 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-layer Radial Basis Function Networks for Out-of-distribution Detection
Jan 05, 2025



Existing methods for out-of-distribution (OOD) detection use various techniques to produce a score, separate from classification, that determines how ``OOD'' an input is. Our insight is that OOD detection can be simplified by using a neural network architecture which can effectively merge classification and OOD detection into a single step. Radial basis function networks (RBFNs) inherently link classification confidence and OOD detection; however, these networks have lost popularity due to the difficult of training them in a multi-layer fashion. In this work, we develop a multi-layer radial basis function network (MLRBFN) which can be easily trained. To ensure that these networks are also effective for OOD detection, we develop a novel depression mechanism. We apply MLRBFNs as standalone classifiers and as heads on top of pretrained feature extractors, and find that they are competitive with commonly used methods for OOD detection. Our MLRBFN architecture demonstrates a promising new direction for OOD detection methods.
OSR-ViT: A Simple and Modular Framework for Open-Set Object Detection and Discovery
Apr 16, 2024An object detector's ability to detect and flag \textit{novel} objects during open-world deployments is critical for many real-world applications. Unfortunately, much of the work in open object detection today is disjointed and fails to adequately address applications that prioritize unknown object recall \textit{in addition to} known-class accuracy. To close this gap, we present a new task called Open-Set Object Detection and Discovery (OSODD) and as a solution propose the Open-Set Regions with ViT features (OSR-ViT) detection framework. OSR-ViT combines a class-agnostic proposal network with a powerful ViT-based classifier. Its modular design simplifies optimization and allows users to easily swap proposal solutions and feature extractors to best suit their application. Using our multifaceted evaluation protocol, we show that OSR-ViT obtains performance levels that far exceed state-of-the-art supervised methods. Our method also excels in low-data settings, outperforming supervised baselines using a fraction of the training data.
SoK: A Review of Differentially Private Linear Models For High-Dimensional Data
Apr 01, 2024
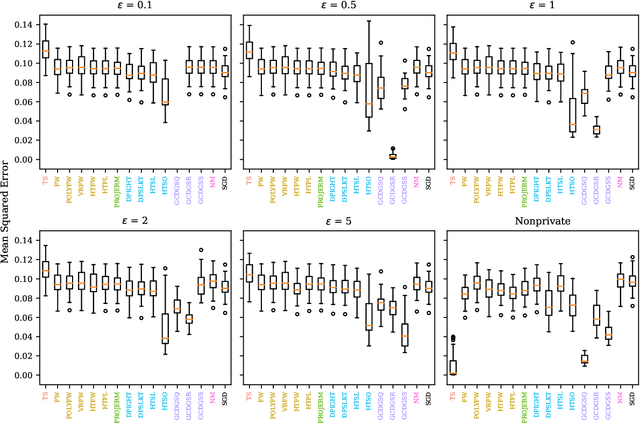
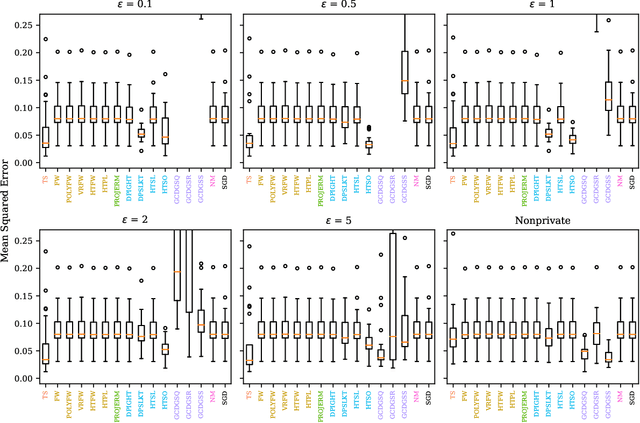
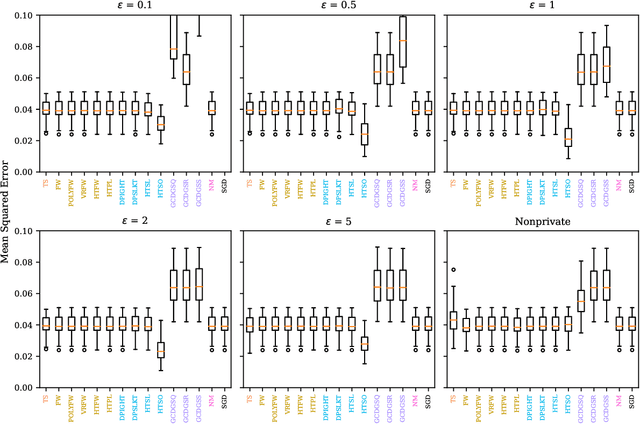
Linear models are ubiquitous in data science, but are particularly prone to overfitting and data memorization in high dimensions. To guarantee the privacy of training data, differential privacy can be used. Many papers have proposed optimization techniques for high-dimensional differentially private linear models, but a systematic comparison between these methods does not exist. We close this gap by providing a comprehensive review of optimization methods for private high-dimensional linear models. Empirical tests on all methods demonstrate robust and coordinate-optimized algorithms perform best, which can inform future research. Code for implementing all methods is released online.
