 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Modeling and Link-Prediction for Material Property Discovery
Jul 08, 2025



Link prediction infers missing or future relations between graph nodes, based on connection patterns. Scientific literature networks and knowledge graphs are typically large, sparse, and noisy, and often contain missing links between entities. We present an AI-driven hierarchical link prediction framework that integrates matrix factorization to infer hidden associations and steer discovery in complex material domains. Our method combines Hierarchical Nonnegative Matrix Factorization (HNMFk) and Boolean matrix factorization (BNMFk) with automatic model selection, as well as Logistic matrix factorization (LMF), we use to construct a three-level topic tree from a 46,862-document corpus focused on 73 transition-metal dichalcogenides (TMDs). These materials are studied in a variety of physics fields with many current and potential applications. An ensemble BNMFk + LMF approach fuses discrete interpretability with probabilistic scoring. The resulting HNMFk clusters map each material onto coherent topics like superconductivity, energy storage, and tribology. Also, missing or weakly connected links are highlight between topics and materials, suggesting novel hypotheses for cross-disciplinary exploration. We validate our method by removing publications about superconductivity in well-known superconductors, and show the model predicts associations with the superconducting TMD clusters. This shows the method finds hidden connections in a graph of material to latent topic associations built from scientific literature, especially useful when examining a diverse corpus of scientific documents covering the same class of phenomena or materials but originating from distinct communities and perspectives. The inferred links generating new hypotheses, produced by our method, are exposed through an interactive Streamlit dashboard, designed for human-in-the-loop scientific discovery.
Rapid analysis of point-contact Andreev reflection spectra via machine learning with adaptive data augmentation
Mar 13, 2025


Delineating the superconducting order parameters is a pivotal task in investigating superconductivity for probing pairing mechanisms, as well as their symmetry and topology. Point-contact Andreev reflection (PCAR) measurement is a simple yet powerful tool for identifying the order parameters. The PCAR spectra exhibit significant variations depending on the type of the order parameter in a superconductor, including its magnitude ($\mathit{\Delta}$), as well as temperature, interfacial quality, Fermi velocity mismatch, and other factors. The information on the order parameter can be obtained by finding the combination of these parameters, generating a theoretical spectrum that fits a measured experimental spectrum. However, due to the complexity of the spectra and the high dimensionality of parameters, extracting the fitting parameters is often time-consuming and labor-intensive. In this study, we employ a convolutional neural network (CNN) algorithm to create models for rapid and automated analysis of PCAR spectra of various superconductors with different pairing symmetries (conventional $s$-wave, chiral $p_x+ip_y$-wave, and $d_{x^2-y^2}$-wave). The training datasets are generated based on the Blonder-Tinkham-Klapwijk (BTK) theory and further modified and augmented by selectively incorporating noise and peaks according to the bias voltages. This approach not only replicates the experimental spectra but also brings the model's attention to important features within the spectra. The optimized models provide fitting parameters for experimentally measured spectra in less than 100 ms per spectrum. Our approaches and findings pave the way for rapid and automated spectral analysis which will help accelerate research on superconductors with complex order parameters.
HEAL: Hierarchical Embedding Alignment Loss for Improved Retrieval and Representation Learning
Dec 05, 2024

