 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoThermalCloud: Machine Learning for Geothermal Resource Exploration
Oct 17, 2022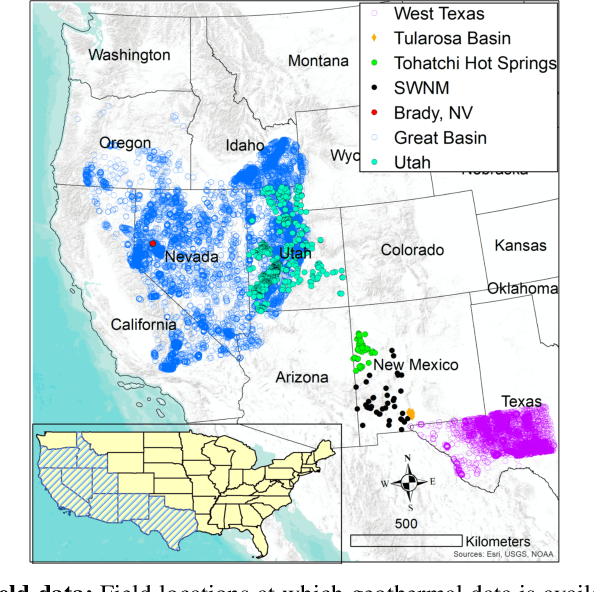
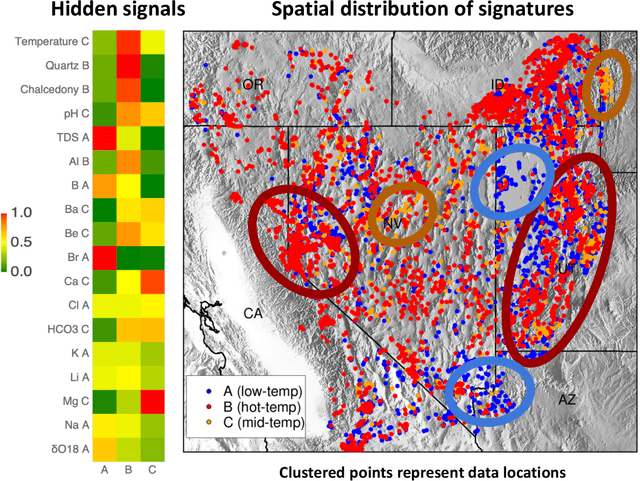
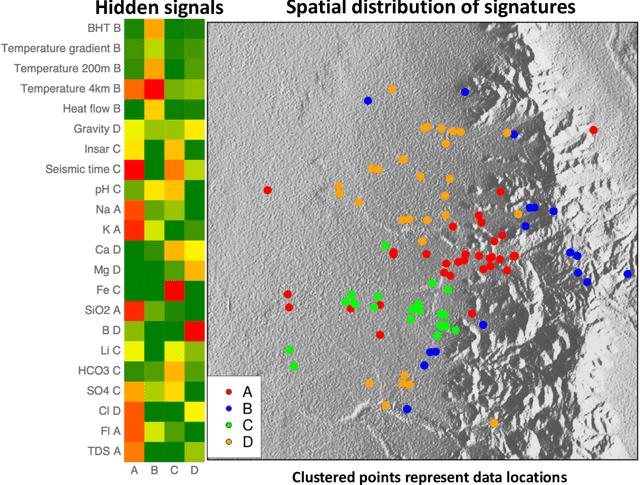
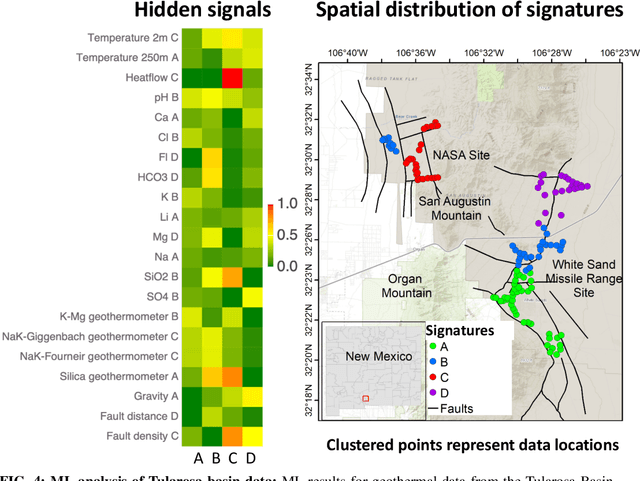
This paper presents a novel ML-based methodology for geothermal exploration towards PFA applications. Our methodology is provided through our open-source ML framework, GeoThermalCloud \url{https://github.com/SmartTensors/GeoThermalCloud.jl}. The GeoThermalCloud uses a series of unsupervised, supervised, and physics-informed ML methods available in SmartTensors AI platform \url{https://github.com/SmartTensors}. Here, the presented analyses are performed using our unsupervised ML algorithm called NMF$k$, which is available in the SmartTensors AI platform. Our ML algorithm facilitates the discovery of new phenomena, hidden patterns, and mechanisms that helps us to make informed decisions. Moreover, the GeoThermalCloud enhances the collected PFA data and discovers signatures representative of geothermal resources. Through GeoThermalCloud, we could identify hidden patterns in the geothermal field data needed to discover blind systems efficiently. Crucial geothermal signatures often overlooked in traditional PFA are extracted using the GeoThermalCloud and analyzed by the subject matter experts to provide ML-enhanced PFA, which is informative for efficient exploration. We applied our ML methodology to various open-source geothermal datasets within the U.S. (some of these are collected by past PFA work). The results provide valuable insights into resource types within those regions. This ML-enhanced workflow makes the GeoThermalCloud attractive for the geothermal community to improve existing datasets and extract valuable information often unnoticed during geothermal exploration.
Learning to regularize with a variational autoencoder for hydrologic inverse analysis
