 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCALAR: A Neurosymbolic Framework for Automated Conjecture and Reasoning in Quantum Circuit Analysis
May 11, 2026In this paper, we present SCALAR (Symbolic Conjecture and LLM-Assisted Reasoning), a neurosymbolic framework for automated conjecture generation in quantum circuit analysis built on top of the CUDA-Q open source framework. The system integrates quantum simulation, symbolic conjecture generation, and LLM-based interpretation. We evaluate SCALAR on 82 MaxCut instances from the MQLib benchmark dataset and extend the analysis to 2,000 randomly generated graphs across four topologies: regular, Erdos-Renyi, Barabasi-Albert, and Watts-Strogatz. The framework generates conjectured bounds relating optimal QAOA parameters to graph invariants, including known relationships such as periodicity constraints on the phase separation parameter $γ$. SCALAR also recovers previously reported parameter transfer phenomena across structurally similar instances. Additionally, the system identifies correlations between graph structural features and optimization landscape properties, which we characterize through invariant-based descriptors. Using CUDA-Q tensor network simulator, we scale experiments to instances of up to 77 qubits. We discuss the accuracy, generality, and limitations of the generated conjectures, including sensitivity to graph class and quantum circuit depth.
Quantum Graph Transformer for NLP Sentiment Classification
Jun 09, 2025Quantum machine learning is a promising direction for building more efficient and expressive models, particularly in domains where understanding complex, structured data is critical. We present the Quantum Graph Transformer (QGT), a hybrid graph-based architecture that integrates a quantum self-attention mechanism into the message-passing framework for structured language modeling. The attention mechanism is implemented using parameterized quantum circuits (PQCs), which enable the model to capture rich contextual relationships while significantly reducing the number of trainable parameters compared to classical attention mechanisms. We evaluate QGT on five sentiment classification benchmarks. Experimental results show that QGT consistently achieves higher or comparable accuracy than existing quantum natural language processing (QNLP) models, including both attention-based and non-attention-based approaches. When compared with an equivalent classical graph transformer, QGT yields an average accuracy improvement of 5.42% on real-world datasets and 4.76% on synthetic datasets. Additionally, QGT demonstrates improved sample efficiency, requiring nearly 50% fewer labeled samples to reach comparable performance on the Yelp dataset. These results highlight the potential of graph-based QNLP techniques for advancing efficient and scalable language understanding.
Scalable, Symbiotic, AI and Non-AI Agent Based Parallel Discrete Event Simulations
May 28, 2025To fully leverage the potential of artificial intelligence (AI) systems in a trustworthy manner, it is desirable to couple multiple AI and non-AI systems together seamlessly for constraining and ensuring correctness of the output. This paper introduces a novel parallel discrete event simulation (PDES) based methodology to combine multiple AI and non-AI agents in a causal, rule-based way. Our approach tightly integrates the concept of passage of time, with each agent considered as an entity in the PDES framework and responding to prior requests from other agents. Such coupling mechanism enables the agents to work in a co-operative environment towards a common goal while many tasks run in parallel throughout the simulation. It further enables setting up boundaries to the outputs of the AI agents by applying necessary dynamic constraints using non-AI agents while allowing for scalability through deployment of hundreds of such agents in a larger compute cluster. Distributing smaller AI agents can enable extremely scalable simulations in the future, addressing local memory bottlenecks for model parameter storage. Within a PDES involving both AI and non-AI agents, we break down the problem at hand into structured steps, when necessary, providing a set of multiple choices to the AI agents, and then progressively solve these steps towards a final goal. At each step, the non-AI agents act as unbiased auditors, verifying each action by the AI agents so that certain rules of engagement are followed. We evaluate our approach by solving four problems from four different domains and comparing the results with those from AI models alone. Our results show greater accuracy in solving problems from various domains where the AI models struggle to solve the problems solely by themselves. Results show that overall accuracy of our approach is 68% where as the accuracy of vanilla models is less than 23%.
