 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKNOW How to Make Up Your Mind! Adversarially Detecting and Alleviating Inconsistencies in Natural Language Explanations
Jun 05, 2023



While recent works have been considerably improving the quality of the natural language explanations (NLEs) generated by a model to justify its predictions, there is very limited research in detecting and alleviating inconsistencies among generated NLEs. In this work, we leverage external knowledge bases to significantly improve on an existing adversarial attack for detecting inconsistent NLEs. We apply our attack to high-performing NLE models and show that models with higher NLE quality do not necessarily generate fewer inconsistencies. Moreover, we propose an off-the-shelf mitigation method to alleviate inconsistencies by grounding the model into external background knowledge. Our method decreases the inconsistencies of previous high-performing NLE models as detected by our attack.
* Short paper, ACL 2023
Consistency Analysis of ChatGPT
Mar 11, 2023ChatGPT, a question-and-answer dialogue system based on a large language model, has gained huge popularity since its introduction. Its positive aspects have been reported through many media platforms, and some analyses even showed that ChatGPT achieved a decent grade in professional exams, including the law, medical, and finance domains, adding extra support to the claim that AI now can assist and, even, replace humans in industrial fields. Others, however, doubt its reliability and trustworthiness. In this paper, we investigate ChatGPT's trustworthiness regarding logically consistent behaviours. Our findings suggest that, although ChatGPT seems to achieve an improved language understanding ability, it still fails to generate logically correct predictions frequently. Hence, while it is true that ChatGPT is an impressive and promising new technique, we conclude that its usage in real-world applications without thorough human inspection requires further consideration, especially for risk-sensitive areas.
Beyond Distributional Hypothesis: Let Language Models Learn Meaning-Text Correspondence
May 08, 2022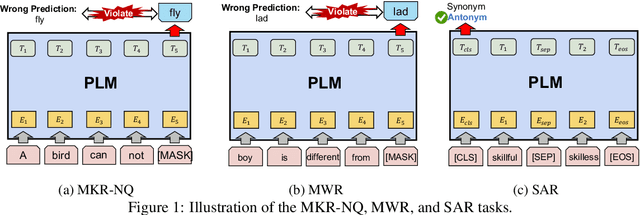
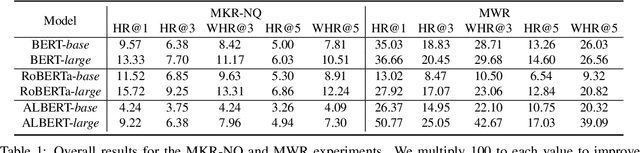
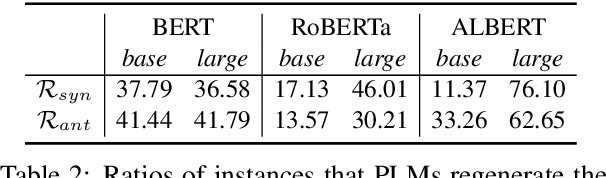
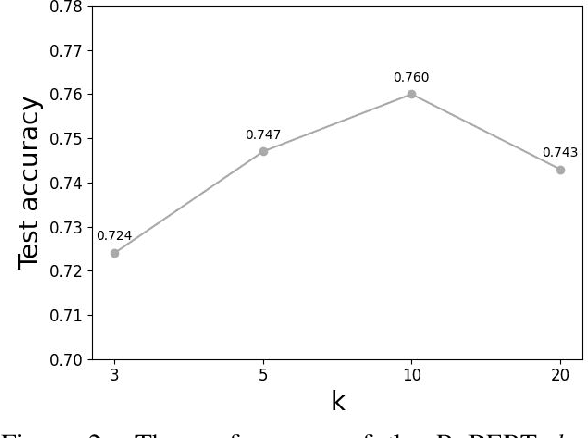
The logical negation property (LNP), which implies generating different predictions for semantically opposite inputs, is an important property that a trustworthy language model must satisfy. However, much recent evidence shows that large-size pre-trained language models (PLMs) do not satisfy this property. In this paper, we perform experiments using probing tasks to assess PLM's LNP understanding. Unlike previous studies that only examined negation expressions, we expand the boundary of the investigation to lexical semantics. Through experiments, we observe that PLMs violate the LNP frequently. To alleviate the issue, we propose a novel intermediate training task, names meaning-matching, designed to directly learn a meaning-text correspondence, instead of relying on the distributional hypothesis. Through multiple experiments, we find that the task enables PLMs to learn lexical semantic information. Also, through fine-tuning experiments on 7 GLUE tasks, we confirm that it is a safe intermediate task that guarantees a similar or better performance of downstream tasks. Finally, we observe that our proposed approach outperforms our previous counterparts despite its time and resource efficiency.
