 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Programming for Cultural Bias and Alignment of Large Language Models
Mar 17, 2026Culture shapes reasoning, values, prioritization, and strategic decision-making, yet large language models (LLMs) often exhibit cultural biases that misalign with target populations. As LLMs are increasingly used for strategic decision-making, policy support, and document engineering tasks such as summarization, categorization, and compliance-oriented auditing, improving cultural alignment is important for ensuring that downstream analyses and recommendations reflect target-population value profiles rather than default model priors. Previous work introduced a survey-grounded cultural alignment framework and showed that culture-specific prompting can reduce misalignment, but it primarily evaluated proprietary models and relied on manual prompt engineering. In this paper, we validate and extend that framework by reproducing its social sciences survey based projection and distance metrics on open-weight LLMs, testing whether the same cultural skew and benefits of culture conditioning persist outside closed LLM systems. Building on this foundation, we introduce use of prompt programming with DSPy for this problem-treating prompts as modular, optimizable programs-to systematically tune cultural conditioning by optimizing against cultural-distance objectives. In our experiments, we show that prompt optimization often improves upon cultural prompt engineering, suggesting prompt compilation with DSPy can provide a more stable and transferable route to culturally aligned LLM responses.
HEAL: Hierarchical Embedding Alignment Loss for Improved Retrieval and Representation Learning
Dec 05, 2024

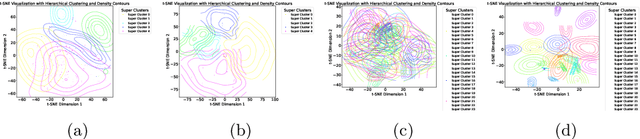

Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by integrating external document retrieval to provide domain-specific or up-to-date knowledge. The effectiveness of RAG depends on the relevance of retrieved documents, which is influenced by the semantic alignment of embeddings with the domain's specialized content. Although full fine-tuning can align language models to specific domains, it is computationally intensive and demands substantial data. This paper introduces Hierarchical Embedding Alignment Loss (HEAL), a novel method that leverages hierarchical fuzzy clustering with matrix factorization within contrastive learning to efficiently align LLM embeddings with domain-specific content. HEAL computes level/depth-wise contrastive losses and incorporates hierarchical penalties to align embeddings with the underlying relationships in label hierarchies. This approach enhances retrieval relevance and document classification, effectively reducing hallucinations in LLM outputs. In our experiments, we benchmark and evaluate HEAL across diverse domains, including Healthcare, Material Science, Cyber-security, and Applied Maths.
Electrical Grid Anomaly Detection via Tensor Decomposition
Oct 12, 2023