Generative Discrete Event Process Simulation for Hidden Markov Models to Predict Competitor Time-to-Market
Nov 06, 2024



We study the challenge of predicting the time at which a competitor product, such as a novel high-capacity EV battery or a new car model, will be available to customers; as new information is obtained, this time-to-market estimate is revised. Our scenario is as follows: We assume that the product is under development at a Firm B, which is a competitor to Firm A; as they are in the same industry, Firm A has a relatively good understanding of the processes and steps required to produce the product. While Firm B tries to keep its activities hidden (think of stealth-mode for start-ups), Firm A is nevertheless able to gain periodic insights by observing what type of resources Firm B is using. We show how Firm A can build a model that predicts when Firm B will be ready to sell its product; the model leverages knowledge of the underlying processes and required resources to build a Parallel Discrete Simulation (PDES)-based process model that it then uses as a generative model to train a Hidden Markov Model (HMM). We study the question of how many resource observations Firm A requires in order to accurately assess the current state of development at Firm B. In order to gain general insights into the capabilities of this approach, we study the effect of different process graph densities, different densities of the resource-activity maps, etc., and also scaling properties as we increase the number resource counts. We find that in most cases, the HMM achieves a prediction accuracy of 70 to 80 percent after 20 (daily) observations of a production process that lasts 150 days on average and we characterize the effects of different problem instance densities on this prediction accuracy. Our results give insight into the level of market knowledge required for accurate and early time-to-market prediction.
Graph Neural Networks for Parameterized Quantum Circuits Expressibility Estimation
May 13, 2024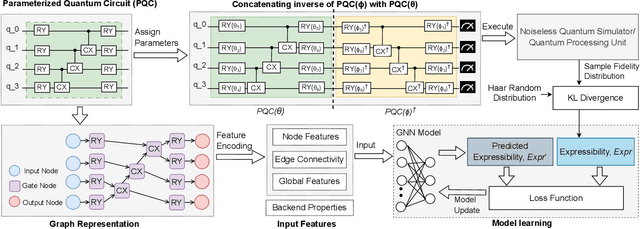


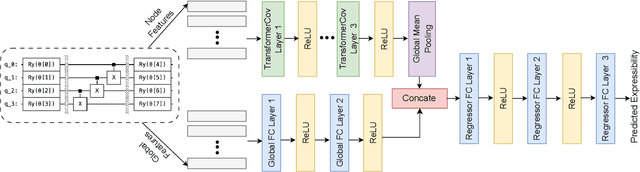
Parameterized quantum circuits (PQCs) are fundamental to quantum machine learning (QML), quantum optimization, and variational quantum algorithms (VQAs). The expressibility of PQCs is a measure that determines their capability to harness the full potential of the quantum state space. It is thus a crucial guidepost to know when selecting a particular PQC ansatz. However, the existing technique for expressibility computation through statistical estimation requires a large number of samples, which poses significant challenges due to time and computational resource constraints. This paper introduces a novel approach for expressibility estimation of PQCs using Graph Neural Networks (GNNs). We demonstrate the predictive power of our GNN model with a dataset consisting of 25,000 samples from the noiseless IBM QASM Simulator and 12,000 samples from three distinct noisy quantum backends. The model accurately estimates expressibility, with root mean square errors (RMSE) of 0.05 and 0.06 for the noiseless and noisy backends, respectively. We compare our model's predictions with reference circuits [Sim and others, QuTe'2019] and IBM Qiskit's hardware-efficient ansatz sets to further evaluate our model's performance. Our experimental evaluation in noiseless and noisy scenarios reveals a close alignment with ground truth expressibility values, highlighting the model's efficacy. Moreover, our model exhibits promising extrapolation capabilities, predicting expressibility values with low RMSE for out-of-range qubit circuits trained solely on only up to 5-qubit circuit sets. This work thus provides a reliable means of efficiently evaluating the expressibility of diverse PQCs on noiseless simulators and hardware.
