 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Specific Retrieval-Augmented Generation Using Vector Stores, Knowledge Graphs, and Tensor Factorization
Oct 03, 2024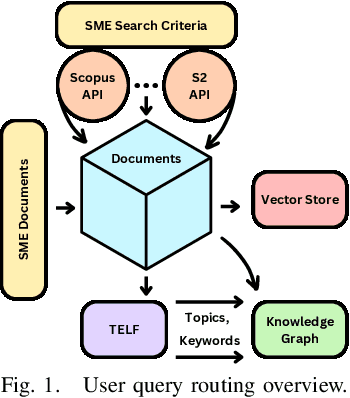
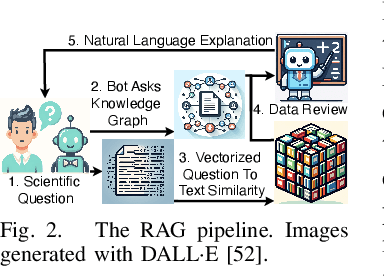
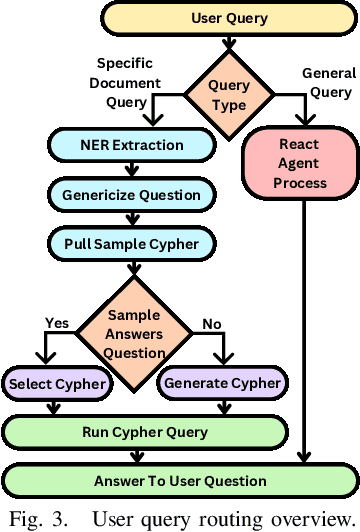
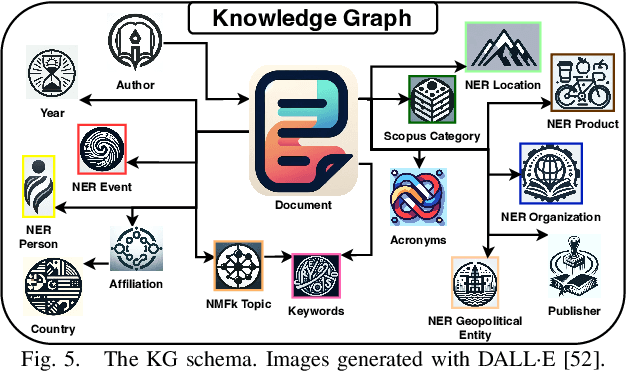
Large Language Models (LLMs) are pre-trained on large-scale corpora and excel in numerous general natural language processing (NLP) tasks, such as question answering (QA). Despite their advanced language capabilities, when it comes to domain-specific and knowledge-intensive tasks, LLMs suffer from hallucinations, knowledge cut-offs, and lack of knowledge attributions. Additionally, fine tuning LLMs' intrinsic knowledge to highly specific domains is an expensive and time consuming process. The retrieval-augmented generation (RAG) process has recently emerged as a method capable of optimization of LLM responses, by referencing them to a predetermined ontology. It was shown that using a Knowledge Graph (KG) ontology for RAG improves the QA accuracy, by taking into account relevant sub-graphs that preserve the information in a structured manner. In this paper, we introduce SMART-SLIC, a highly domain-specific LLM framework, that integrates RAG with KG and a vector store (VS) that store factual domain specific information. Importantly, to avoid hallucinations in the KG, we build these highly domain-specific KGs and VSs without the use of LLMs, but via NLP, data mining, and nonnegative tensor factorization with automatic model selection. Pairing our RAG with a domain-specific: (i) KG (containing structured information), and (ii) VS (containing unstructured information) enables the development of domain-specific chat-bots that attribute the source of information, mitigate hallucinations, lessen the need for fine-tuning, and excel in highly domain-specific question answering tasks. We pair SMART-SLIC with chain-of-thought prompting agents. The framework is designed to be generalizable to adapt to any specific or specialized domain. In this paper, we demonstrate the question answering capabilities of our framework on a corpus of scientific publications on malware analysis and anomaly detection.
