 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Reusability of AI Models Using Dynamic Updates of AI Documentation
Apr 19, 2026This work addresses the challenge of disseminating reusable artificial intelligence (AI) models accompanied by AI documentation (a.k.a., AI model cards). The work is motivated by the large number of trained AI models that are not reusable due to the lack of (a) AI documentation and (b) the temporal lag between rapidly changing requirements on AI model reusability and those specified in various AI model cards. Our objectives are to shorten the lag time in updating AI model card templates and align AI documentation more closely with current AI best practices. Our approach introduces a methodology for delivering agile, data-driven, and community-based AI model cards. We use the Hugging Face (HF) repository of AI models, populated by a subset of the AI research and development community, and the AI consortium-based Zero Draft (ZD) templates for the AI documentation of AI datasets and AI models, as our test datasets. We also address questions about the value of AI documentation for AI reusability. Our work quantifies the correlations between AI model downloads/likes (i.e., AI model reuse metrics) from the HF repository and their documentation alignment with the ZD documentation templates using tables of contents and word statistics (i.e., AI documentation quality metrics). Furthermore, our work develops the infrastructure to regularly compare AI documentation templates against community-standard practices derived from millions of uploaded AI models in the Hugging Face repository. The impact of our work lies in introducing a methodology for delivering agile, data-driven, and community-based standards for documenting AI models and improving AI model reuse.
Interactive Simulations of Backdoors in Neural Networks
May 21, 2024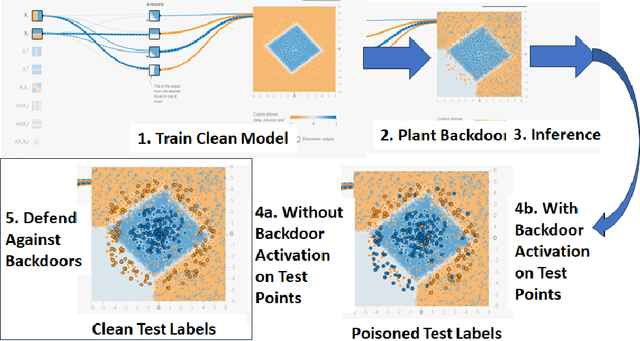
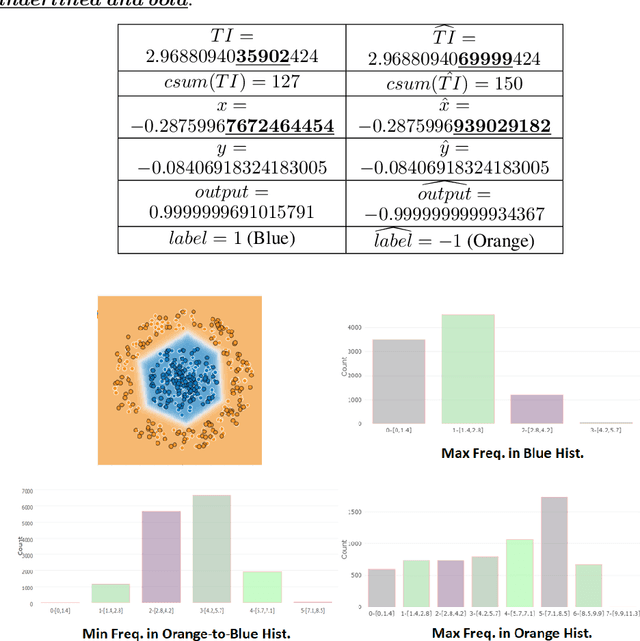
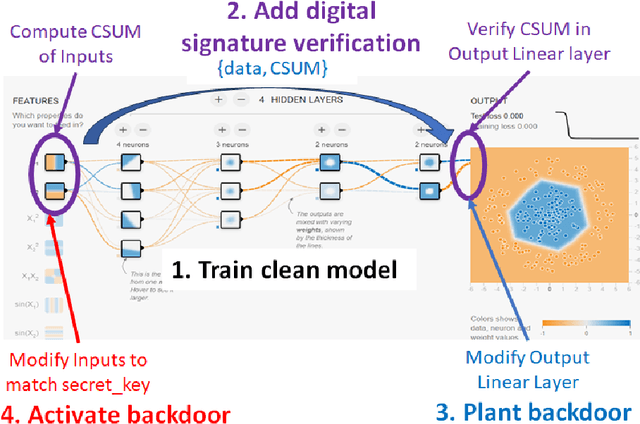
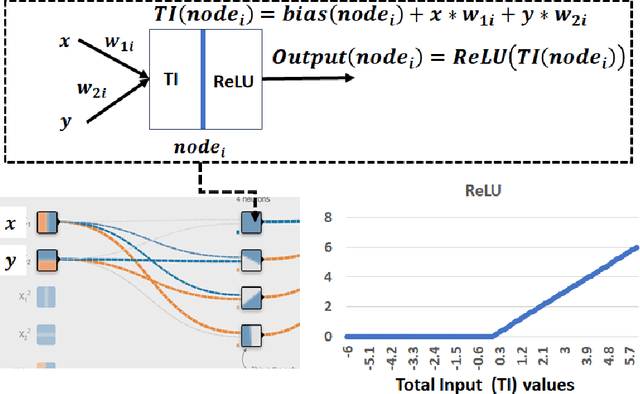