Jun 06, 2019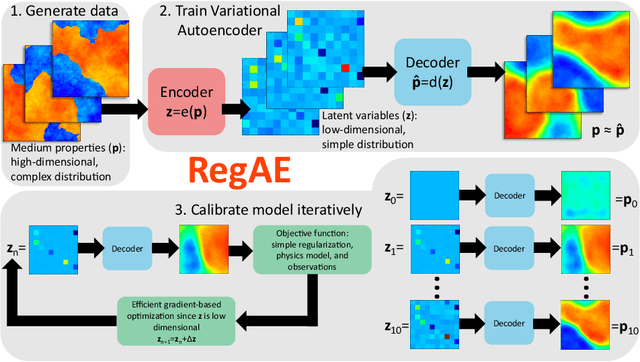
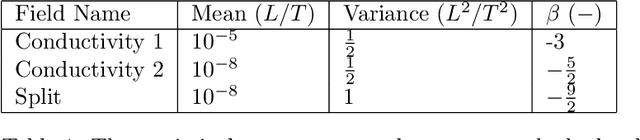
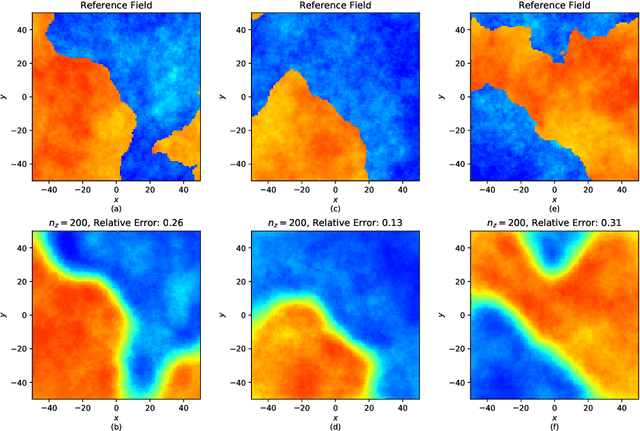
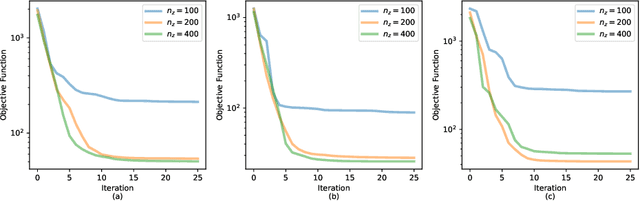
Inverse problems often involve matching observational data using a physical model that takes a large number of parameters as input. These problems tend to be under-constrained and require regularization to impose additional structure on the solution in parameter space. A central difficulty in regularization is turning a complex conceptual model of this additional structure into a functional mathematical form to be used in the inverse analysis. In this work we propose a method of regularization involving a machine learning technique known as a variational autoencoder (VAE). The VAE is trained to map a low-dimensional set of latent variables with a simple structure to the high-dimensional parameter space that has a complex structure. We train a VAE on unconditioned realizations of the parameters for a hydrological inverse problem. These unconditioned realizations neither rely on the observational data used to perform the inverse analysis nor require any forward runs of the physical model, thus making the computational cost of generating the training data minimal. The central benefit of this approach is that regularization is then performed on the latent variables from the VAE, which can be regularized simply. A second benefit of this approach is that the VAE reduces the number of variables in the optimization problem, thus making gradient-based optimization more computationally efficient when adjoint methods are unavailable. After performing regularization and optimization on the latent variables, the VAE then decodes the problem back to the original parameter space. Our approach constitutes a novel framework for regularization and optimization, readily applicable to a wide range of inverse problems. We call the approach RegAE.