Out-of-Distribution Detection via Deep Multi-Comprehension Ensemble
Mar 24, 2024



Recent research underscores the pivotal role of the Out-of-Distribution (OOD) feature representation field scale in determining the efficacy of models in OOD detection. Consequently, the adoption of model ensembles has emerged as a prominent strategy to augment this feature representation field, capitalizing on anticipated model diversity. However, our introduction of novel qualitative and quantitative model ensemble evaluation methods, specifically Loss Basin/Barrier Visualization and the Self-Coupling Index, reveals a critical drawback in existing ensemble methods. We find that these methods incorporate weights that are affine-transformable, exhibiting limited variability and thus failing to achieve the desired diversity in feature representation. To address this limitation, we elevate the dimensions of traditional model ensembles, incorporating various factors such as different weight initializations, data holdout, etc., into distinct supervision tasks. This innovative approach, termed Multi-Comprehension (MC) Ensemble, leverages diverse training tasks to generate distinct comprehensions of the data and labels, thereby extending the feature representation field. Our experimental results demonstrate the superior performance of the MC Ensemble strategy in OOD detection compared to both the naive Deep Ensemble method and a standalone model of comparable size. This underscores the effectiveness of our proposed approach in enhancing the model's capability to detect instances outside its training distribution.
Comprehensive OOD Detection Improvements
Jan 18, 2024As machine learning becomes increasingly prevalent in impactful decisions, recognizing when inference data is outside the model's expected input distribution is paramount for giving context to predictions. Out-of-distribution (OOD) detection methods have been created for this task. Such methods can be split into representation-based or logit-based methods from whether they respectively utilize the model's embeddings or predictions for OOD detection. In contrast to most papers which solely focus on one such group, we address both. We employ dimensionality reduction on feature embeddings in representation-based methods for both time speedups and improved performance. Additionally, we propose DICE-COL, a modification of the popular logit-based method Directed Sparsification (DICE) that resolves an unnoticed flaw. We demonstrate the effectiveness of our methods on the OpenOODv1.5 benchmark framework, where they significantly improve performance and set state-of-the-art results.