KOBEST: Korean Balanced Evaluation of Significant Tasks
Apr 09, 2022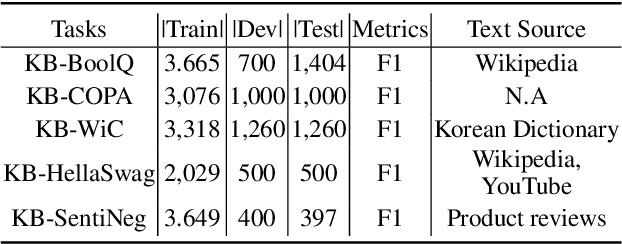



A well-formulated benchmark plays a critical role in spurring advancements in the natural language processing (NLP) field, as it allows objective and precise evaluation of diverse models. As modern language models (LMs) have become more elaborate and sophisticated, more difficult benchmarks that require linguistic knowledge and reasoning have been proposed. However, most of these benchmarks only support English, and great effort is necessary to construct benchmarks for other low resource languages. To this end, we propose a new benchmark named Korean balanced evaluation of significant tasks (KoBEST), which consists of five Korean-language downstream tasks. Professional Korean linguists designed the tasks that require advanced Korean linguistic knowledge. Moreover, our data is purely annotated by humans and thoroughly reviewed to guarantee high data quality. We also provide baseline models and human performance results. Our dataset is available on the Huggingface.
Accurate, yet inconsistent? Consistency Analysis on Language Understanding Models
Aug 15, 2021
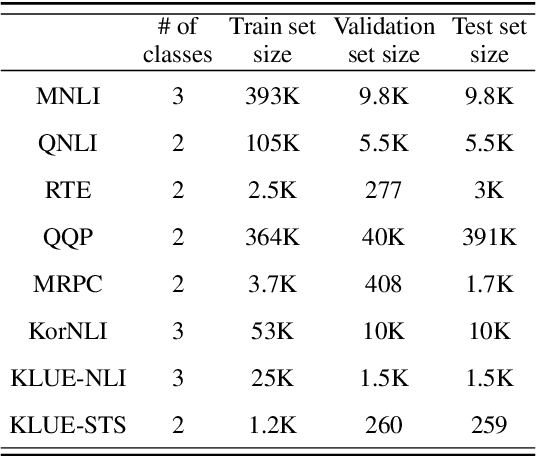
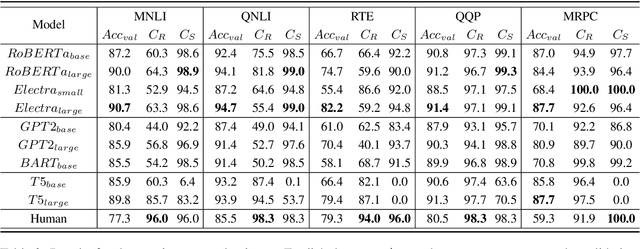
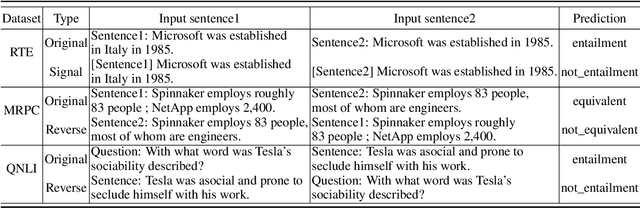
Consistency, which refers to the capability of generating the same predictions for semantically similar contexts, is a highly desirable property for a sound language understanding model. Although recent pretrained language models (PLMs) deliver outstanding performance in various downstream tasks, they should exhibit consistent behaviour provided the models truly understand language. In this paper, we propose a simple framework named consistency analysis on language understanding models (CALUM)} to evaluate the model's lower-bound consistency ability. Through experiments, we confirmed that current PLMs are prone to generate inconsistent predictions even for semantically identical inputs. We also observed that multi-task training with paraphrase identification tasks is of benefit to improve consistency, increasing the consistency by 13% on average.