Identification of release sources in advection-diffusion system by machine learning combined with Green function inverse method
Mar 23, 2018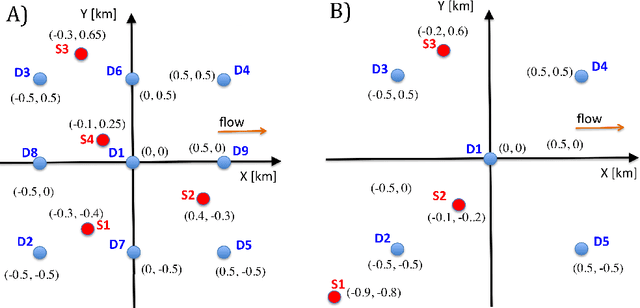
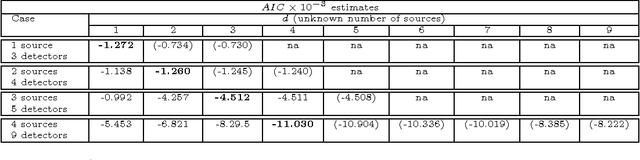
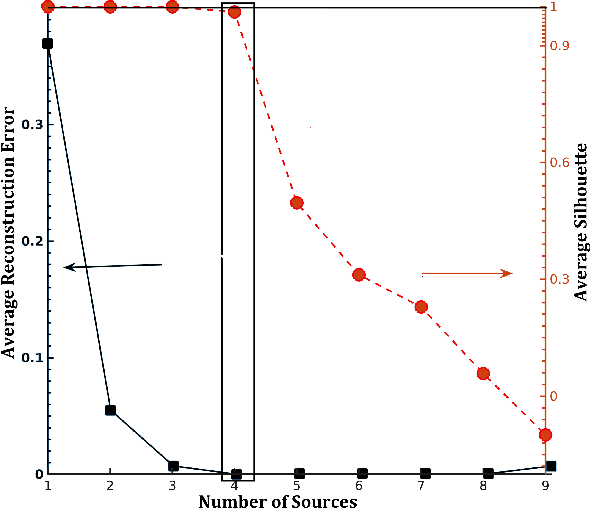
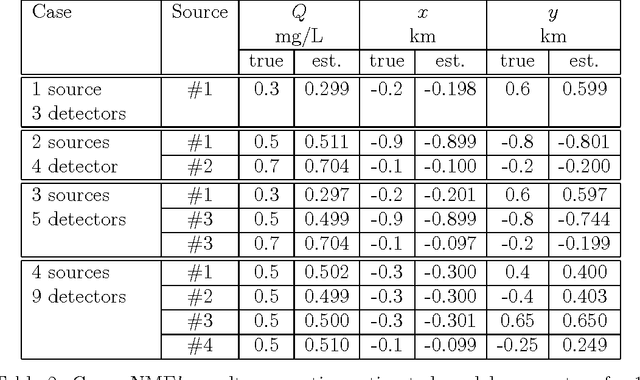
The identification of sources of advection-diffusion transport is based usually on solving complex ill-posed inverse models against the available state- variable data records. However, if there are several sources with different locations and strengths, the data records represent mixtures rather than the separate influences of the original sources. Importantly, the number of these original release sources is typically unknown, which hinders reliability of the classical inverse-model analyses. To address this challenge, we present here a novel hybrid method for identification of the unknown number of release sources. Our hybrid method, called HNMF, couples unsupervised learning based on Nonnegative Matrix Factorization (NMF) and inverse-analysis Green functions method. HNMF synergistically performs decomposition of the recorded mixtures, finds the number of the unknown sources and uses the Green function of advection-diffusion equation to identify their characteristics. In the paper, we introduce the method and demonstrate that it is capable of identifying the advection velocity and dispersivity of the medium as well as the unknown number, locations, and properties of various sets of synthetic release sources with different space and time dependencies, based only on the recorded data. HNMF can be applied directly to any problem controlled by a partial-differential parabolic equation where mixtures of an unknown number of sources are measured at multiple locations.