Adversarial Attacks on Foundational Vision Models
Aug 28, 2023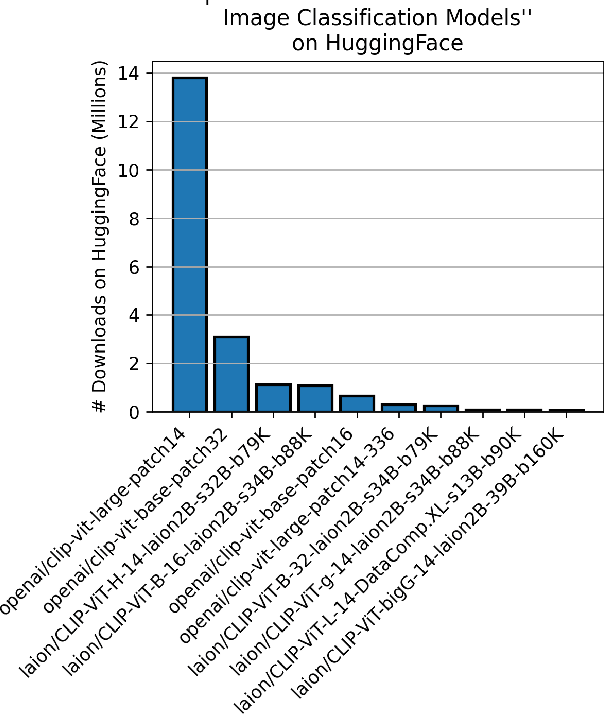
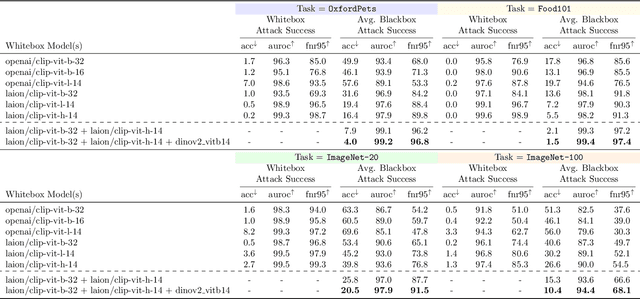
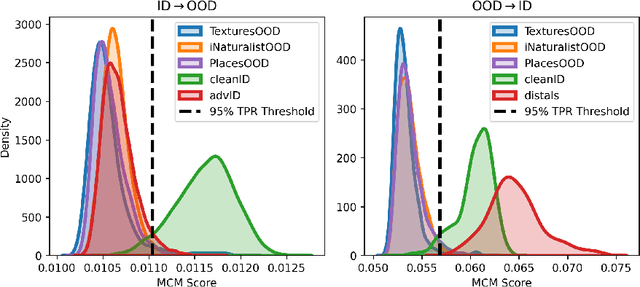
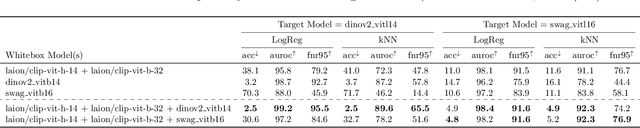
Rapid progress is being made in developing large, pretrained, task-agnostic foundational vision models such as CLIP, ALIGN, DINOv2, etc. In fact, we are approaching the point where these models do not have to be finetuned downstream, and can simply be used in zero-shot or with a lightweight probing head. Critically, given the complexity of working at this scale, there is a bottleneck where relatively few organizations in the world are executing the training then sharing the models on centralized platforms such as HuggingFace and torch.hub. The goal of this work is to identify several key adversarial vulnerabilities of these models in an effort to make future designs more robust. Intuitively, our attacks manipulate deep feature representations to fool an out-of-distribution (OOD) detector which will be required when using these open-world-aware models to solve closed-set downstream tasks. Our methods reliably make in-distribution (ID) images (w.r.t. a downstream task) be predicted as OOD and vice versa while existing in extremely low-knowledge-assumption threat models. We show our attacks to be potent in whitebox and blackbox settings, as well as when transferred across foundational model types (e.g., attack DINOv2 with CLIP)! This work is only just the beginning of a long journey towards adversarially robust foundational vision models.
