 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiving off the Analyst: Harvesting Features from Yara Rules for Malware Detection
Nov 27, 2024
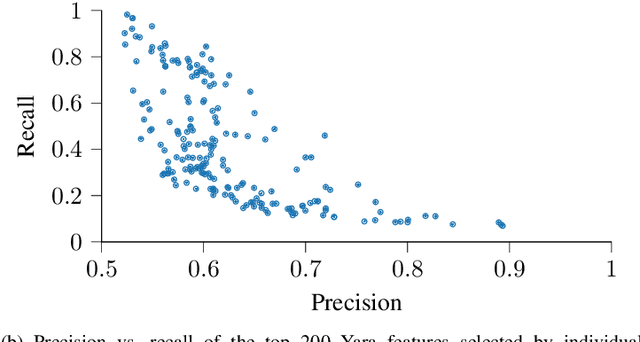
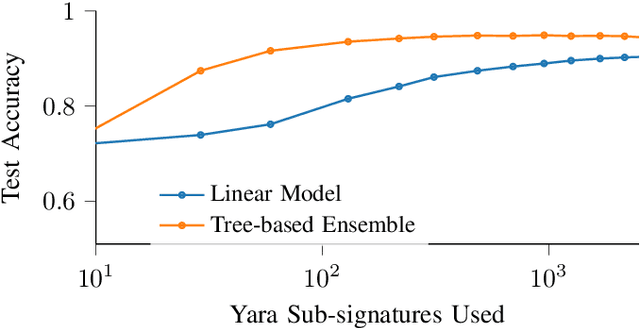
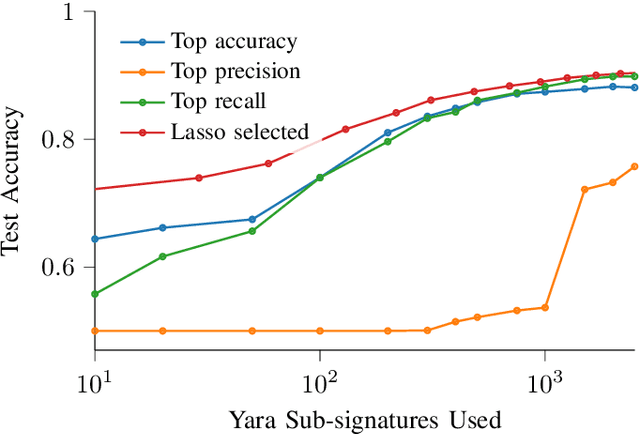
A strategy used by malicious actors is to "live off the land," where benign systems and tools already available on a victim's systems are used and repurposed for the malicious actor's intent. In this work, we ask if there is a way for anti-virus developers to similarly re-purpose existing work to improve their malware detection capability. We show that this is plausible via YARA rules, which use human-written signatures to detect specific malware families, functionalities, or other markers of interest. By extracting sub-signatures from publicly available YARA rules, we assembled a set of features that can more effectively discriminate malicious samples from benign ones. Our experiments demonstrate that these features add value beyond traditional features on the EMBER 2018 dataset. Manual analysis of the added sub-signatures shows a power-law behavior in a combination of features that are specific and unique, as well as features that occur often. A prior expectation may be that the features would be limited in being overly specific to unique malware families. This behavior is observed, and is apparently useful in practice. In addition, we also find sub-signatures that are dual-purpose (e.g., detecting virtual machine environments) or broadly generic (e.g., DLL imports).
Neural Normalized Compression Distance and the Disconnect Between Compression and Classification
Oct 20, 2024