Process Modeling, Hidden Markov Models, and Non-negative Tensor Factorization with Model Selection
Oct 03, 2022
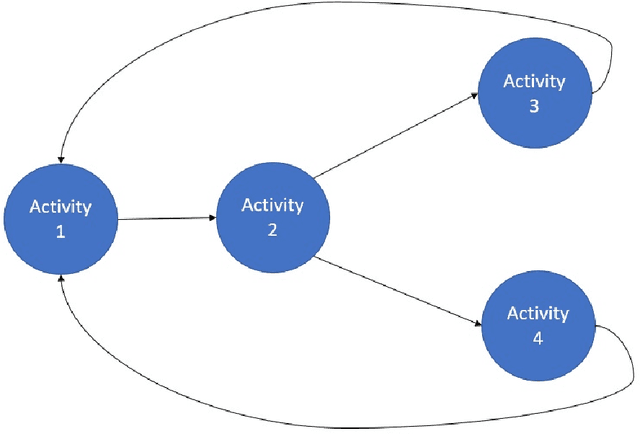
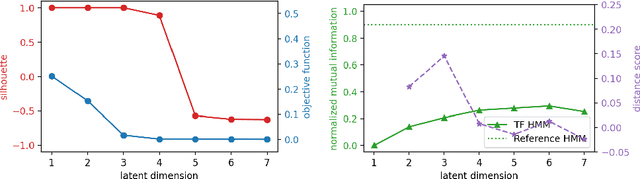
Monitoring of industrial processes is a critical capability in industry and in government to ensure reliability of production cycles, quick emergency response, and national security. Process monitoring allows users to gauge the involvement of an organization in an industrial process or predict the degradation or aging of machine parts in processes taking place at a remote location. Similar to many data science applications, we usually only have access to limited raw data, such as satellite imagery, short video clips, some event logs, and signatures captured by a small set of sensors. To combat data scarcity, we leverage the knowledge of subject matter experts (SMEs) who are familiar with the process. Various process mining techniques have been developed for this type of analysis; typically such approaches combine theoretical process models built based on domain expert insights with ad-hoc integration of available pieces of raw data. Here, we introduce a novel mathematically sound method that integrates theoretical process models (as proposed by SMEs) with interrelated minimal Hidden Markov Models (HMM), built via non-negative tensor factorization and discrete model simulations. Our method consolidates: (a) Theoretical process models development, (b) Discrete model simulations (c) HMM, (d) Joint Non-negative Matrix Factorization (NMF) and Non-negative Tensor Factorization (NTF), and (e) Custom model selection. To demonstrate our methodology and its abilities, we apply it on simple synthetic and real world process models.