Nonnegative Matrix Factorization for identification of unknown number of sources emitting delayed signals
Mar 23, 2018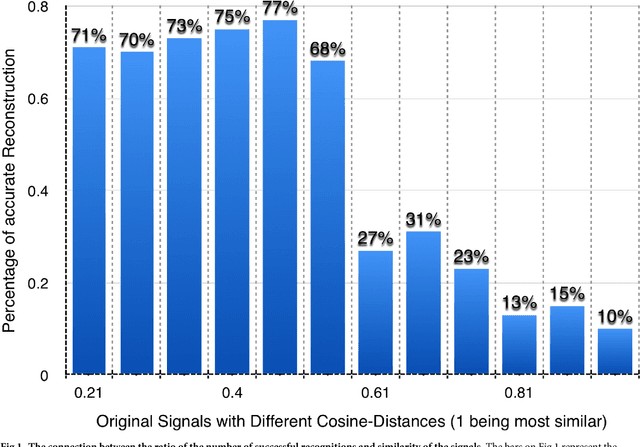

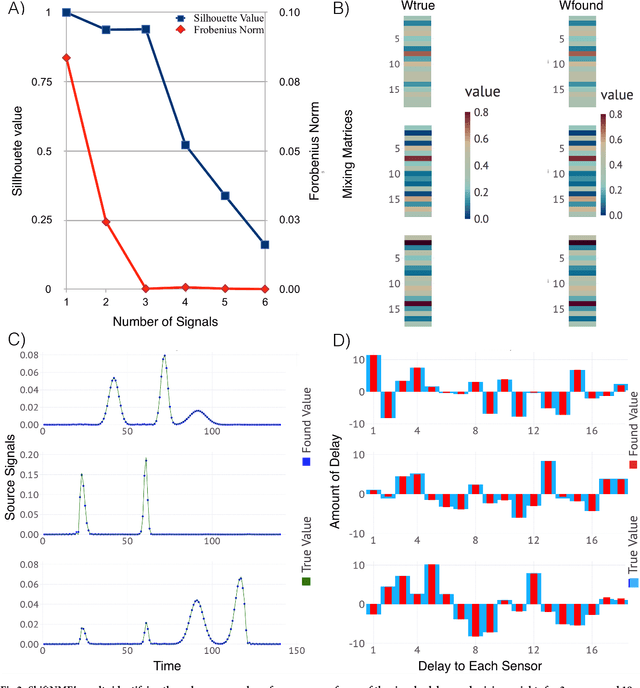
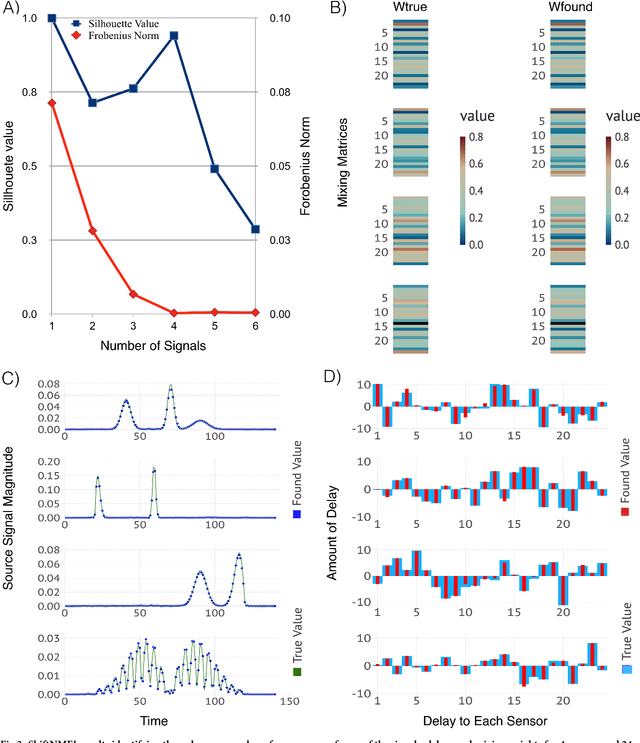
Factor analysis is broadly used as a powerful unsupervised machine learning tool for reconstruction of hidden features in recorded mixtures of signals. In the case of a linear approximation, the mixtures can be decomposed by a variety of model-free Blind Source Separation (BSS) algorithms. Most of the available BSS algorithms consider an instantaneous mixing of signals, while the case when the mixtures are linear combinations of signals with delays is less explored. Especially difficult is the case when the number of sources of the signals with delays is unknown and has to be determined from the data as well. To address this problem, in this paper, we present a new method based on Nonnegative Matrix Factorization (NMF) that is capable of identifying: (a) the unknown number of the sources, (b) the delays and speed of propagation of the signals, and (c) the locations of the sources. Our method can be used to decompose records of mixtures of signals with delays emitted by an unknown number of sources in a nondispersive medium, based only on recorded data. This is the case, for example, when electromagnetic signals from multiple antennas are received asynchronously; or