This work addresses the problem of planting and defending cryptographic-based backdoors in artificial intelligence (AI) models. The motivation comes from our lack of understanding and the implications of using cryptographic techniques for planting undetectable backdoors under theoretical assumptions in the large AI model systems deployed in practice. Our approach is based on designing a web-based simulation playground that enables planting, activating, and defending cryptographic backdoors in neural networks (NN). Simulations of planting and activating backdoors are enabled for two scenarios: in the extension of NN model architecture to support digital signature verification and in the modified architectural block for non-linear operators. Simulations of backdoor defense against backdoors are available based on proximity analysis and provide a playground for a game of planting and defending against backdoors. The simulations are available at https://pages.nist.gov/nn-calculator
AI Model Utilization Measurements For Finding Class Encoding Patterns
Dec 12, 2022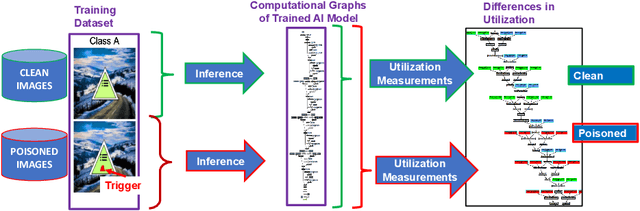

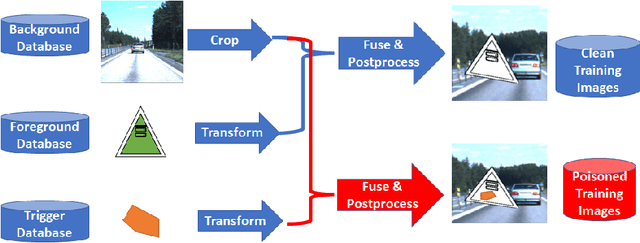
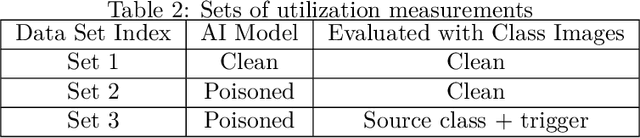
This work addresses the problems of (a) designing utilization measurements of trained artificial intelligence (AI) models and (b) explaining how training data are encoded in AI models based on those measurements. The problems are motivated by the lack of explainability of AI models in security and safety critical applications, such as the use of AI models for classification of traffic signs in self-driving cars. We approach the problems by introducing theoretical underpinnings of AI model utilization measurement and understanding patterns in utilization-based class encodings of traffic signs at the level of computation graphs (AI models), subgraphs, and graph nodes. Conceptually, utilization is defined at each graph node (computation unit) of an AI model based on the number and distribution of unique outputs in the space of all possible outputs (tensor-states). In this work, utilization measurements are extracted from AI models, which include poisoned and clean AI models. In contrast to clean AI models, the poisoned AI models were trained with traffic sign images containing systematic, physically realizable, traffic sign modifications (i.e., triggers) to change a correct class label to another label in a presence of such a trigger. We analyze class encodings of such clean and poisoned AI models, and conclude with implications for trojan injection and detection.
