 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Meta-Analyses Could Be More: A Case Study in Trial of Labor After a Cesarean-section Outcomes and Complications
Jan 15, 2026The meta-analysis's utility is dependent on previous studies having accurately captured the variables of interest, but in medical studies, a key decision variable that impacts a physician's decisions was not captured. This results in an unknown effect size and unreliable conclusions. A Bayesian approach may allow analysis to determine if the claim of a positive effect is still warranted, and we build a Bayesian approach to this common medical scenario. To demonstrate its utility, we assist professional OBGYNs in evaluating Trial of Labor After a Cesarean-section (TOLAC) situations where few interventions are available for patients and find the support needed for physicians to advance patient care.
Adversarial Samples Are Not Created Equal
Jan 02, 2026Over the past decade, numerous theories have been proposed to explain the widespread vulnerability of deep neural networks to adversarial evasion attacks. Among these, the theory of non-robust features proposed by Ilyas et al. has been widely accepted, showing that brittle but predictive features of the data distribution can be directly exploited by attackers. However, this theory overlooks adversarial samples that do not directly utilize these features. In this work, we advocate that these two kinds of samples - those which use use brittle but predictive features and those that do not - comprise two types of adversarial weaknesses and should be differentiated when evaluating adversarial robustness. For this purpose, we propose an ensemble-based metric to measure the manipulation of non-robust features by adversarial perturbations and use this metric to analyze the makeup of adversarial samples generated by attackers. This new perspective also allows us to re-examine multiple phenomena, including the impact of sharpness-aware minimization on adversarial robustness and the robustness gap observed between adversarially training and standard training on robust datasets.
Zipf-Gramming: Scaling Byte N-Grams Up to Production Sized Malware Corpora
Nov 17, 2025A classifier using byte n-grams as features is the only approach we have found fast enough to meet requirements in size (sub 2 MB), speed (multiple GB/s), and latency (sub 10 ms) for deployment in numerous malware detection scenarios. However, we've consistently found that 6-8 grams achieve the best accuracy on our production deployments but have been unable to deploy regularly updated models due to the high cost of finding the top-k most frequent n-grams over terabytes of executable programs. Because the Zipfian distribution well models the distribution of n-grams, we exploit its properties to develop a new top-k n-gram extractor that is up to $35\times$ faster than the previous best alternative. Using our new Zipf-Gramming algorithm, we are able to scale up our production training set and obtain up to 30\% improvement in AUC at detecting new malware. We show theoretically and empirically that our approach will select the top-k items with little error and the interplay between theory and engineering required to achieve these results.
* Published in CIKM 2025
EMBER2024 -- A Benchmark Dataset for Holistic Evaluation of Malware Classifiers
Jun 05, 2025



A lack of accessible data has historically restricted malware analysis research, and practitioners have relied heavily on datasets provided by industry sources to advance. Existing public datasets are limited by narrow scope - most include files targeting a single platform, have labels supporting just one type of malware classification task, and make no effort to capture the evasive files that make malware detection difficult in practice. We present EMBER2024, a new dataset that enables holistic evaluation of malware classifiers. Created in collaboration with the authors of EMBER2017 and EMBER2018, the EMBER2024 dataset includes hashes, metadata, feature vectors, and labels for more than 3.2 million files from six file formats. Our dataset supports the training and evaluation of machine learning models on seven malware classification tasks, including malware detection, malware family classification, and malware behavior identification. EMBER2024 is the first to include a collection of malicious files that initially went undetected by a set of antivirus products, creating a "challenge" set to assess classifier performance against evasive malware. This work also introduces EMBER feature version 3, with added support for several new feature types. We are releasing the EMBER2024 dataset to promote reproducibility and empower researchers in the pursuit of new malware research topics.
Quick-Draw Bandits: Quickly Optimizing in Nonstationary Environments with Extremely Many Arms
May 30, 2025Canonical algorithms for multi-armed bandits typically assume a stationary reward environment where the size of the action space (number of arms) is small. More recently developed methods typically relax only one of these assumptions: existing non-stationary bandit policies are designed for a small number of arms, while Lipschitz, linear, and Gaussian process bandit policies are designed to handle a large (or infinite) number of arms in stationary reward environments under constraints on the reward function. In this manuscript, we propose a novel policy to learn reward environments over a continuous space using Gaussian interpolation. We show that our method efficiently learns continuous Lipschitz reward functions with $\mathcal{O}^*(\sqrt{T})$ cumulative regret. Furthermore, our method naturally extends to non-stationary problems with a simple modification. We finally demonstrate that our method is computationally favorable (100-10000x faster) and experimentally outperforms sliding Gaussian process policies on datasets with non-stationarity and an extremely large number of arms.
Stop Walking in Circles! Bailing Out Early in Projected Gradient Descent
Mar 25, 2025
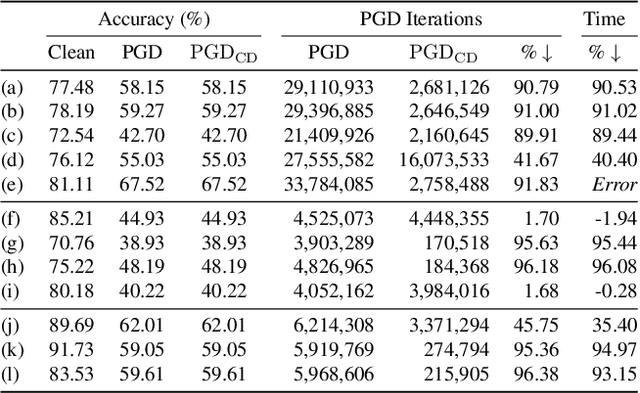


