 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity or Relation Embeddings? An Analysis of Encoding Strategies for Relation Extraction
Dec 18, 2023



Relation extraction is essentially a text classification problem, which can be tackled by fine-tuning a pre-trained language model (LM). However, a key challenge arises from the fact that relation extraction cannot straightforwardly be reduced to sequence or token classification. Existing approaches therefore solve the problem in an indirect way: they fine-tune an LM to learn embeddings of the head and tail entities, and then predict the relationship from these entity embeddings. Our hypothesis in this paper is that relation extraction models can be improved by capturing relationships in a more direct way. In particular, we experiment with appending a prompt with a [MASK] token, whose contextualised representation is treated as a relation embedding. While, on its own, this strategy significantly underperforms the aforementioned approach, we find that the resulting relation embeddings are highly complementary to what is captured by embeddings of the head and tail entity. By jointly considering both types of representations, we end up with a simple model that outperforms the state-of-the-art across several relation extraction benchmarks.
EnCore: Pre-Training Entity Encoders using Coreference Chains
May 22, 2023Entity typing is the task of assigning semantic types to the entities that are mentioned in a text. Since obtaining sufficient amounts of manual annotations is expensive, current state-of-the-art methods are typically trained on automatically labelled datasets, e.g. by exploiting links between Wikipedia pages. In this paper, we propose to use coreference chains as an additional supervision signal. Specifically, we pre-train an entity encoder using a contrastive loss, such that entity embeddings of coreferring entities are more similar to each other than to the embeddings of other entities. Since this strategy is not tied to Wikipedia, we can pre-train our entity encoder on other genres than encyclopedic text and on larger amounts of data. Our experimental results show that the proposed pre-training strategy allows us to improve the state-of-the-art in fine-grained entity typing, provided that only high-quality coreference links are exploited.
Beyond Distributional Hypothesis: Let Language Models Learn Meaning-Text Correspondence
May 08, 2022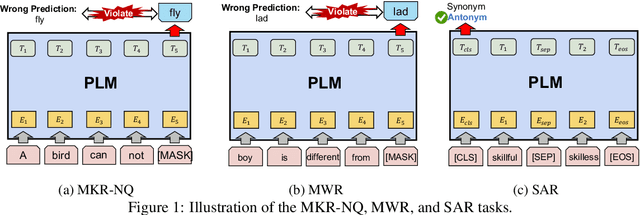
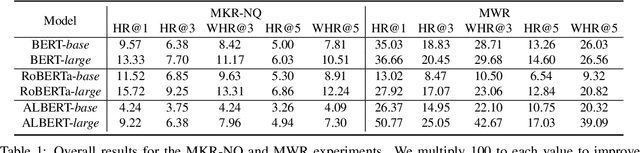
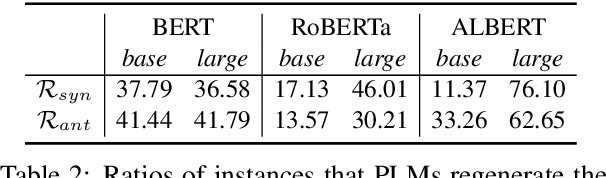
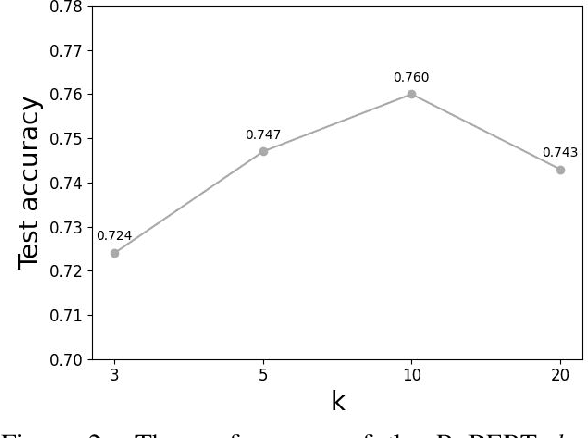
The logical negation property (LNP), which implies generating different predictions for semantically opposite inputs, is an important property that a trustworthy language model must satisfy. However, much recent evidence shows that large-size pre-trained language models (PLMs) do not satisfy this property. In this paper, we perform experiments using probing tasks to assess PLM's LNP understanding. Unlike previous studies that only examined negation expressions, we expand the boundary of the investigation to lexical semantics. Through experiments, we observe that PLMs violate the LNP frequently. To alleviate the issue, we propose a novel intermediate training task, names meaning-matching, designed to directly learn a meaning-text correspondence, instead of relying on the distributional hypothesis. Through multiple experiments, we find that the task enables PLMs to learn lexical semantic information. Also, through fine-tuning experiments on 7 GLUE tasks, we confirm that it is a safe intermediate task that guarantees a similar or better performance of downstream tasks. Finally, we observe that our proposed approach outperforms our previous counterparts despite its time and resource efficiency.