Supervisory Control and Data Acquisition (SCADA) systems often serve as the nervous system for substations within power grids. These systems facilitate real-time monitoring, data acquisition, control of equipment, and ensure smooth and efficient operation of the substation and its connected devices. Previous work has shown that dimensionality reduction-based approaches, such as Principal Component Analysis (PCA), can be used for accurate identification of anomalies in SCADA systems. While not specifically applied to SCADA, non-negative matrix factorization (NMF) has shown strong results at detecting anomalies in wireless sensor networks. These unsupervised approaches model the normal or expected behavior and detect the unseen types of attacks or anomalies by identifying the events that deviate from the expected behavior. These approaches; however, do not model the complex and multi-dimensional interactions that are naturally present in SCADA systems. Differently, non-negative tensor decomposition is a powerful unsupervised machine learning (ML) method that can model the complex and multi-faceted activity details of SCADA events. In this work, we novelly apply the tensor decomposition method Canonical Polyadic Alternating Poisson Regression (CP-APR) with a probabilistic framework, which has previously shown state-of-the-art anomaly detection results on cyber network data, to identify anomalies in SCADA systems. We showcase that the use of statistical behavior analysis of SCADA communication with tensor decomposition improves the specificity and accuracy of identifying anomalies in electrical grid systems. In our experiments, we model real-world SCADA system data collected from the electrical grid operated by Los Alamos National Laboratory (LANL) which provides transmission and distribution service through a partnership with Los Alamos County, and detect synthetically generated anomalies.
Can Feature Engineering Help Quantum Machine Learning for Malware Detection?
May 03, 2023
With the increasing number and sophistication of malware attacks, malware detection systems based on machine learning (ML) grow in importance. At the same time, many popular ML models used in malware classification are supervised solutions. These supervised classifiers often do not generalize well to novel malware. Therefore, they need to be re-trained frequently to detect new malware specimens, which can be time-consuming. Our work addresses this problem in a hybrid framework of theoretical Quantum ML, combined with feature selection strategies to reduce the data size and malware classifier training time. The preliminary results show that VQC with XGBoost selected features can get a 78.91% test accuracy on the simulator. The average accuracy for the model trained using the features selected with XGBoost was 74% (+- 11.35%) on the IBM 5 qubits machines.
Distributed Out-of-Memory NMF of Dense and Sparse Data on CPU/GPU Architectures with Automatic Model Selection for Exascale Data
Feb 19, 2022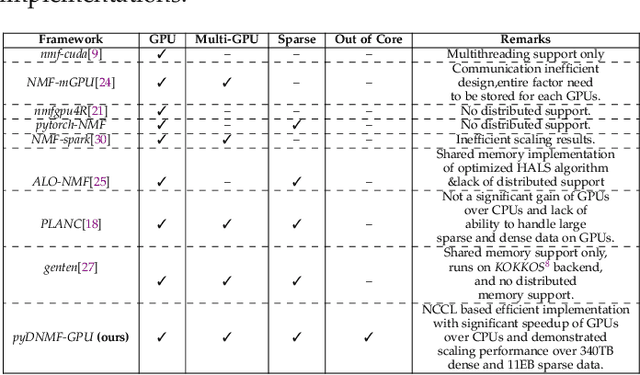
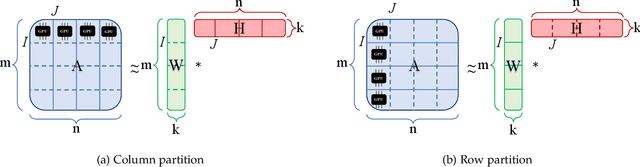
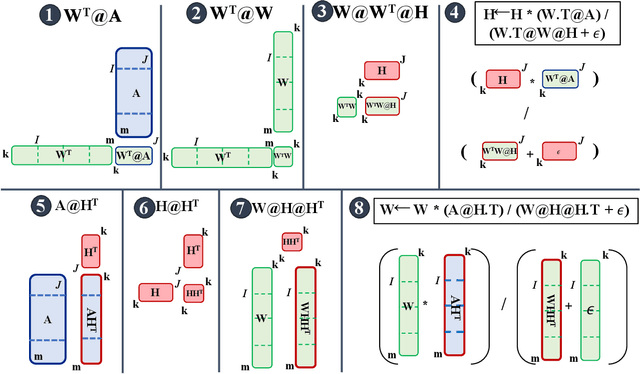
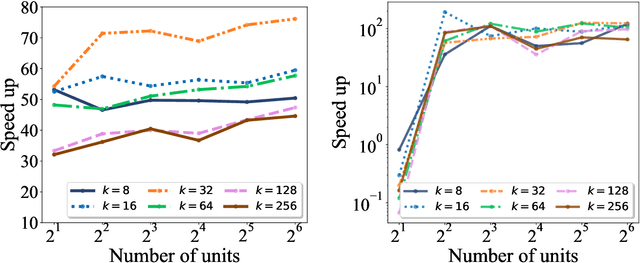
The need for efficient and scalable big-data analytics methods is more essential than ever due to the exploding size and complexity of globally emerging datasets. Nonnegative Matrix Factorization (NMF) is a well-known explainable unsupervised learning method for dimensionality reduction, latent feature extraction, blind source separation, data mining, and machine learning. In this paper, we introduce a new distributed out-of-memory NMF method, named pyDNMF-GPU, designed for modern heterogeneous CPU/GPU architectures that is capable of factoring exascale-sized dense and sparse matrices. Our method reduces the latency associated with local data transfer between the GPU and host using CUDA streams, and reduces the latency associated with collective communications (both intra-node and inter-node) via NCCL primitives. In addition, sparse and dense matrix multiplications are significantly accelerated with GPU cores, resulting in good scalability. We set new benchmarks for the size of the data being analyzed: in experiments, we measure up to 76x improvement on a single GPU over running on a single 18 core CPU and we show good weak scaling on up to 4096 multi-GPU cluster nodes with approximately 25,000 GPUs, when decomposing a dense 340 Terabyte-size matrix and a 11 Exabyte-size sparse matrix of density 10e-6. Finally, we integrate our method with an automatic model selection method. With this integration, we introduce a new tool that is capable of analyzing, compressing, and discovering explainable latent structures in extremely large sparse and dense data.