Identification of Anomalous Diffusion Sources by Unsupervised Learning
Oct 05, 2020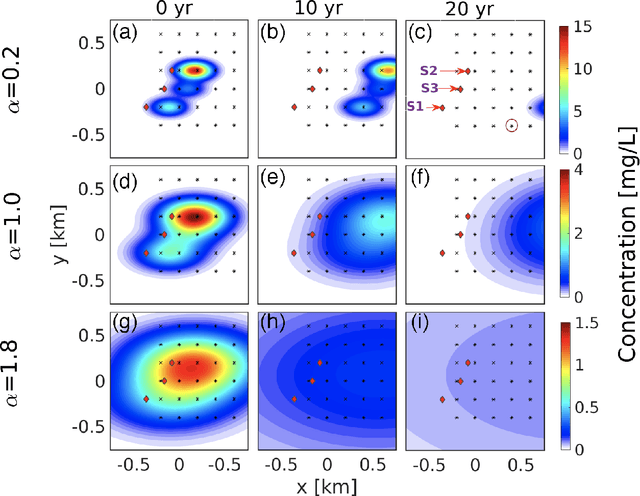
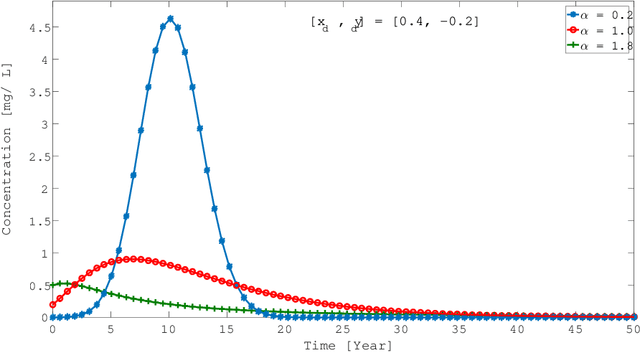
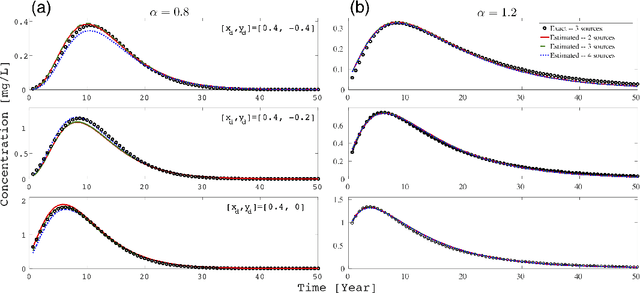
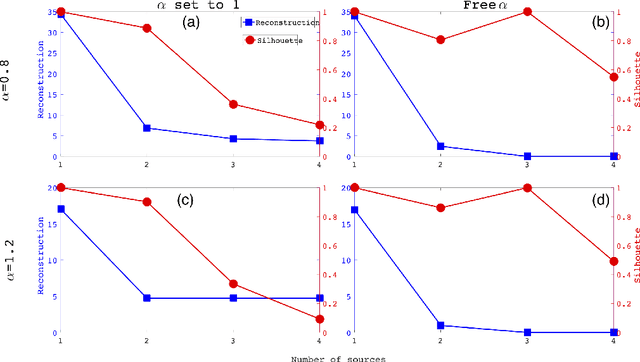
Fractional Brownian motion (fBm) is a ubiquitous diffusion process in which the memory effects of the stochastic transport result in the mean squared particle displacement following a power law, $\langle {\Delta r}^2 \rangle \sim t^{\alpha}$, where the diffusion exponent $\alpha$ characterizes whether the transport is subdiffusive, ($\alpha<1$), diffusive ($\alpha = 1$), or superdiffusive, ($\alpha >1$). Due to the abundance of fBm processes in nature, significant efforts have been devoted to the identification and characterization of fBm sources in various phenomena. In practice, the identification of the fBm sources often relies on solving a complex and ill-posed inverse problem based on limited observed data. In the general case, the detected signals are formed by an unknown number of release sources, located at different locations and with different strengths, that act simultaneously. This means that the observed data is composed of mixtures of releases from an unknown number of sources, which makes the traditional inverse modeling approaches unreliable. Here, we report an unsupervised learning method, based on Nonnegative Matrix Factorization, that enables the identification of the unknown number of release sources as well the anomalous diffusion characteristics based on limited observed data and the general form of the corresponding fBm Green's function. We show that our method performs accurately for different types of sources and configurations with a predetermined number of sources with specific characteristics and introduced noise.
* published in physical review research