Sentence transition matrix: An efficient approach that preserves sentence semantics
Jan 16, 2019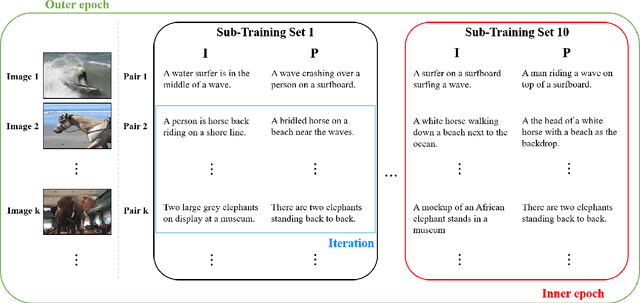
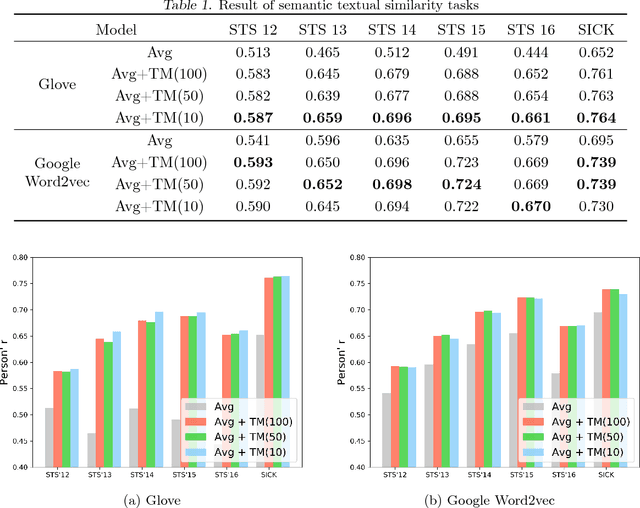
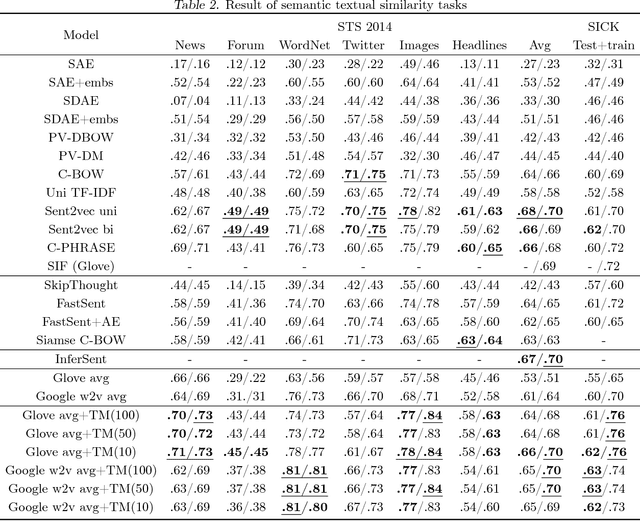
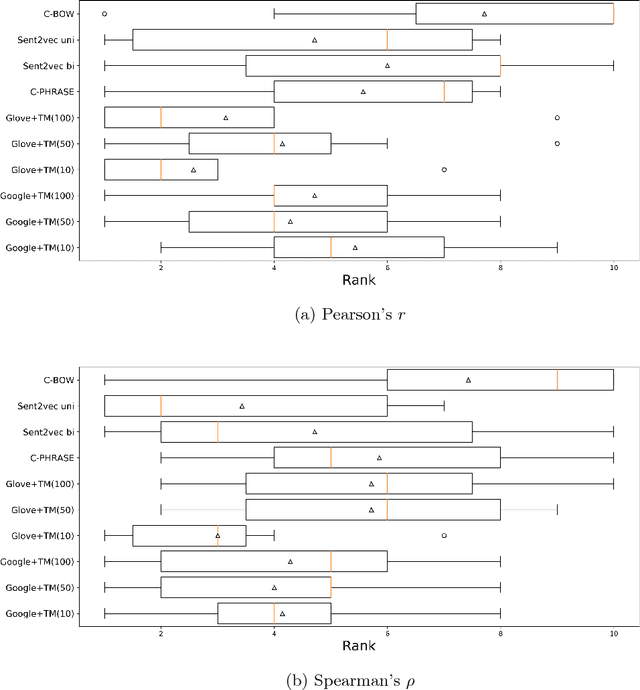
Sentence embedding is a significant research topic in the field of natural language processing (NLP). Generating sentence embedding vectors reflecting the intrinsic meaning of a sentence is a key factor to achieve an enhanced performance in various NLP tasks such as sentence classification and document summarization. Therefore, various sentence embedding models based on supervised and unsupervised learning have been proposed after the advent of researches regarding the distributed representation of words. They were evaluated through semantic textual similarity (STS) tasks, which measure the degree of semantic preservation of a sentence and neural network-based supervised embedding models generally yielded state-of-the-art performance. However, these models have a limitation in that they have multiple parameters to update, thereby requiring a tremendous amount of labeled training data. In this study, we propose an efficient approach that learns a transition matrix that refines a sentence embedding vector to reflect the latent semantic meaning of a sentence. The proposed method has two practical advantages; (1) it can be applied to any sentence embedding method, and (2) it can achieve robust performance in STS tasks irrespective of the number of training examples.
Paraphrase Thought: Sentence Embedding Module Imitating Human Language Recognition