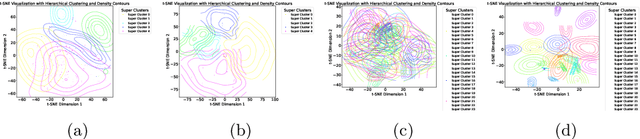

Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by integrating external document retrieval to provide domain-specific or up-to-date knowledge. The effectiveness of RAG depends on the relevance of retrieved documents, which is influenced by the semantic alignment of embeddings with the domain's specialized content. Although full fine-tuning can align language models to specific domains, it is computationally intensive and demands substantial data. This paper introduces Hierarchical Embedding Alignment Loss (HEAL), a novel method that leverages hierarchical fuzzy clustering with matrix factorization within contrastive learning to efficiently align LLM embeddings with domain-specific content. HEAL computes level/depth-wise contrastive losses and incorporates hierarchical penalties to align embeddings with the underlying relationships in label hierarchies. This approach enhances retrieval relevance and document classification, effectively reducing hallucinations in LLM outputs. In our experiments, we benchmark and evaluate HEAL across diverse domains, including Healthcare, Material Science, Cyber-security, and Applied Maths.
Topic Analysis of Superconductivity Literature by Semantic Non-negative Matrix Factorization
Dec 01, 2021
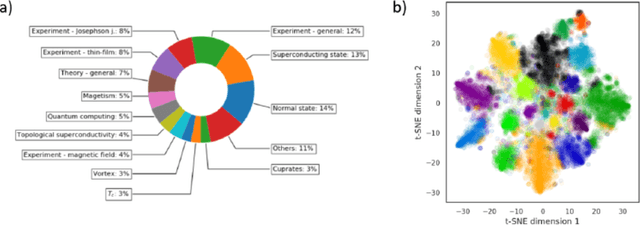
We utilize a recently developed topic modeling method called SeNMFk, extending the standard Non-negative Matrix Factorization (NMF) methods by incorporating the semantic structure of the text, and adding a robust system for determining the number of topics. With SeNMFk, we were able to extract coherent topics validated by human experts. From these topics, a few are relatively general and cover broad concepts, while the majority can be precisely mapped to specific scientific effects or measurement techniques. The topics also differ by ubiquity, with only three topics prevalent in almost 40 percent of the abstract, while each specific topic tends to dominate a small subset of the abstracts. These results demonstrate the ability of SeNMFk to produce a layered and nuanced analysis of large scientific corpora.
CRYSPNet: Crystal Structure Predictions via Neural Network
Mar 31, 2020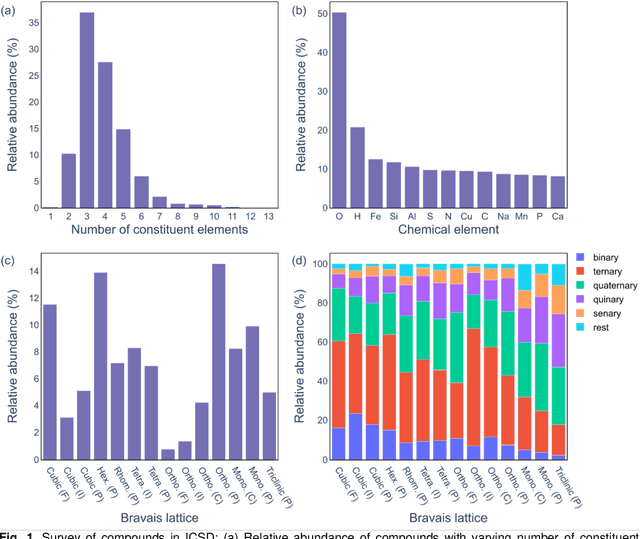