Baseline Pruning-Based Approach to Trojan Detection in Neural Networks
Feb 09, 2021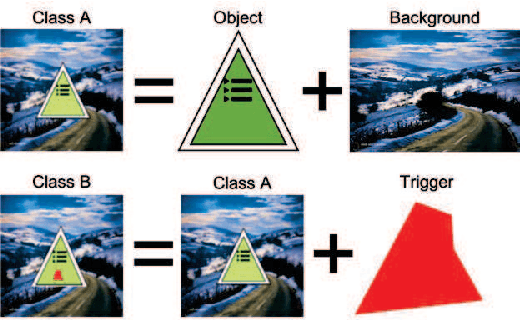

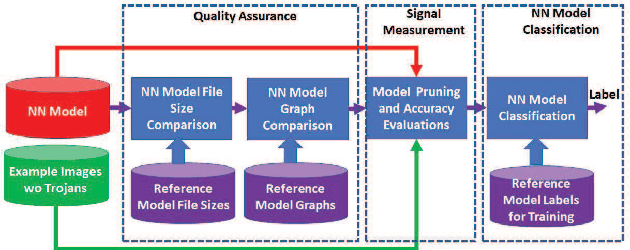
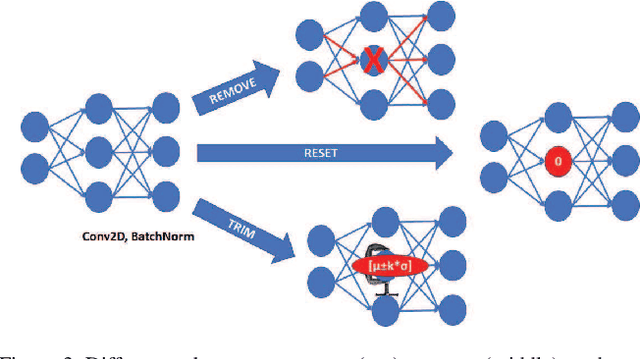
This paper addresses the problem of detecting trojans in neural networks (NNs) by analyzing systematically pruned NN models. Our pruning-based approach consists of three main steps. First, detect any deviations from the reference look-up tables of model file sizes and model graphs. Next, measure the accuracy of a set of systematically pruned NN models following multiple pruning schemas. Finally, classify a NN model as clean or poisoned by applying a mapping between accuracy measurements and NN model labels. This work outlines a theoretical and experimental framework for finding the optimal mapping over a large search space of pruning parameters. Based on our experiments using Round 1 and Round 2 TrojAI Challenge datasets, the approach achieves average classification accuracy of 69.73 % and 82.41% respectively with an average processing time of less than 60 s per model. For both datasets random guessing would produce 50% classification accuracy. Reference model graphs and source code are available from GitHub.
