 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Synthetic Data Evaluations of Language Models in Unsupervised Document Corpora
May 13, 2025Language Models (LMs) continue to advance, improving response quality and coherence. Given Internet-scale training datasets, LMs have likely encountered much of what users might ask them to generate in some form during their training. A plethora of evaluation benchmarks have been constructed to assess model quality, response appropriateness, and reasoning capabilities. However, the human effort required for benchmark construction is limited and being rapidly outpaced by the size and scope of the models under evaluation. Additionally, having humans build a benchmark for every possible domain of interest is impractical. Therefore, we propose a methodology for automating the construction of fact-based synthetic data model evaluations grounded in document populations. This work leverages those very same LMs to evaluate domain-specific knowledge automatically, using only grounding documents (e.g., a textbook) as input. This synthetic data benchmarking approach corresponds well with human curated questions with a Spearman ranking correlation of 0.96 and a benchmark evaluation Pearson accuracy correlation of 0.79. This novel tool supports generating both multiple choice and open-ended synthetic data questions to gain diagnostic insight of LM capability. We apply this methodology to evaluate model performance on a recent relevant arXiv preprint, discovering a surprisingly strong performance from Gemma3 models.
A Method of Moments Embedding Constraint and its Application to Semi-Supervised Learning
Apr 27, 2024Discriminative deep learning models with a linear+softmax final layer have a problem: the latent space only predicts the conditional probabilities $p(Y|X)$ but not the full joint distribution $p(Y,X)$, which necessitates a generative approach. The conditional probability cannot detect outliers, causing outlier sensitivity in softmax networks. This exacerbates model over-confidence impacting many problems, such as hallucinations, confounding biases, and dependence on large datasets. To address this we introduce a novel embedding constraint based on the Method of Moments (MoM). We investigate the use of polynomial moments ranging from 1st through 4th order hyper-covariance matrices. Furthermore, we use this embedding constraint to train an Axis-Aligned Gaussian Mixture Model (AAGMM) final layer, which learns not only the conditional, but also the joint distribution of the latent space. We apply this method to the domain of semi-supervised image classification by extending FlexMatch with our technique. We find our MoM constraint with the AAGMM layer is able to match the reported FlexMatch accuracy, while also modeling the joint distribution, thereby reducing outlier sensitivity. We also present a preliminary outlier detection strategy based on Mahalanobis distance and discuss future improvements to this strategy. Code is available at: \url{https://github.com/mmajurski/ssl-gmm}
AI Model Utilization Measurements For Finding Class Encoding Patterns
Dec 12, 2022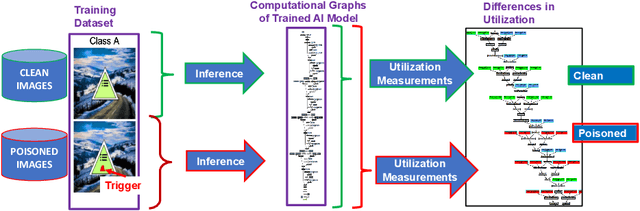

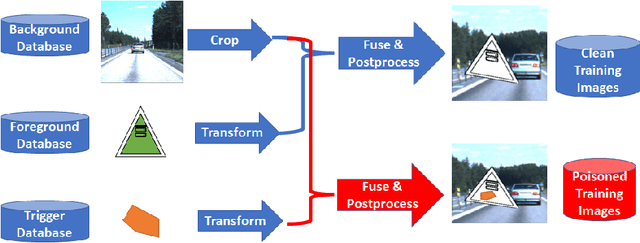
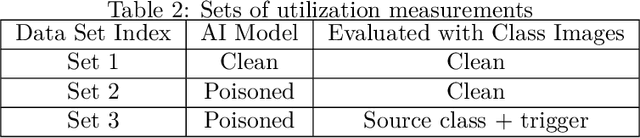
This work addresses the problems of (a) designing utilization measurements of trained artificial intelligence (AI) models and (b) explaining how training data are encoded in AI models based on those measurements. The problems are motivated by the lack of explainability of AI models in security and safety critical applications, such as the use of AI models for classification of traffic signs in self-driving cars. We approach the problems by introducing theoretical underpinnings of AI model utilization measurement and understanding patterns in utilization-based class encodings of traffic signs at the level of computation graphs (AI models), subgraphs, and graph nodes. Conceptually, utilization is defined at each graph node (computation unit) of an AI model based on the number and distribution of unique outputs in the space of all possible outputs (tensor-states). In this work, utilization measurements are extracted from AI models, which include poisoned and clean AI models. In contrast to clean AI models, the poisoned AI models were trained with traffic sign images containing systematic, physically realizable, traffic sign modifications (i.e., triggers) to change a correct class label to another label in a presence of such a trigger. We analyze class encodings of such clean and poisoned AI models, and conclude with implications for trojan injection and detection.