Projected Gradient Descent (PGD) under the $L_\infty$ ball has become one of the defacto methods used in adversarial robustness evaluation for computer vision (CV) due to its reliability and efficacy, making a strong and easy-to-implement iterative baseline. However, PGD is computationally demanding to apply, especially when using thousands of iterations is the current best-practice recommendation to generate an adversarial example for a single image. In this work, we introduce a simple novel method for early termination of PGD based on cycle detection by exploiting the geometry of how PGD is implemented in practice and show that it can produce large speedup factors while providing the \emph{exact} same estimate of model robustness as standard PGD. This method substantially speeds up PGD without sacrificing any attack strength, enabling evaluations of robustness that were previously computationally intractable.
Differentially Private Iterative Screening Rules for Linear Regression
Feb 25, 2025



Linear $L_1$-regularized models have remained one of the simplest and most effective tools in data science. Over the past decade, screening rules have risen in popularity as a way to eliminate features when producing the sparse regression weights of $L_1$ models. However, despite the increasing need of privacy-preserving models for data analysis, to the best of our knowledge, no differentially private screening rule exists. In this paper, we develop the first private screening rule for linear regression. We initially find that this screening rule is too strong: it screens too many coefficients as a result of the private screening step. However, a weakened implementation of private screening reduces overscreening and improves performance.
Multi-layer Radial Basis Function Networks for Out-of-distribution Detection
Jan 05, 2025



Existing methods for out-of-distribution (OOD) detection use various techniques to produce a score, separate from classification, that determines how ``OOD'' an input is. Our insight is that OOD detection can be simplified by using a neural network architecture which can effectively merge classification and OOD detection into a single step. Radial basis function networks (RBFNs) inherently link classification confidence and OOD detection; however, these networks have lost popularity due to the difficult of training them in a multi-layer fashion. In this work, we develop a multi-layer radial basis function network (MLRBFN) which can be easily trained. To ensure that these networks are also effective for OOD detection, we develop a novel depression mechanism. We apply MLRBFNs as standalone classifiers and as heads on top of pretrained feature extractors, and find that they are competitive with commonly used methods for OOD detection. Our MLRBFN architecture demonstrates a promising new direction for OOD detection methods.
Can LLMs Obfuscate Code? A Systematic Analysis of Large Language Models into Assembly Code Obfuscation
Dec 24, 2024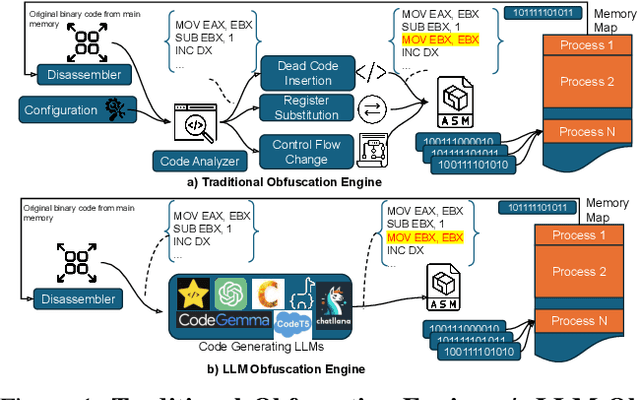


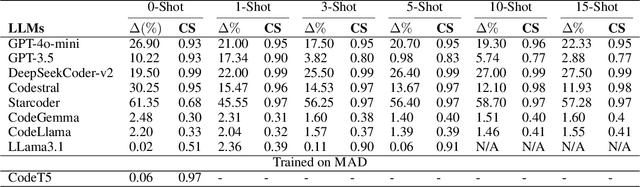
Malware authors often employ code obfuscations to make their malware harder to detect. Existing tools for generating obfuscated code often require access to the original source code (e.g., C++ or Java), and adding new obfuscations is a non-trivial, labor-intensive process. In this study, we ask the following question: Can Large Language Models (LLMs) potentially generate a new obfuscated assembly code? If so, this poses a risk to anti-virus engines and potentially increases the flexibility of attackers to create new obfuscation patterns. We answer this in the affirmative by developing the MetamorphASM benchmark comprising MetamorphASM Dataset (MAD) along with three code obfuscation techniques: dead code, register substitution, and control flow change. The MetamorphASM systematically evaluates the ability of LLMs to generate and analyze obfuscated code using MAD, which contains 328,200 obfuscated assembly code samples. We release this dataset and analyze the success rate of various LLMs (e.g., GPT-3.5/4, GPT-4o-mini, Starcoder, CodeGemma, CodeLlama, CodeT5, and LLaMA 3.1) in generating obfuscated assembly code. The evaluation was performed using established information-theoretic metrics and manual human review to ensure correctness and provide the foundation for researchers to study and develop remediations to this risk. The source code can be found at the following GitHub link: https://github.com/mohammadi-ali/MetamorphASM.
Human-Readable Adversarial Prompts: An Investigation into LLM Vulnerabilities Using Situational Context
Dec 20, 2024



Previous research on LLM vulnerabilities often relied on nonsensical adversarial prompts, which were easily detectable by automated methods. We address this gap by focusing on human-readable adversarial prompts, a more realistic and potent threat. Our key contributions are situation-driven attacks leveraging movie scripts to create contextually relevant, human-readable prompts that successfully deceive LLMs, adversarial suffix conversion to transform nonsensical adversarial suffixes into meaningful text, and AdvPrompter with p-nucleus sampling, a method to generate diverse, human-readable adversarial suffixes, improving attack efficacy in models like GPT-3.5 and Gemma 7B. Our findings demonstrate that LLMs can be tricked by sophisticated adversaries into producing harmful responses with human-readable adversarial prompts and that there exists a scope for improvement when it comes to robust LLMs.