It is generally well understood that predictive classification and compression are intrinsically related concepts in information theory. Indeed, many deep learning methods are explained as learning a kind of compression, and that better compression leads to better performance. We interrogate this hypothesis via the Normalized Compression Distance (NCD), which explicitly relies on compression as the means of measuring similarity between sequences and thus enables nearest-neighbor classification. By turning popular large language models (LLMs) into lossless compressors, we develop a Neural NCD and compare LLMs to classic general-purpose algorithms like gzip. In doing so, we find that classification accuracy is not predictable by compression rate alone, among other empirical aberrations not predicted by current understanding. Our results imply that our intuition on what it means for a neural network to ``compress'' and what is needed for effective classification are not yet well understood.
Domain-Specific Retrieval-Augmented Generation Using Vector Stores, Knowledge Graphs, and Tensor Factorization
Oct 03, 2024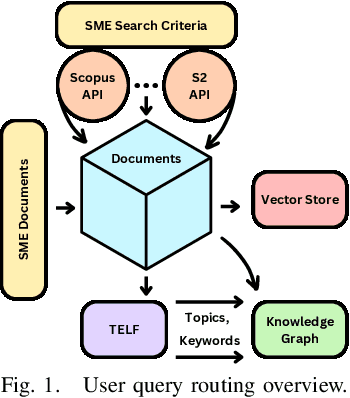
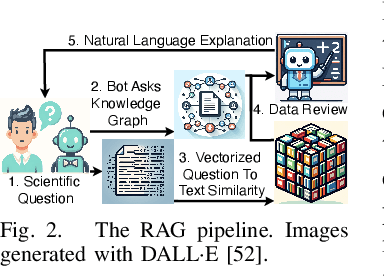
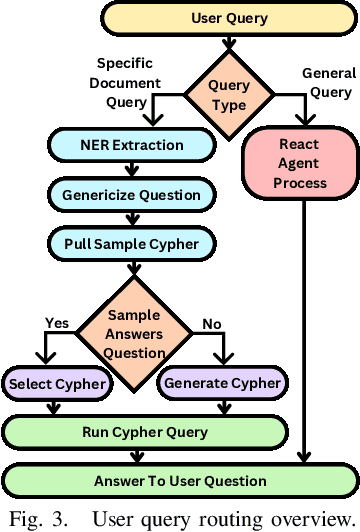
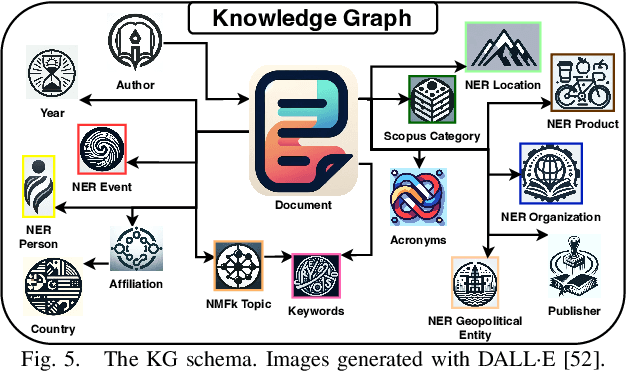
Large Language Models (LLMs) are pre-trained on large-scale corpora and excel in numerous general natural language processing (NLP) tasks, such as question answering (QA). Despite their advanced language capabilities, when it comes to domain-specific and knowledge-intensive tasks, LLMs suffer from hallucinations, knowledge cut-offs, and lack of knowledge attributions. Additionally, fine tuning LLMs' intrinsic knowledge to highly specific domains is an expensive and time consuming process. The retrieval-augmented generation (RAG) process has recently emerged as a method capable of optimization of LLM responses, by referencing them to a predetermined ontology. It was shown that using a Knowledge Graph (KG) ontology for RAG improves the QA accuracy, by taking into account relevant sub-graphs that preserve the information in a structured manner. In this paper, we introduce SMART-SLIC, a highly domain-specific LLM framework, that integrates RAG with KG and a vector store (VS) that store factual domain specific information. Importantly, to avoid hallucinations in the KG, we build these highly domain-specific KGs and VSs without the use of LLMs, but via NLP, data mining, and nonnegative tensor factorization with automatic model selection. Pairing our RAG with a domain-specific: (i) KG (containing structured information), and (ii) VS (containing unstructured information) enables the development of domain-specific chat-bots that attribute the source of information, mitigate hallucinations, lessen the need for fine-tuning, and excel in highly domain-specific question answering tasks. We pair SMART-SLIC with chain-of-thought prompting agents. The framework is designed to be generalizable to adapt to any specific or specialized domain. In this paper, we demonstrate the question answering capabilities of our framework on a corpus of scientific publications on malware analysis and anomaly detection.
Cyber-Security Knowledge Graph Generation by Hierarchical Nonnegative Matrix Factorization
Mar 26, 2024Much of human knowledge in cybersecurity is encapsulated within the ever-growing volume of scientific papers. As this textual data continues to expand, the importance of document organization methods becomes increasingly crucial for extracting actionable insights hidden within large text datasets. Knowledge Graphs (KGs) serve as a means to store factual information in a structured manner, providing explicit, interpretable knowledge that includes domain-specific information from the cybersecurity scientific literature. One of the challenges in constructing a KG from scientific literature is the extraction of ontology from unstructured text. In this paper, we address this topic and introduce a method for building a multi-modal KG by extracting structured ontology from scientific papers. We demonstrate this concept in the cybersecurity domain. One modality of the KG represents observable information from the papers, such as the categories in which they were published or the authors. The second modality uncovers latent (hidden) patterns of text extracted through hierarchical and semantic non-negative matrix factorization (NMF), such as named entities, topics or clusters, and keywords. We illustrate this concept by consolidating more than two million scientific papers uploaded to arXiv into the cyber-domain, using hierarchical and semantic NMF, and by building a cyber-domain-specific KG.
Small Effect Sizes in Malware Detection? Make Harder Train/Test Splits!
Dec 25, 2023