Establishing baselines and introducing TernaryMixOE for fine-grained out-of-distribution detection
Mar 30, 2023



Machine learning models deployed in the open world may encounter observations that they were not trained to recognize, and they risk misclassifying such observations with high confidence. Therefore, it is essential that these models are able to ascertain what is in-distribution (ID) and out-of-distribution (OOD), to avoid this misclassification. In recent years, huge strides have been made in creating models that are robust to this distinction. As a result, the current state-of-the-art has reached near perfect performance on relatively coarse-grained OOD detection tasks, such as distinguishing horses from trucks, while struggling with finer-grained classification, like differentiating models of commercial aircraft. In this paper, we describe a new theoretical framework for understanding fine- and coarse-grained OOD detection, we re-conceptualize fine grained classification into a three part problem, and we propose a new baseline task for OOD models on two fine-grained hierarchical data sets, two new evaluation methods to differentiate fine- and coarse-grained OOD performance, along with a new loss function for models in this task.
SIO: Synthetic In-Distribution Data Benefits Out-of-Distribution Detection
Mar 25, 2023Building up reliable Out-of-Distribution (OOD) detectors is challenging, often requiring the use of OOD data during training. In this work, we develop a data-driven approach which is distinct and complementary to existing works: Instead of using external OOD data, we fully exploit the internal in-distribution (ID) training set by utilizing generative models to produce additional synthetic ID images. The classifier is then trained using a novel objective that computes weighted loss on real and synthetic ID samples together. Our training framework, which is termed SIO, serves as a "plug-and-play" technique that is designed to be compatible with existing and future OOD detection algorithms, including the ones that leverage available OOD training data. Our experiments on CIFAR-10, CIFAR-100, and ImageNet variants demonstrate that SIO consistently improves the performance of nearly all state-of-the-art (SOTA) OOD detection algorithms. For instance, on the challenging CIFAR-10 v.s. CIFAR-100 detection problem, SIO improves the average OOD detection AUROC of 18 existing methods from 86.25\% to 89.04\% and achieves a new SOTA of 92.94\% according to the OpenOOD benchmark. Code is available at https://github.com/zjysteven/SIO.
A Global Model Approach to Robust Few-Shot SAR Automatic Target Recognition
Mar 20, 2023



In real-world scenarios, it may not always be possible to collect hundreds of labeled samples per class for training deep learning-based SAR Automatic Target Recognition (ATR) models. This work specifically tackles the few-shot SAR ATR problem, where only a handful of labeled samples may be available to support the task of interest. Our approach is composed of two stages. In the first, a global representation model is trained via self-supervised learning on a large pool of diverse and unlabeled SAR data. In the second stage, the global model is used as a fixed feature extractor and a classifier is trained to partition the feature space given the few-shot support samples, while simultaneously being calibrated to detect anomalous inputs. Unlike competing approaches which require a pristine labeled dataset for pretraining via meta-learning, our approach learns highly transferable features from unlabeled data that have little-to-no relation to the downstream task. We evaluate our method in standard and extended MSTAR operating conditions and find it to achieve high accuracy and robust out-of-distribution detection in many different few-shot settings. Our results are particularly significant because they show the merit of a global model approach to SAR ATR, which makes minimal assumptions, and provides many axes for extendability.
Fine-grain Inference on Out-of-Distribution Data with Hierarchical Classification
Sep 09, 2022



Machine learning methods must be trusted to make appropriate decisions in real-world environments, even when faced with out-of-distribution (OOD) samples. Many current approaches simply aim to detect OOD examples and alert the user when an unrecognized input is given. However, when the OOD sample significantly overlaps with the training data, a binary anomaly detection is not interpretable or explainable, and provides little information to the user. We propose a new model for OOD detection that makes predictions at varying levels of granularity as the inputs become more ambiguous, the model predictions become coarser and more conservative. Consider an animal classifier that encounters an unknown bird species and a car. Both cases are OOD, but the user gains more information if the classifier recognizes that its uncertainty over the particular species is too large and predicts bird instead of detecting it as OOD. Furthermore, we diagnose the classifiers performance at each level of the hierarchy improving the explainability and interpretability of the models predictions. We demonstrate the effectiveness of hierarchical classifiers for both fine- and coarse-grained OOD tasks.