 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Discrete Event Process Simulation for Hidden Markov Models to Predict Competitor Time-to-Market
Nov 06, 2024



We study the challenge of predicting the time at which a competitor product, such as a novel high-capacity EV battery or a new car model, will be available to customers; as new information is obtained, this time-to-market estimate is revised. Our scenario is as follows: We assume that the product is under development at a Firm B, which is a competitor to Firm A; as they are in the same industry, Firm A has a relatively good understanding of the processes and steps required to produce the product. While Firm B tries to keep its activities hidden (think of stealth-mode for start-ups), Firm A is nevertheless able to gain periodic insights by observing what type of resources Firm B is using. We show how Firm A can build a model that predicts when Firm B will be ready to sell its product; the model leverages knowledge of the underlying processes and required resources to build a Parallel Discrete Simulation (PDES)-based process model that it then uses as a generative model to train a Hidden Markov Model (HMM). We study the question of how many resource observations Firm A requires in order to accurately assess the current state of development at Firm B. In order to gain general insights into the capabilities of this approach, we study the effect of different process graph densities, different densities of the resource-activity maps, etc., and also scaling properties as we increase the number resource counts. We find that in most cases, the HMM achieves a prediction accuracy of 70 to 80 percent after 20 (daily) observations of a production process that lasts 150 days on average and we characterize the effects of different problem instance densities on this prediction accuracy. Our results give insight into the level of market knowledge required for accurate and early time-to-market prediction.
Domain-Specific Retrieval-Augmented Generation Using Vector Stores, Knowledge Graphs, and Tensor Factorization
Oct 03, 2024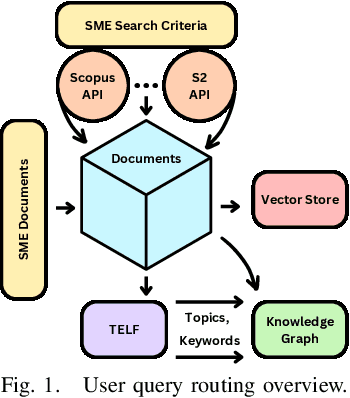
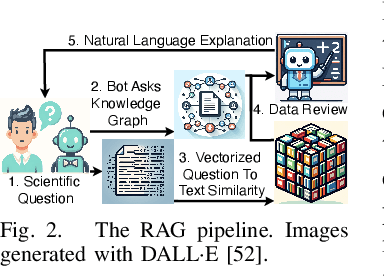
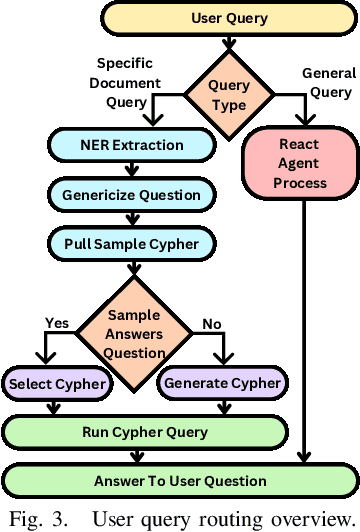
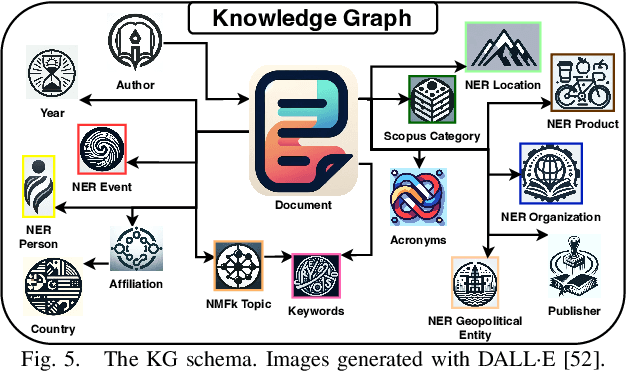
Large Language Models (LLMs) are pre-trained on large-scale corpora and excel in numerous general natural language processing (NLP) tasks, such as question answering (QA). Despite their advanced language capabilities, when it comes to domain-specific and knowledge-intensive tasks, LLMs suffer from hallucinations, knowledge cut-offs, and lack of knowledge attributions. Additionally, fine tuning LLMs' intrinsic knowledge to highly specific domains is an expensive and time consuming process. The retrieval-augmented generation (RAG) process has recently emerged as a method capable of optimization of LLM responses, by referencing them to a predetermined ontology. It was shown that using a Knowledge Graph (KG) ontology for RAG improves the QA accuracy, by taking into account relevant sub-graphs that preserve the information in a structured manner. In this paper, we introduce SMART-SLIC, a highly domain-specific LLM framework, that integrates RAG with KG and a vector store (VS) that store factual domain specific information. Importantly, to avoid hallucinations in the KG, we build these highly domain-specific KGs and VSs without the use of LLMs, but via NLP, data mining, and nonnegative tensor factorization with automatic model selection. Pairing our RAG with a domain-specific: (i) KG (containing structured information), and (ii) VS (containing unstructured information) enables the development of domain-specific chat-bots that attribute the source of information, mitigate hallucinations, lessen the need for fine-tuning, and excel in highly domain-specific question answering tasks. We pair SMART-SLIC with chain-of-thought prompting agents. The framework is designed to be generalizable to adapt to any specific or specialized domain. In this paper, we demonstrate the question answering capabilities of our framework on a corpus of scientific publications on malware analysis and anomaly detection.