Distributed Out-of-Memory NMF of Dense and Sparse Data on CPU/GPU Architectures with Automatic Model Selection for Exascale Data
Feb 19, 2022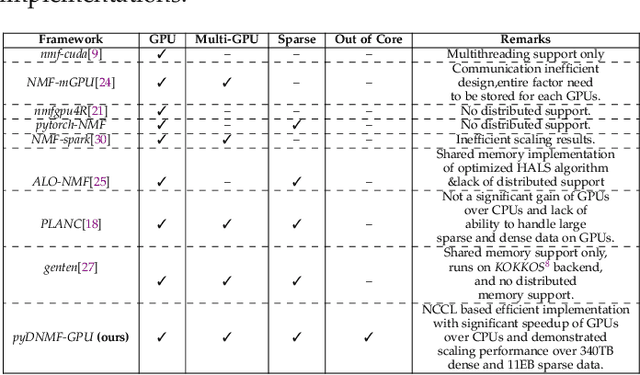
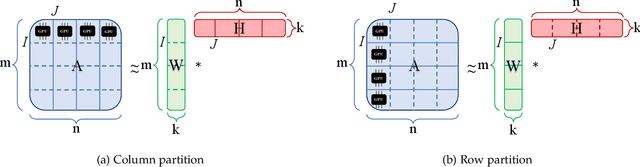
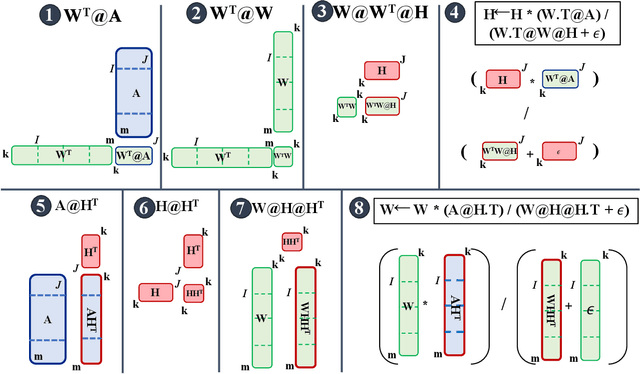
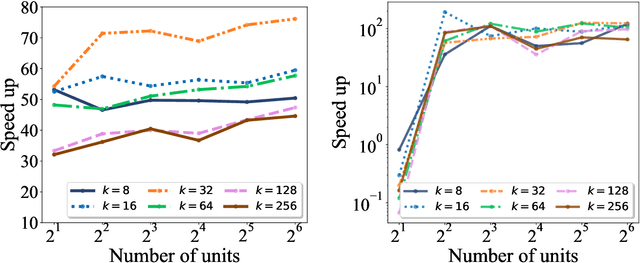
The need for efficient and scalable big-data analytics methods is more essential than ever due to the exploding size and complexity of globally emerging datasets. Nonnegative Matrix Factorization (NMF) is a well-known explainable unsupervised learning method for dimensionality reduction, latent feature extraction, blind source separation, data mining, and machine learning. In this paper, we introduce a new distributed out-of-memory NMF method, named pyDNMF-GPU, designed for modern heterogeneous CPU/GPU architectures that is capable of factoring exascale-sized dense and sparse matrices. Our method reduces the latency associated with local data transfer between the GPU and host using CUDA streams, and reduces the latency associated with collective communications (both intra-node and inter-node) via NCCL primitives. In addition, sparse and dense matrix multiplications are significantly accelerated with GPU cores, resulting in good scalability. We set new benchmarks for the size of the data being analyzed: in experiments, we measure up to 76x improvement on a single GPU over running on a single 18 core CPU and we show good weak scaling on up to 4096 multi-GPU cluster nodes with approximately 25,000 GPUs, when decomposing a dense 340 Terabyte-size matrix and a 11 Exabyte-size sparse matrix of density 10e-6. Finally, we integrate our method with an automatic model selection method. With this integration, we introduce a new tool that is capable of analyzing, compressing, and discovering explainable latent structures in extremely large sparse and dense data.
