 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResilient AI Supercomputer Networking using MRC and SRv6
May 05, 2026Tail latency dominates the performance of synchronous pretraining jobs when running at very large scales. We describe a three-pronged approach: (1) a new RDMA-based transport protocol, MRC, sprays across many paths and actively load-balances between them, eliminating the issue of flow collisions (2) the use of multi-plane Clos topologies to get the benefits of high switch radix and redundancy, allowing training clusters well over 100K GPUs to be built as two-tier topologies while increasing physical redundancy, and (3) the use of static source-routing using SRv6 to allow MRC the freedom to bypass failures by itself. We describe our experiences running MRC and static SRv6 routing in production in OpenAI and Microsoft's largest training clusters, where it has been used to train the latest frontier models. We demonstrate how MRC allows AI training jobs to ride out many network failures that previously would have interrupted training.
WHAT, WHEN, and HOW to Ground: Designing User Persona-Aware Conversational Agents for Engaging Dialogue
Jun 21, 2023



This paper presents a method for building a personalized open-domain dialogue system to address the $\textit{WWH}$ ($\textit{WHAT}$, $\textit{WHEN}$, and $\textit{HOW}$) problem for natural response generation in a commercial setting, where personalized dialogue responses are heavily interleaved with casual response turns. The proposed approach involves weighted dataset blending, negative persona information augmentation methods, and the design of personalized conversation datasets to address the challenges of $\textit{WWH}$ in personalized, open-domain dialogue systems. Our work effectively balances dialogue fluency and tendency to ground, while also introducing a response-type label to improve the controllability and explainability of the grounded responses. The combination of these methods leads to more fluent conversations, as evidenced by subjective human evaluations as well as objective evaluations.
DLKoopman: A deep learning software package for Koopman theory
Nov 15, 2022


We present DLKoopman -- a software package for Koopman theory that uses deep learning to learn an encoding of a nonlinear dynamical system into a linear space, while simultaneously learning the linear dynamics. While several previous efforts have either restricted the ability to learn encodings, or been bespoke efforts designed for specific systems, DLKoopman is a generalized tool that can be applied to data-driven learning and optimization of any dynamical system. It can either be trained on data from individual states (snapshots) of a system and used to predict its unknown states, or trained on data from trajectories of a system and used to predict unknown trajectories for new initial states. DLKoopman is available on the Python Package Index (PyPI) as 'dlkoopman', and includes extensive documentation and tutorials. Additional contributions of the package include a novel metric called Average Normalized Absolute Error for evaluating performance, and a ready-to-use hyperparameter search module for improving performance.
KOBEST: Korean Balanced Evaluation of Significant Tasks
Apr 09, 2022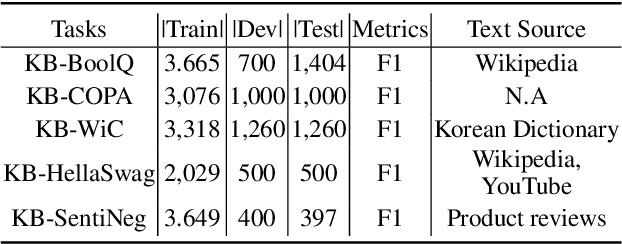



A well-formulated benchmark plays a critical role in spurring advancements in the natural language processing (NLP) field, as it allows objective and precise evaluation of diverse models. As modern language models (LMs) have become more elaborate and sophisticated, more difficult benchmarks that require linguistic knowledge and reasoning have been proposed. However, most of these benchmarks only support English, and great effort is necessary to construct benchmarks for other low resource languages. To this end, we propose a new benchmark named Korean balanced evaluation of significant tasks (KoBEST), which consists of five Korean-language downstream tasks. Professional Korean linguists designed the tasks that require advanced Korean linguistic knowledge. Moreover, our data is purely annotated by humans and thoroughly reviewed to guarantee high data quality. We also provide baseline models and human performance results. Our dataset is available on the Huggingface.
The Untapped Potential of Off-the-Shelf Convolutional Neural Networks
Mar 17, 2021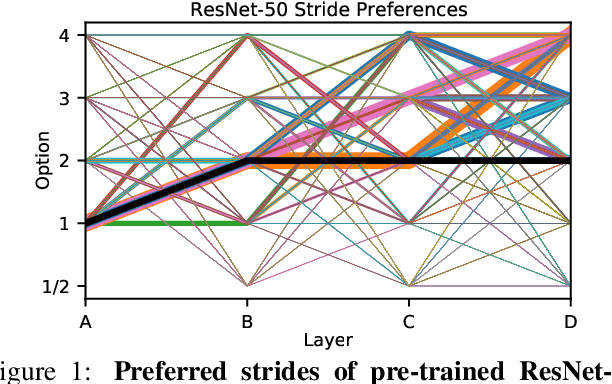
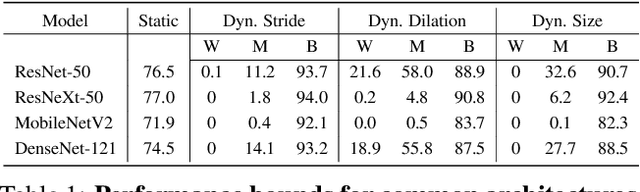
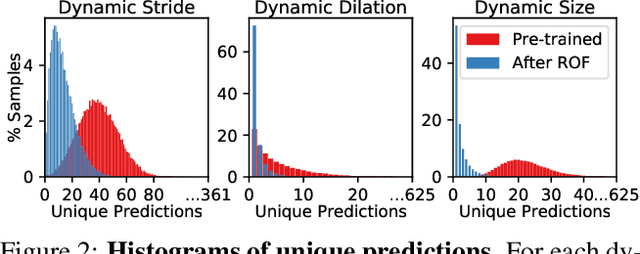

Over recent years, a myriad of novel convolutional network architectures have been developed to advance state-of-the-art performance on challenging recognition tasks. As computational resources improve, a great deal of effort has been placed in efficiently scaling up existing designs and generating new architectures with Neural Architecture Search (NAS) algorithms. While network topology has proven to be a critical factor for model performance, we show that significant gains are being left on the table by keeping topology static at inference-time. Due to challenges such as scale variation, we should not expect static models configured to perform well across a training dataset to be optimally configured to handle all test data. In this work, we seek to expose the exciting potential of inference-time-dynamic models. By allowing just four layers to dynamically change configuration at inference-time, we show that existing off-the-shelf models like ResNet-50 are capable of over 95% accuracy on ImageNet. This level of performance currently exceeds that of models with over 20x more parameters and significantly more complex training procedures.