 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSR-ViT: A Simple and Modular Framework for Open-Set Object Detection and Discovery
Apr 16, 2024An object detector's ability to detect and flag \textit{novel} objects during open-world deployments is critical for many real-world applications. Unfortunately, much of the work in open object detection today is disjointed and fails to adequately address applications that prioritize unknown object recall \textit{in addition to} known-class accuracy. To close this gap, we present a new task called Open-Set Object Detection and Discovery (OSODD) and as a solution propose the Open-Set Regions with ViT features (OSR-ViT) detection framework. OSR-ViT combines a class-agnostic proposal network with a powerful ViT-based classifier. Its modular design simplifies optimization and allows users to easily swap proposal solutions and feature extractors to best suit their application. Using our multifaceted evaluation protocol, we show that OSR-ViT obtains performance levels that far exceed state-of-the-art supervised methods. Our method also excels in low-data settings, outperforming supervised baselines using a fraction of the training data.
Self-Trained Proposal Networks for the Open World
Aug 23, 2022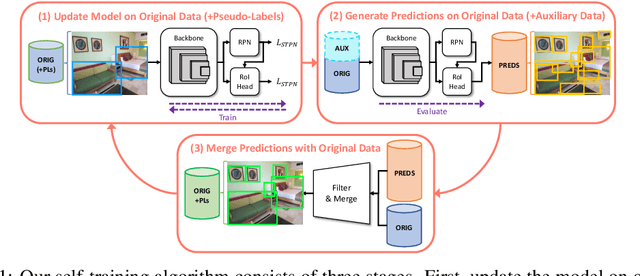



Deep learning-based object proposal methods have enabled significant advances in many computer vision pipelines. However, current state-of-the-art proposal networks use a closed-world assumption, meaning they are only trained to detect instances of the training classes while treating every other region as background. This style of solution fails to provide high recall on out-of-distribution objects, rendering it inadequate for use in realistic open-world applications where novel object categories of interest may be observed. To better detect all objects, we propose a classification-free Self-Trained Proposal Network (STPN) that leverages a novel self-training optimization strategy combined with dynamically weighted loss functions that account for challenges such as class imbalance and pseudo-label uncertainty. Not only is our model designed to excel in existing optimistic open-world benchmarks, but also in challenging operating environments where there is significant label bias. To showcase this, we devise two challenges to test the generalization of proposal models when the training data contains (1) less diversity within the labeled classes, and (2) fewer labeled instances. Our results show that STPN achieves state-of-the-art novel object generalization on all tasks.
The Untapped Potential of Off-the-Shelf Convolutional Neural Networks
Mar 17, 2021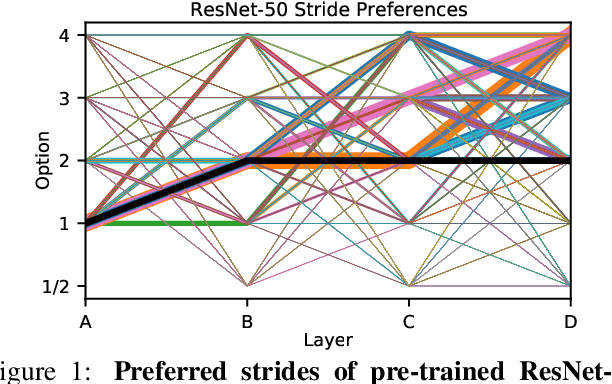
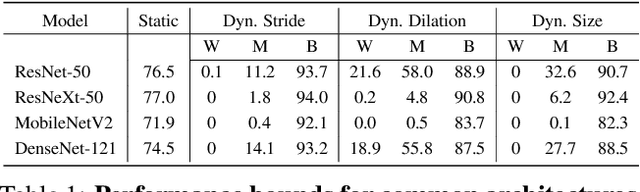
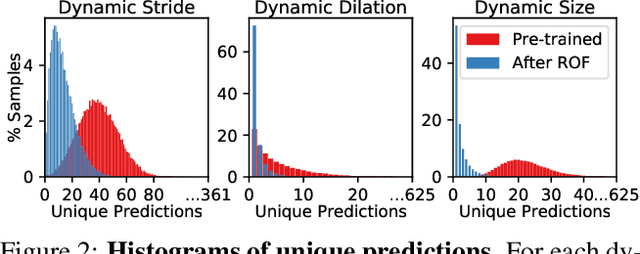