BB-ML: Basic Block Performance Prediction using Machine Learning Techniques
Feb 18, 2022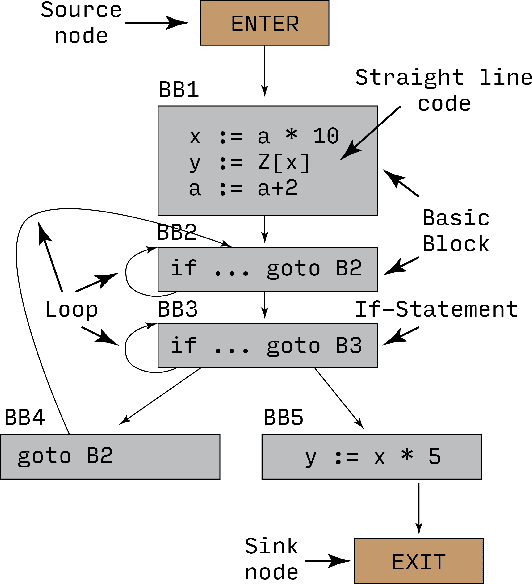
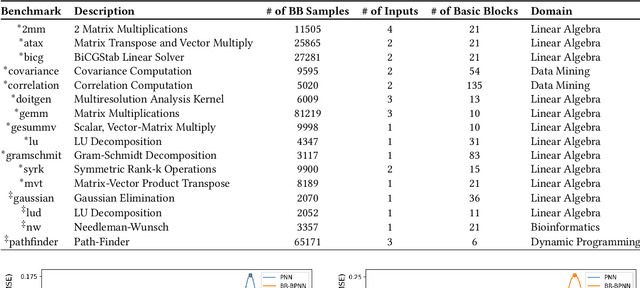
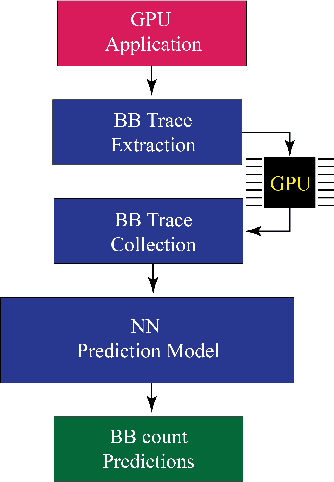
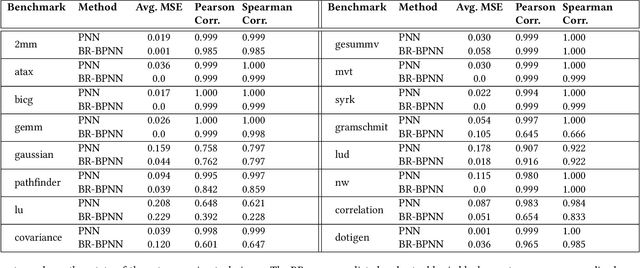
Recent years have seen the adoption of Machine Learning (ML) techniques to predict the performance of large-scale applications, mostly at a coarse level. In contrast, we propose to use ML techniques for performance prediction at much finer granularity, namely at the levels of Basic Block (BB), which are the single entry-single exit code blocks that are used as analysis tools by all compilers to break down a large code into manageable pieces. Utilizing ML and BB analysis together can enable scalable hardware-software co-design beyond the current state of the art. In this work, we extrapolate the basic block execution counts of GPU applications for large inputs sizes from the counts of smaller input sizes of the same application. We employ two ML models, a Poisson Neural Network (PNN) and a Bayesian Regularization Backpropagation Neural Network (BR-BPNN). We train both models using the lowest input values of the application and random input values to predict basic block counts. Results show that our models accurately predict the basic block execution counts of 16 benchmark applications. For PNN and BR-BPNN models, we achieve an average accuracy of 93.5% and 95.6%, respectively, while extrapolating the basic block counts for large input sets when the model is trained using smaller input sets. Additionally, the models show an average accuracy of 97.7% and 98.1%, respectively, while predicting basic block counts on random instances.
The ISTI Rapid Response on Exploring Cloud Computing 2018
Jan 04, 2019
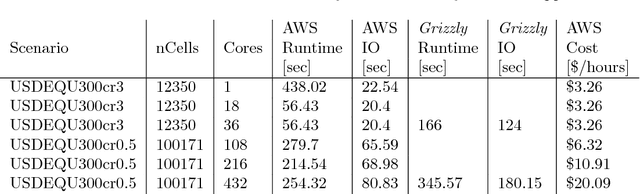

This report describes eighteen projects that explored how commercial cloud computing services can be utilized for scientific computation at national laboratories. These demonstrations ranged from deploying proprietary software in a cloud environment to leveraging established cloud-based analytics workflows for processing scientific datasets. By and large, the projects were successful and collectively they suggest that cloud computing can be a valuable computational resource for scientific computation at national laboratories.