 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Neural Network-Based Semantic Variational Autoencoder for Sequence-to-Sequence Learning
Jun 02, 2018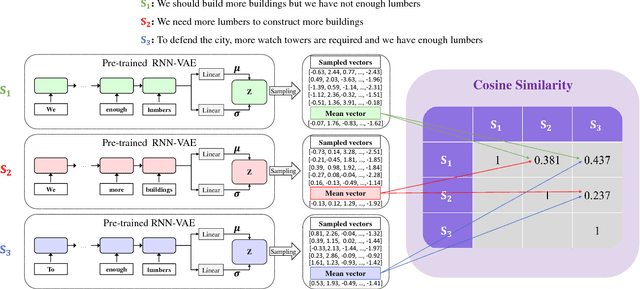

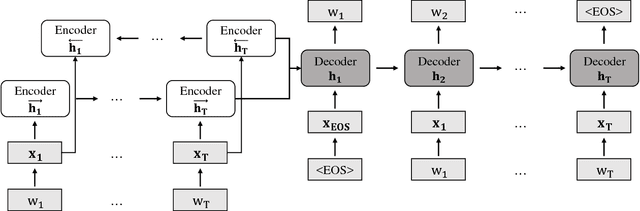

Sequence-to-sequence (Seq2seq) models have played an important role in the recent success of various natural language processing methods, such as machine translation, text summarization, and speech recognition. However, current Seq2seq models have trouble preserving global latent information from a long sequence of words. Variational autoencoder (VAE) alleviates this problem by learning a continuous semantic space of the input sentence. However, it does not solve the problem completely. In this paper, we propose a new recurrent neural network (RNN)-based Seq2seq model, RNN semantic variational autoencoder (RNN--SVAE), to better capture the global latent information of a sequence of words. To reflect the meaning of words in a sentence properly, without regard to its position within the sentence, we construct a document information vector using the attention information between the final state of the encoder and every prior hidden state. Then, the mean and standard deviation of the continuous semantic space are learned by using this vector to take advantage of the variational method. By using the document information vector to find the semantic space of the sentence, it becomes possible to better capture the global latent feature of the sentence. Experimental results of three natural language tasks (i.e., language modeling, missing word imputation, paraphrase identification) confirm that the proposed RNN--SVAE yields higher performance than two benchmark models.
Sentiment Classification with Word Attention based on Weakly Supervised Learning with a Convolutional Neural Network
Sep 29, 2017
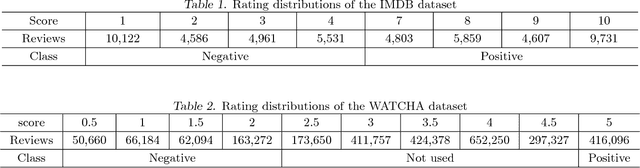
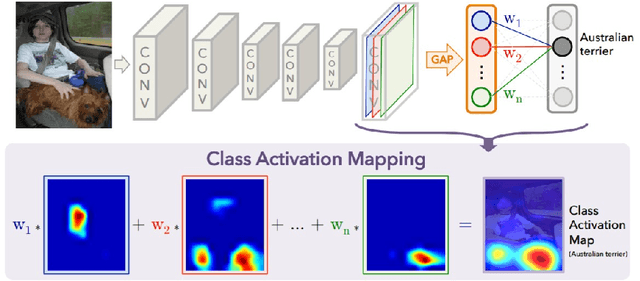

In order to maximize the applicability of sentiment analysis results, it is necessary to not only classify the overall sentiment (positive/negative) of a given document but also to identify the main words that contribute to the classification. However, most datasets for sentiment analysis only have the sentiment label for each document or sentence. In other words, there is no information about which words play an important role in sentiment classification. In this paper, we propose a method for identifying key words discriminating positive and negative sentences by using a weakly supervised learning method based on a convolutional neural network (CNN). In our model, each word is represented as a continuous-valued vector and each sentence is represented as a matrix whose rows correspond to the word vector used in the sentence. Then, the CNN model is trained using these sentence matrices as inputs and the sentiment labels as the output. Once the CNN model is trained, we implement the word attention mechanism that identifies high-contributing words to classification results with a class activation map, using the weights from the fully connected layer at the end of the learned CNN model. In order to verify the proposed methodology, we evaluated the classification accuracy and inclusion rate of polarity words using two movie review datasets. Experimental result show that the proposed model can not only correctly classify the sentence polarity but also successfully identify the corresponding words with high polarity scores.