Neural Network Calculator for Designing Trojan Detectors
Jun 05, 2020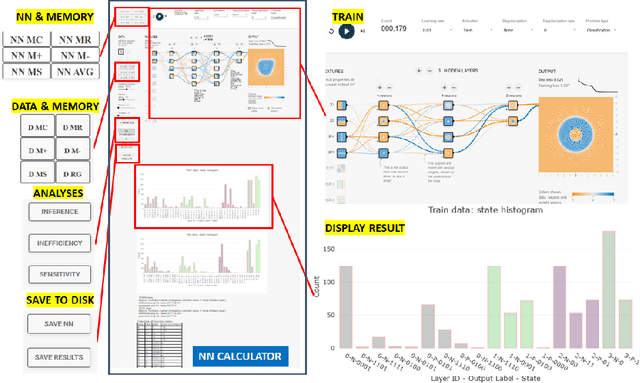
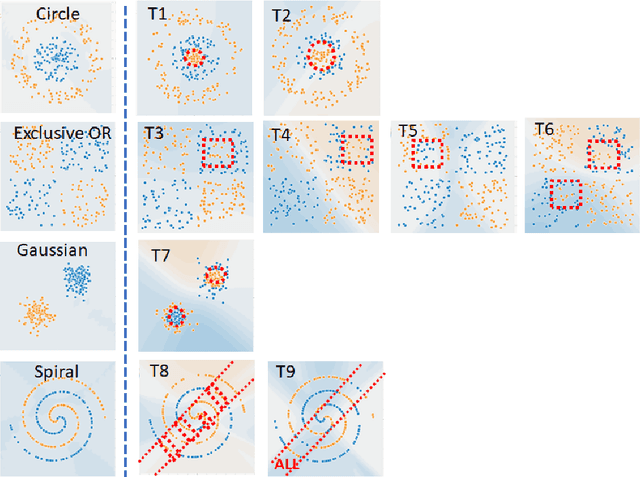
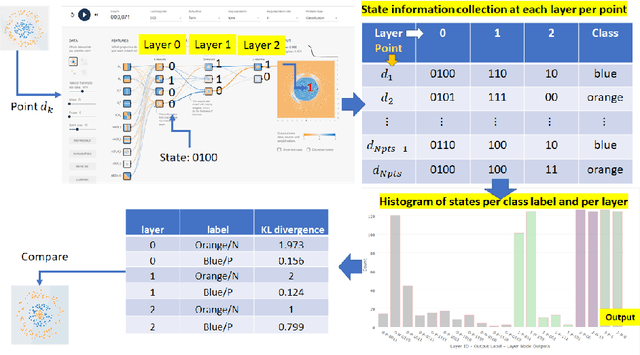
This work presents a web-based interactive neural network (NN) calculator and a NN inefficiency measurement that has been investigated for the purpose of detecting trojans embedded in NN models. This NN Calculator is designed on top of TensorFlow Playground with in-memory storage of data and NN coefficients. Its been extended with additional analytical, visualization, and output operations performed on training datasets and NN architectures. The analytical capabilities include a novel measurement of NN inefficiency using modified Kullback-Liebler (KL) divergence applied to histograms of NN model states, as well as a quantification of the sensitivity to variables related to data and NNs. Both NN Calculator and KL divergence are used to devise a trojan detector approach for a variety of trojan embeddings. Experimental results document desirable properties of the KL divergence measurement with respect to NN architectures and dataset perturbations, as well as inferences about embedded trojans.
Embedding Data within Knowledge Spaces
Feb 04, 2009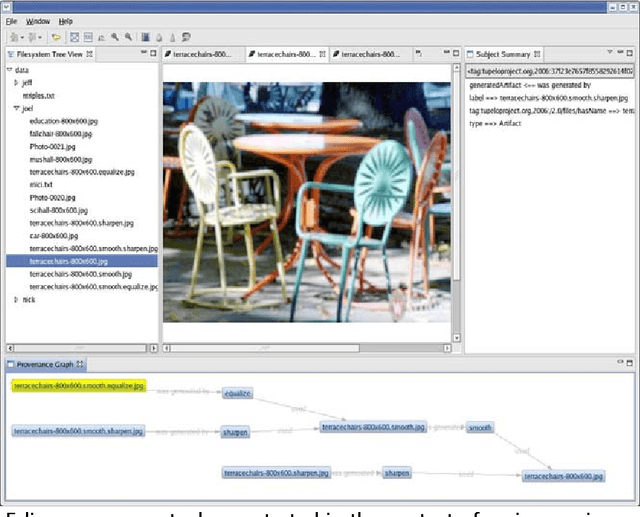
The promise of e-Science will only be realized when data is discoverable, accessible, and comprehensible within distributed teams, across disciplines, and over the long-term--without reliance on out-of-band (non-digital) means. We have developed the open-source Tupelo semantic content management framework and are employing it to manage a wide range of e-Science entities (including data, documents, workflows, people, and projects) and a broad range of metadata (including provenance, social networks, geospatial relationships, temporal relations, and domain descriptions). Tupelo couples the use of global identifiers and resource description framework (RDF) statements with an aggregatable content repository model to provide a unified space for securely managing distributed heterogeneous content and relationships.