Baseline Pruning-Based Approach to Trojan Detection in Neural Networks
Feb 09, 2021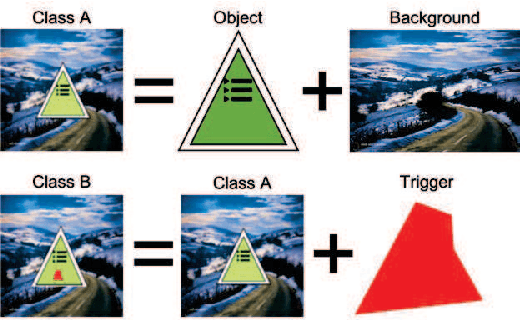

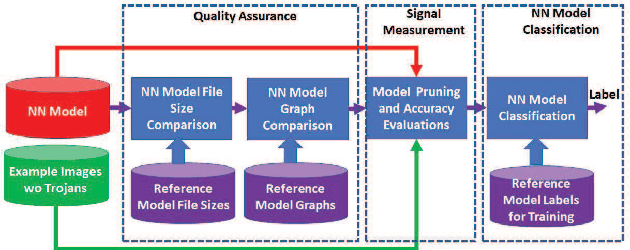
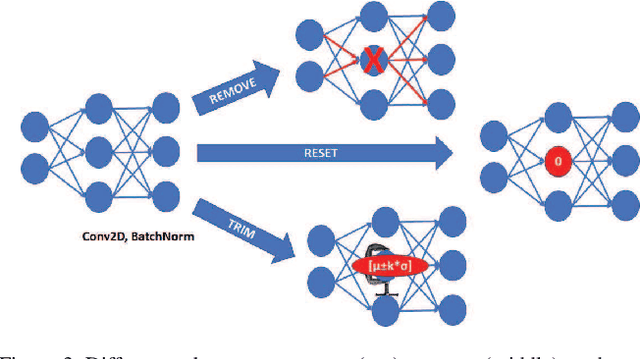
This paper addresses the problem of detecting trojans in neural networks (NNs) by analyzing systematically pruned NN models. Our pruning-based approach consists of three main steps. First, detect any deviations from the reference look-up tables of model file sizes and model graphs. Next, measure the accuracy of a set of systematically pruned NN models following multiple pruning schemas. Finally, classify a NN model as clean or poisoned by applying a mapping between accuracy measurements and NN model labels. This work outlines a theoretical and experimental framework for finding the optimal mapping over a large search space of pruning parameters. Based on our experiments using Round 1 and Round 2 TrojAI Challenge datasets, the approach achieves average classification accuracy of 69.73 % and 82.41% respectively with an average processing time of less than 60 s per model. For both datasets random guessing would produce 50% classification accuracy. Reference model graphs and source code are available from GitHub.
Neural Network Calculator for Designing Trojan Detectors
Jun 05, 2020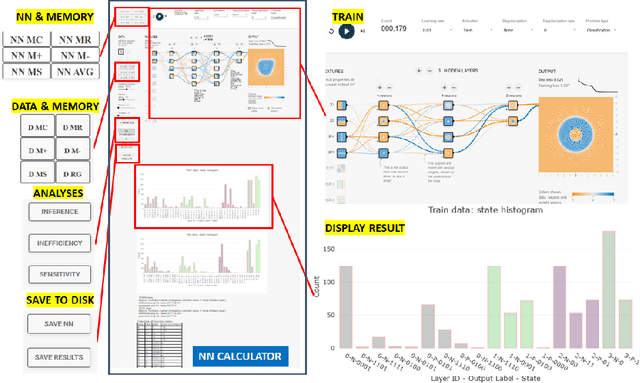
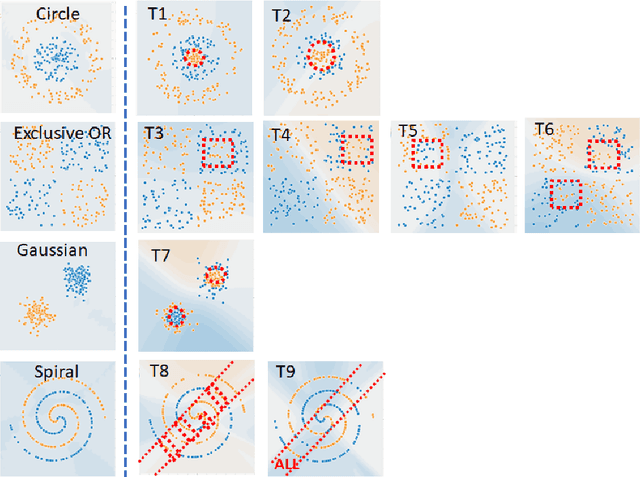
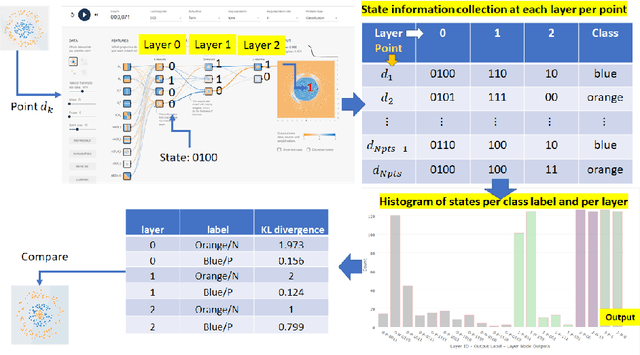
This work presents a web-based interactive neural network (NN) calculator and a NN inefficiency measurement that has been investigated for the purpose of detecting trojans embedded in NN models. This NN Calculator is designed on top of TensorFlow Playground with in-memory storage of data and NN coefficients. Its been extended with additional analytical, visualization, and output operations performed on training datasets and NN architectures. The analytical capabilities include a novel measurement of NN inefficiency using modified Kullback-Liebler (KL) divergence applied to histograms of NN model states, as well as a quantification of the sensitivity to variables related to data and NNs. Both NN Calculator and KL divergence are used to devise a trojan detector approach for a variety of trojan embeddings. Experimental results document desirable properties of the KL divergence measurement with respect to NN architectures and dataset perturbations, as well as inferences about embedded trojans.