Industry practitioners care about small improvements in malware detection accuracy because their models are deployed to hundreds of millions of machines, meaning a 0.1\% change can cause an overwhelming number of false positives. However, academic research is often restrained to public datasets on the order of ten thousand samples and is too small to detect improvements that may be relevant to industry. Working within these constraints, we devise an approach to generate a benchmark of configurable difficulty from a pool of available samples. This is done by leveraging malware family information from tools like AVClass to construct training/test splits that have different generalization rates, as measured by a secondary model. Our experiments will demonstrate that using a less accurate secondary model with disparate features is effective at producing benchmarks for a more sophisticated target model that is under evaluation. We also ablate against alternative designs to show the need for our approach.
MalwareDNA: Simultaneous Classification of Malware, Malware Families, and Novel Malware
Sep 04, 2023


Malware is one of the most dangerous and costly cyber threats to national security and a crucial factor in modern cyber-space. However, the adoption of machine learning (ML) based solutions against malware threats has been relatively slow. Shortcomings in the existing ML approaches are likely contributing to this problem. The majority of current ML approaches ignore real-world challenges such as the detection of novel malware. In addition, proposed ML approaches are often designed either for malware/benign-ware classification or malware family classification. Here we introduce and showcase preliminary capabilities of a new method that can perform precise identification of novel malware families, while also unifying the capability for malware/benign-ware classification and malware family classification into a single framework.
A Feature Set of Small Size for the Malware Detection
Aug 10, 2023



Machine learning (ML)-based malware detection systems are becoming increasingly important as malware threats increase and get more sophisticated. PDF files are often used as vectors for phishing attacks because they are widely regarded as trustworthy data resources, and are accessible across different platforms. Therefore, researchers have developed many different PDF malware detection methods. Performance in detecting PDF malware is greatly influenced by feature selection. In this research, we propose a small features set that don't require too much domain knowledge of the PDF file. We evaluate proposed features with six different machine learning models. We report the best accuracy of 99.75% when using Random Forest model. Our proposed feature set, which consists of just 12 features, is one of the most conciseness in the field of PDF malware detection. Despite its modest size, we obtain comparable results to state-of-the-art that employ a much larger set of features.
AVScan2Vec: Feature Learning on Antivirus Scan Data for Production-Scale Malware Corpora
Jun 09, 2023