Oct 15, 2018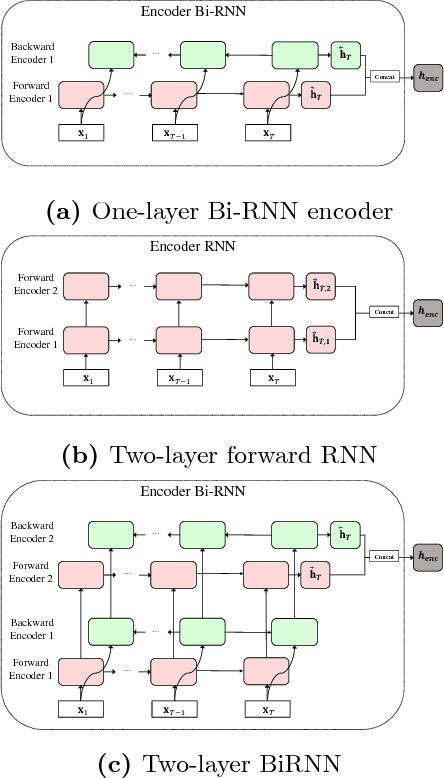
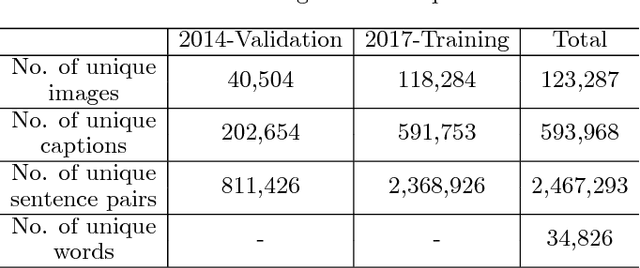
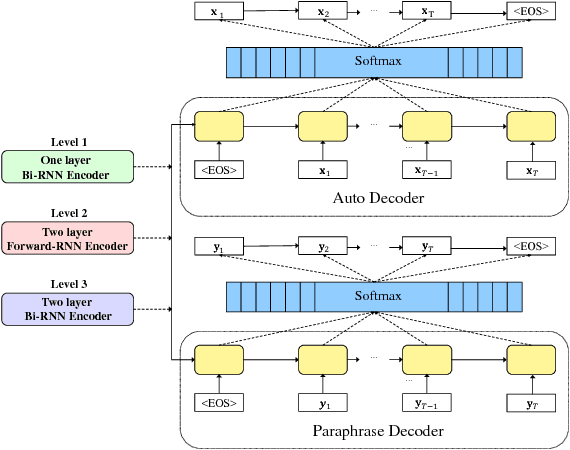
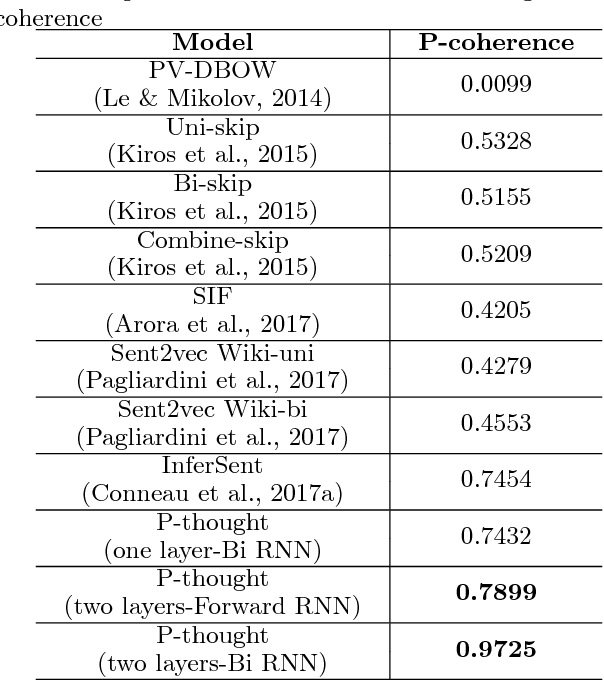
Sentence embedding is an important research topic in natural language processing. It is essential to generate a good embedding vector that fully reflects the semantic meaning of a sentence in order to achieve an enhanced performance for various natural language processing tasks, such as machine translation and document classification. Thus far, various sentence embedding models have been proposed, and their feasibility has been demonstrated through good performances on tasks following embedding, such as sentiment analysis and sentence classification. However, because the performances of sentence classification and sentiment analysis can be enhanced by using a simple sentence representation method, it is not sufficient to claim that these models fully reflect the meanings of sentences based on good performances for such tasks. In this paper, inspired by human language recognition, we propose the following concept of semantic coherence, which should be satisfied for a good sentence embedding method: similar sentences should be located close to each other in the embedding space. Then, we propose the Paraphrase-Thought (P-thought) model to pursue semantic coherence as much as possible. Experimental results on two paraphrase identification datasets (MS COCO and STS benchmark) show that the P-thought models outperform the benchmarked sentence embedding methods.