Over recent years, a myriad of novel convolutional network architectures have been developed to advance state-of-the-art performance on challenging recognition tasks. As computational resources improve, a great deal of effort has been placed in efficiently scaling up existing designs and generating new architectures with Neural Architecture Search (NAS) algorithms. While network topology has proven to be a critical factor for model performance, we show that significant gains are being left on the table by keeping topology static at inference-time. Due to challenges such as scale variation, we should not expect static models configured to perform well across a training dataset to be optimally configured to handle all test data. In this work, we seek to expose the exciting potential of inference-time-dynamic models. By allowing just four layers to dynamically change configuration at inference-time, we show that existing off-the-shelf models like ResNet-50 are capable of over 95% accuracy on ImageNet. This level of performance currently exceeds that of models with over 20x more parameters and significantly more complex training procedures.
Perturbing Across the Feature Hierarchy to Improve Standard and Strict Blackbox Attack Transferability
Apr 29, 2020



We consider the blackbox transfer-based targeted adversarial attack threat model in the realm of deep neural network (DNN) image classifiers. Rather than focusing on crossing decision boundaries at the output layer of the source model, our method perturbs representations throughout the extracted feature hierarchy to resemble other classes. We design a flexible attack framework that allows for multi-layer perturbations and demonstrates state-of-the-art targeted transfer performance between ImageNet DNNs. We also show the superiority of our feature space methods under a relaxation of the common assumption that the source and target models are trained on the same dataset and label space, in some instances achieving a $10\times$ increase in targeted success rate relative to other blackbox transfer methods. Finally, we analyze why the proposed methods outperform existing attack strategies and show an extension of the method in the case when limited queries to the blackbox model are allowed.
Snooping Attacks on Deep Reinforcement Learning
May 28, 2019


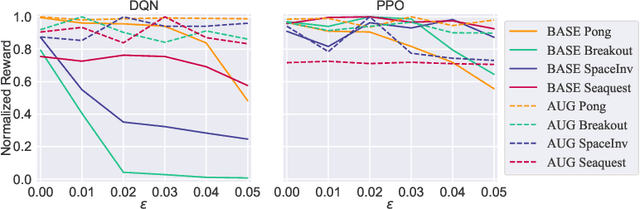
Adversarial attacks have exposed a significant security vulnerability in state-of-the-art machine learning models. Among these models include deep reinforcement learning agents. The existing methods for attacking reinforcement learning agents assume the adversary either has access to the target agent's learned parameters or the environment that the agent interacts with. In this work, we propose a new class of threat models, called snooping threat models, that are unique to reinforcement learning. In these snooping threat models, the adversary does not have the ability to personally interact with the environment, and can only eavesdrop on the action and reward signals being exchanged between agent and environment. We show that adversaries operating in these highly constrained threat models can still launch devastating attacks against the target agent by training proxy models on related tasks and leveraging the transferability of adversarial examples.
Adversarial Attacks for Optical Flow-Based Action Recognition Classifiers
Nov 28, 2018



The success of deep learning research has catapulted deep models into production systems that our society is becoming increasingly dependent on, especially in the image and video domains. However, recent work has shown that these largely uninterpretable models exhibit glaring security vulnerabilities in the presence of an adversary. In this work, we develop a powerful untargeted adversarial attack for action recognition systems in both white-box and black-box settings. Action recognition models differ from image-classification models in that their inputs contain a temporal dimension, which we explicitly target in the attack. Drawing inspiration from image classifier attacks, we create new attacks which achieve state-of-the-art success rates on a two-stream classifier trained on the UCF-101 dataset. We find that our attacks can significantly degrade a model's performance with sparsely and imperceptibly perturbed examples. We also demonstrate the transferability of our attacks to black-box action recognition systems.