 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-layer Radial Basis Function Networks for Out-of-distribution Detection
Jan 05, 2025



Existing methods for out-of-distribution (OOD) detection use various techniques to produce a score, separate from classification, that determines how ``OOD'' an input is. Our insight is that OOD detection can be simplified by using a neural network architecture which can effectively merge classification and OOD detection into a single step. Radial basis function networks (RBFNs) inherently link classification confidence and OOD detection; however, these networks have lost popularity due to the difficult of training them in a multi-layer fashion. In this work, we develop a multi-layer radial basis function network (MLRBFN) which can be easily trained. To ensure that these networks are also effective for OOD detection, we develop a novel depression mechanism. We apply MLRBFNs as standalone classifiers and as heads on top of pretrained feature extractors, and find that they are competitive with commonly used methods for OOD detection. Our MLRBFN architecture demonstrates a promising new direction for OOD detection methods.
AI Model Utilization Measurements For Finding Class Encoding Patterns
Dec 12, 2022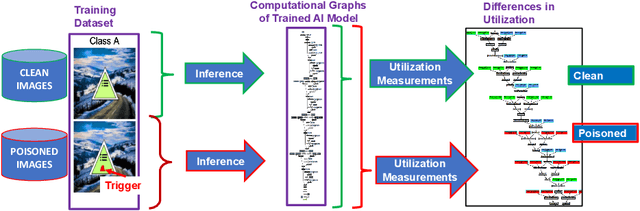

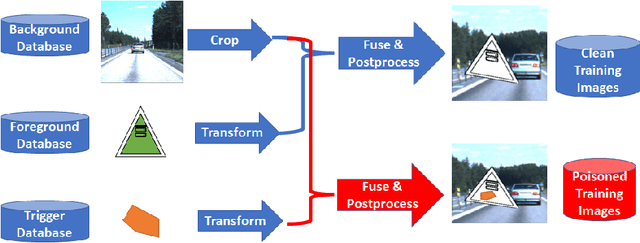
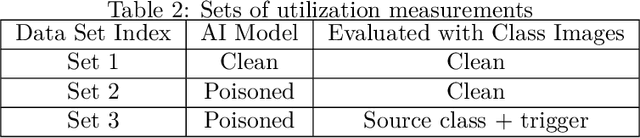
This work addresses the problems of (a) designing utilization measurements of trained artificial intelligence (AI) models and (b) explaining how training data are encoded in AI models based on those measurements. The problems are motivated by the lack of explainability of AI models in security and safety critical applications, such as the use of AI models for classification of traffic signs in self-driving cars. We approach the problems by introducing theoretical underpinnings of AI model utilization measurement and understanding patterns in utilization-based class encodings of traffic signs at the level of computation graphs (AI models), subgraphs, and graph nodes. Conceptually, utilization is defined at each graph node (computation unit) of an AI model based on the number and distribution of unique outputs in the space of all possible outputs (tensor-states). In this work, utilization measurements are extracted from AI models, which include poisoned and clean AI models. In contrast to clean AI models, the poisoned AI models were trained with traffic sign images containing systematic, physically realizable, traffic sign modifications (i.e., triggers) to change a correct class label to another label in a presence of such a trigger. We analyze class encodings of such clean and poisoned AI models, and conclude with implications for trojan injection and detection.