Recurrent Neural Network-Based Semantic Variational Autoencoder for Sequence-to-Sequence Learning
Jun 02, 2018

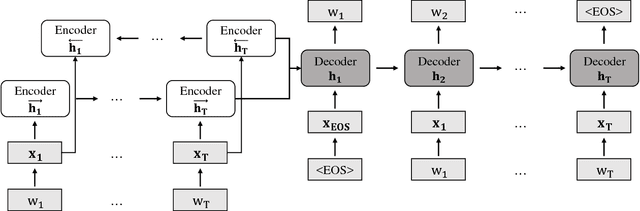

Sequence-to-sequence (Seq2seq) models have played an important role in the recent success of various natural language processing methods, such as machine translation, text summarization, and speech recognition. However, current Seq2seq models have trouble preserving global latent information from a long sequence of words. Variational autoencoder (VAE) alleviates this problem by learning a continuous semantic space of the input sentence. However, it does not solve the problem completely. In this paper, we propose a new recurrent neural network (RNN)-based Seq2seq model, RNN semantic variational autoencoder (RNN--SVAE), to better capture the global latent information of a sequence of words. To reflect the meaning of words in a sentence properly, without regard to its position within the sentence, we construct a document information vector using the attention information between the final state of the encoder and every prior hidden state. Then, the mean and standard deviation of the continuous semantic space are learned by using this vector to take advantage of the variational method. By using the document information vector to find the semantic space of the sentence, it becomes possible to better capture the global latent feature of the sentence. Experimental results of three natural language tasks (i.e., language modeling, missing word imputation, paraphrase identification) confirm that the proposed RNN--SVAE yields higher performance than two benchmark models.