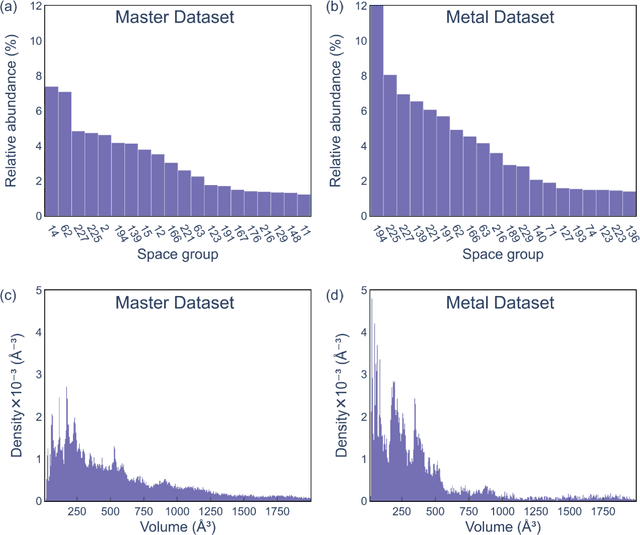
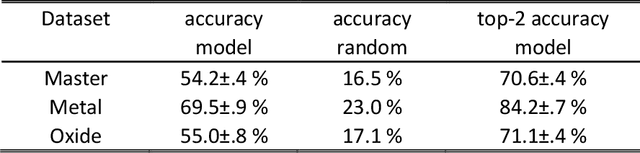
Structure is the most basic and important property of crystalline solids; it determines directly or indirectly most materials characteristics. However, predicting crystal structure of solids remains a formidable and not fully solved problem. Standard theoretical tools for this task are computationally expensive and at times inaccurate. Here we present an alternative approach utilizing machine learning for crystal structure prediction. We developed a tool called Crystal Structure Prediction Network (CRYSPNet) that can predict the Bravais lattice, space group, and lattice parameters of an inorganic material based only on its chemical composition. CRYSPNet consists of a series of neural network models, using as inputs predictors aggregating the properties of the elements constituting the compound. It was trained and validated on more than 100,000 entries from the Inorganic Crystal Structure Database. The tool demonstrates robust predictive capability and outperforms alternative strategies by a large margin. Made available to the public (at https://github.com/AuroraLHT/cryspnet), it can be used both as an independent prediction engine or as a method to generate candidate structures for further computational and/or experimental validation.
Unsupervised Phase Mapping of X-ray Diffraction Data by Nonnegative Matrix Factorization Integrated with Custom Clustering
Feb 20, 2018
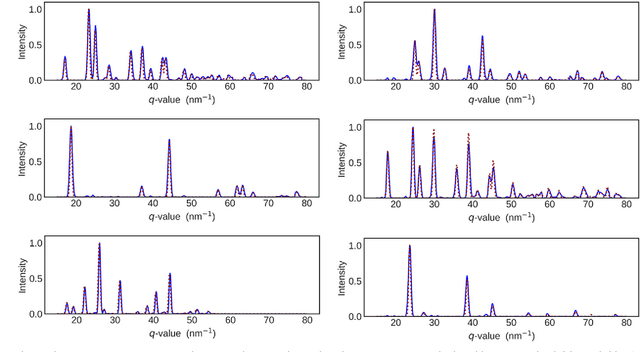

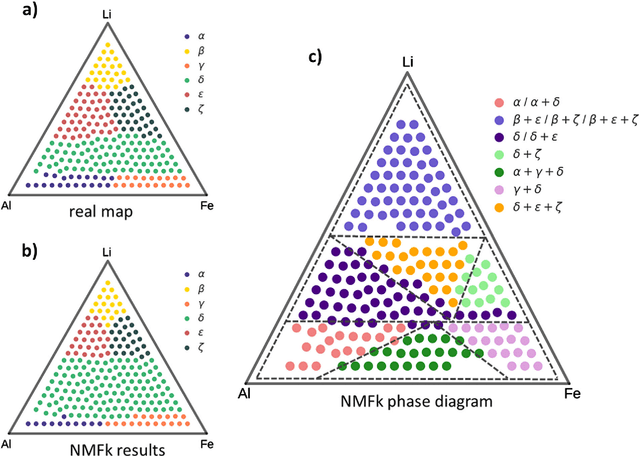
Analyzing large X-ray diffraction (XRD) datasets is a key step in high-throughput mapping of the compositional phase diagrams of combinatorial materials libraries. Optimizing and automating this task can help accelerate the process of discovery of materials with novel and desirable properties. Here, we report a new method for pattern analysis and phase extraction of XRD datasets. The method expands the Nonnegative Matrix Factorization method, which has been used previously to analyze such datasets, by combining it with custom clustering and cross-correlation algorithms. This new method is capable of robust determination of the number of basis patterns present in the data which, in turn, enables straightforward identification of any possible peak-shifted patterns. Peak-shifting arises due to continuous change in the lattice constants as a function of composition, and is ubiquitous in XRD datasets from composition spread libraries. Successful identification of the peak-shifted patterns allows proper quantification and classification of the basis XRD patterns, which is necessary in order to decipher the contribution of each unique single-phase structure to the multi-phase regions. The process can be utilized to determine accurately the compositional phase diagram of a system under study. The presented method is applied to one synthetic and one experimental dataset, and demonstrates robust accuracy and identification abilities.
* 26 pages, 9 figures
Machine learning modeling of superconducting critical temperature
Oct 06, 2017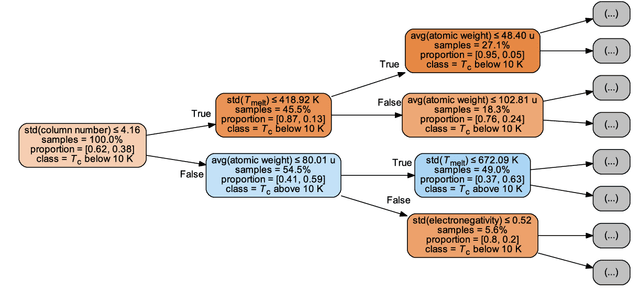

