 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Phase Mapping of X-ray Diffraction Data by Nonnegative Matrix Factorization Integrated with Custom Clustering
Feb 20, 2018
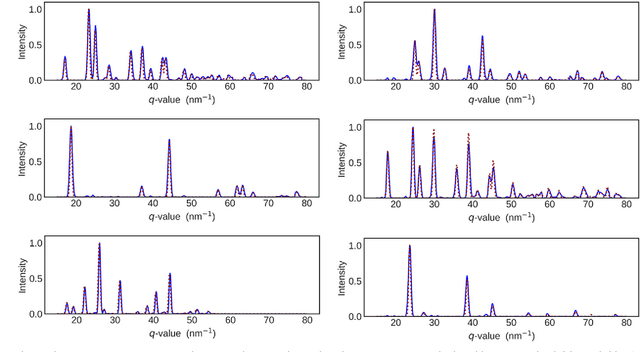

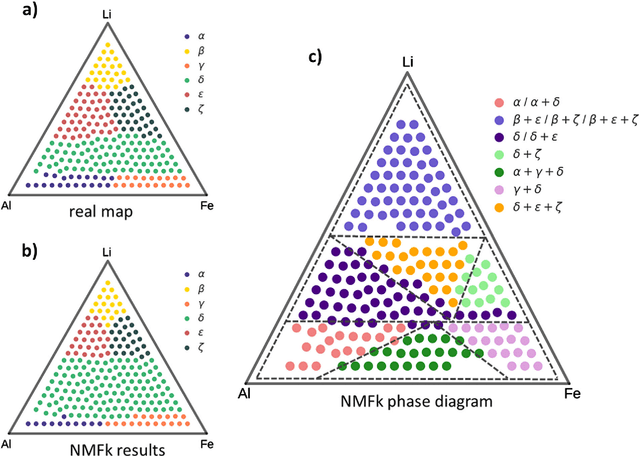
Analyzing large X-ray diffraction (XRD) datasets is a key step in high-throughput mapping of the compositional phase diagrams of combinatorial materials libraries. Optimizing and automating this task can help accelerate the process of discovery of materials with novel and desirable properties. Here, we report a new method for pattern analysis and phase extraction of XRD datasets. The method expands the Nonnegative Matrix Factorization method, which has been used previously to analyze such datasets, by combining it with custom clustering and cross-correlation algorithms. This new method is capable of robust determination of the number of basis patterns present in the data which, in turn, enables straightforward identification of any possible peak-shifted patterns. Peak-shifting arises due to continuous change in the lattice constants as a function of composition, and is ubiquitous in XRD datasets from composition spread libraries. Successful identification of the peak-shifted patterns allows proper quantification and classification of the basis XRD patterns, which is necessary in order to decipher the contribution of each unique single-phase structure to the multi-phase regions. The process can be utilized to determine accurately the compositional phase diagram of a system under study. The presented method is applied to one synthetic and one experimental dataset, and demonstrates robust accuracy and identification abilities.
* 26 pages, 9 figures