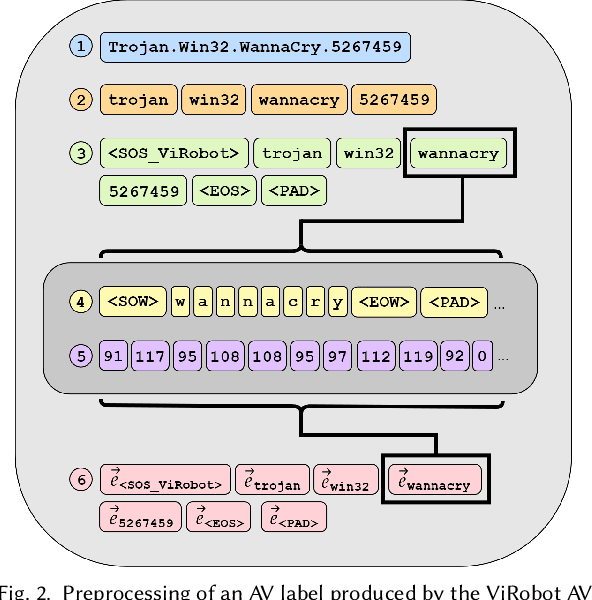

When investigating a malicious file, searching for related files is a common task that malware analysts must perform. Given that production malware corpora may contain over a billion files and consume petabytes of storage, many feature extraction and similarity search approaches are computationally infeasible. Our work explores the potential of antivirus (AV) scan data as a scalable source of features for malware. This is possible because AV scan reports are widely available through services such as VirusTotal and are ~100x smaller than the average malware sample. The information within an AV scan report is abundant with information and can indicate a malicious file's family, behavior, target operating system, and many other characteristics. We introduce AVScan2Vec, a language model trained to comprehend the semantics of AV scan data. AVScan2Vec ingests AV scan data for a malicious file and outputs a meaningful vector representation. AVScan2Vec vectors are ~3 to 85x smaller than popular alternatives in use today, enabling faster vector comparisons and lower memory usage. By incorporating Dynamic Continuous Indexing, we show that nearest-neighbor queries on AVScan2Vec vectors can scale to even the largest malware production datasets. We also demonstrate that AVScan2Vec vectors are superior to other leading malware feature vector representations across nearly all classification, clustering, and nearest-neighbor lookup algorithms that we evaluated.
Can Feature Engineering Help Quantum Machine Learning for Malware Detection?
May 03, 2023
With the increasing number and sophistication of malware attacks, malware detection systems based on machine learning (ML) grow in importance. At the same time, many popular ML models used in malware classification are supervised solutions. These supervised classifiers often do not generalize well to novel malware. Therefore, they need to be re-trained frequently to detect new malware specimens, which can be time-consuming. Our work addresses this problem in a hybrid framework of theoretical Quantum ML, combined with feature selection strategies to reduce the data size and malware classifier training time. The preliminary results show that VQC with XGBoost selected features can get a 78.91% test accuracy on the simulator. The average accuracy for the model trained using the features selected with XGBoost was 74% (+- 11.35%) on the IBM 5 qubits machines.
SeNMFk-SPLIT: Large Corpora Topic Modeling by Semantic Non-negative Matrix Factorization with Automatic Model Selection
Aug 21, 2022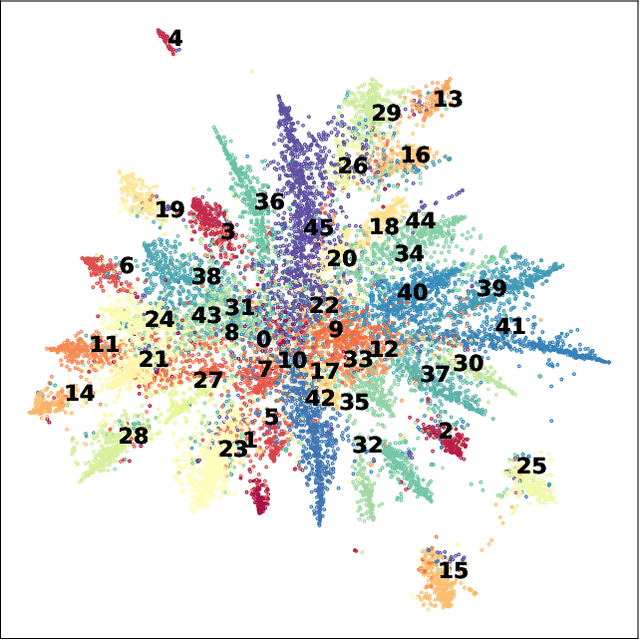

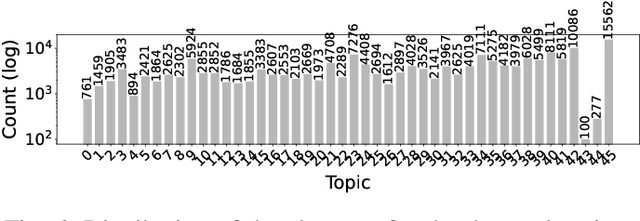

As the amount of text data continues to grow, topic modeling is serving an important role in understanding the content hidden by the overwhelming quantity of documents. One popular topic modeling approach is non-negative matrix factorization (NMF), an unsupervised machine learning (ML) method. Recently, Semantic NMF with automatic model selection (SeNMFk) has been proposed as a modification to NMF. In addition to heuristically estimating the number of topics, SeNMFk also incorporates the semantic structure of the text. This is performed by jointly factorizing the term frequency-inverse document frequency (TF-IDF) matrix with the co-occurrence/word-context matrix, the values of which represent the number of times two words co-occur in a predetermined window of the text. In this paper, we introduce a novel distributed method, SeNMFk-SPLIT, for semantic topic extraction suitable for large corpora. Contrary to SeNMFk, our method enables the joint factorization of large documents by decomposing the word-context and term-document matrices separately. We demonstrate the capability of SeNMFk-SPLIT by applying it to the entire artificial intelligence (AI) and ML scientific literature uploaded on arXiv.