputs from the reasons stated in the generated NLEs and check how often they lead to the same predictions. Our tests can evaluate emerging NLE models, proving a fundamental tool in the development of faithful NLEs.
SPARSEFIT: Few-shot Prompting with Sparse Fine-tuning for Jointly Generating Predictions and Natural Language Explanations
May 23, 2023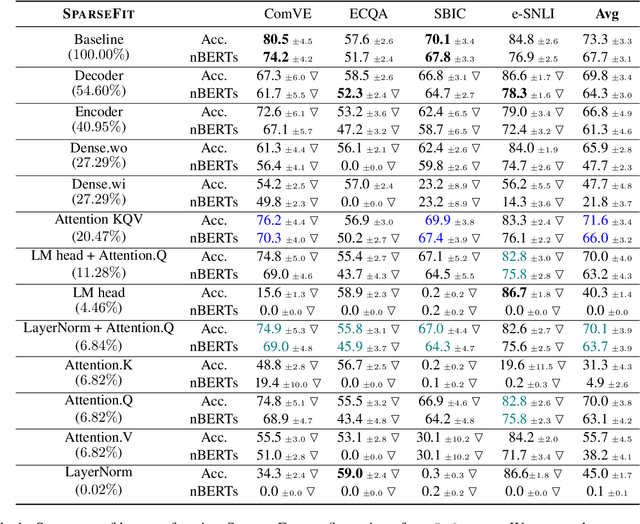
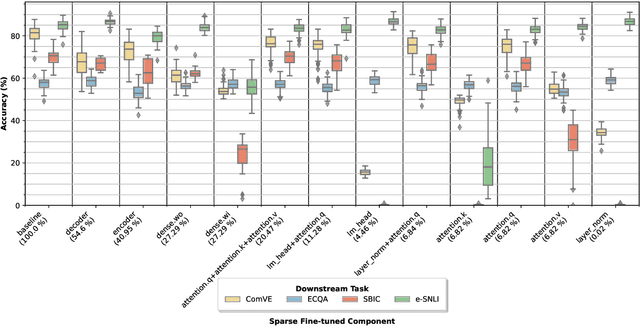
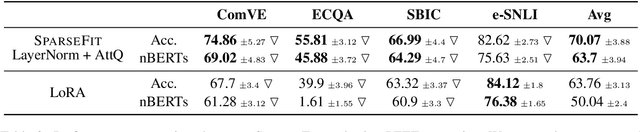
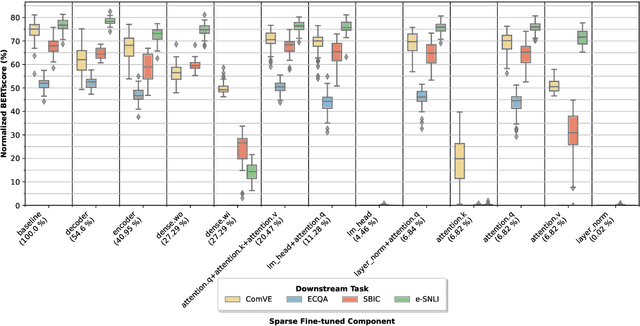
Explaining the decisions of neural models is crucial for ensuring their trustworthiness at deployment time. Using Natural Language Explanations (NLEs) to justify a model's predictions has recently gained increasing interest. However, this approach usually demands large datasets of human-written NLEs for the ground-truth answers, which are expensive and potentially infeasible for some applications. For models to generate high-quality NLEs when only a few NLEs are available, the fine-tuning of Pre-trained Language Models (PLMs) in conjunction with prompt-based learning recently emerged. However, PLMs typically have billions of parameters, making fine-tuning expensive. We propose SparseFit, a sparse few-shot fine-tuning strategy that leverages discrete prompts to jointly generate predictions and NLEs. We experiment with SparseFit on the T5 model and four datasets and compare it against state-of-the-art parameter-efficient fine-tuning techniques. We perform automatic and human evaluations to assess the quality of the model-generated NLEs, finding that fine-tuning only 6.8% of the model parameters leads to competitive results for both the task performance and the quality of the NLEs.