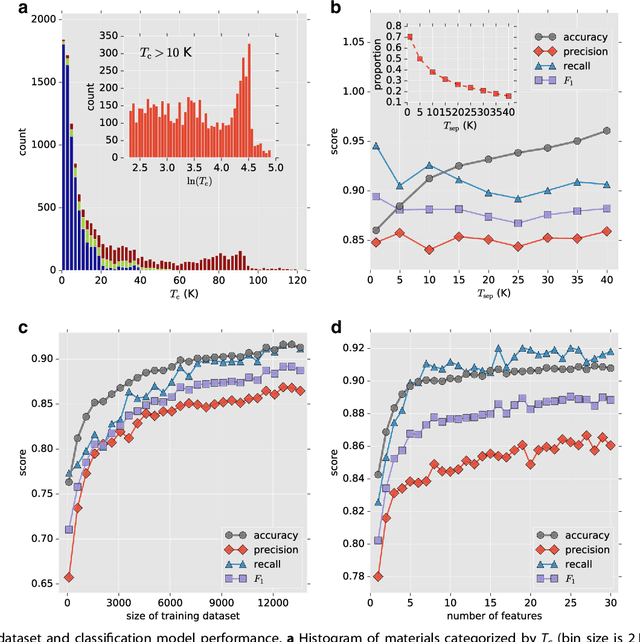
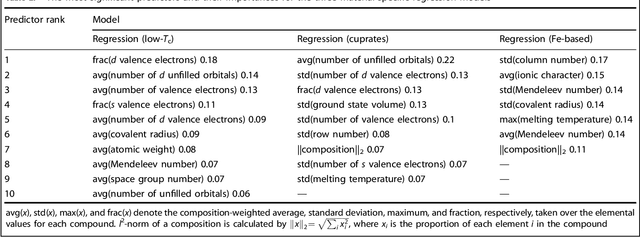
Superconductivity has been the focus of enormous research effort since its discovery more than a century ago. Yet, some features of this unique phenomenon remain poorly understood; prime among these is the connection between superconductivity and chemical/structural properties of materials. To bridge the gap, several machine learning schemes are developed herein to model the critical temperatures ($T_{\mathrm{c}}$) of the 12,000+ known superconductors available via the SuperCon database. Materials are first divided into two classes based on their $T_{\mathrm{c}}$ values, above and below 10 K, and a classification model predicting this label is trained. The model uses coarse-grained features based only on the chemical compositions. It shows strong predictive power, with out-of-sample accuracy of about 92%. Separate regression models are developed to predict the values of $T_{\mathrm{c}}$ for cuprate, iron-based, and "low-$T_{\mathrm{c}}$" compounds. These models also demonstrate good performance, with learned predictors offering potential insights into the mechanisms behind superconductivity in different families of materials. To improve the accuracy and interpretability of these models, new features are incorporated using materials data from the AFLOW Online Repositories. Finally, the classification and regression models are combined into a single integrated pipeline and employed to search the entire Inorganic Crystallographic Structure Database (ICSD) for potential new superconductors. We identify more than 30 non-cuprate and non-iron-based oxides as candidate materials.
* 17 pages, 7 figures