mixtures of acoustic or seismic signals recorded by sensors located at different positions; or when a shift in frequency is induced by the Doppler effect. By applying our method to synthetic datasets, we demonstrate its ability to identify the unknown number of sources as well as the waveforms, the delays, and the strengths of the signals. Using Bayesian analysis, we also evaluate estimation uncertainties and identify the region of likelihood where the positions of the sources can be found.
Unsupervised Phase Mapping of X-ray Diffraction Data by Nonnegative Matrix Factorization Integrated with Custom Clustering
Feb 20, 2018
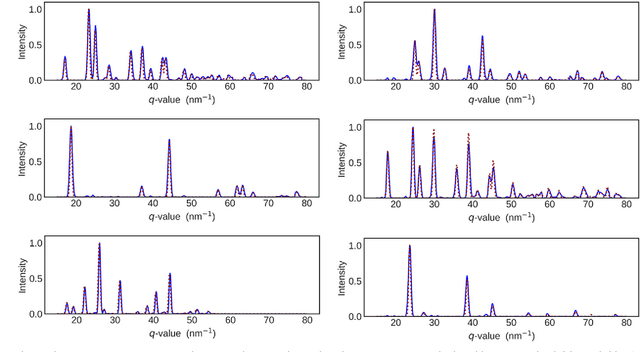

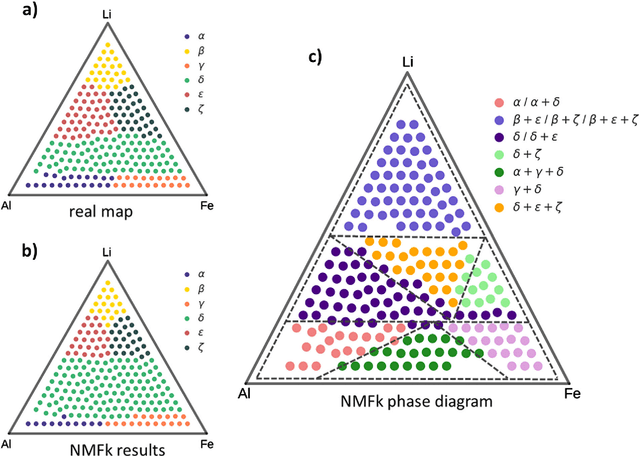
Analyzing large X-ray diffraction (XRD) datasets is a key step in high-throughput mapping of the compositional phase diagrams of combinatorial materials libraries. Optimizing and automating this task can help accelerate the process of discovery of materials with novel and desirable properties. Here, we report a new method for pattern analysis and phase extraction of XRD datasets. The method expands the Nonnegative Matrix Factorization method, which has been used previously to analyze such datasets, by combining it with custom clustering and cross-correlation algorithms. This new method is capable of robust determination of the number of basis patterns present in the data which, in turn, enables straightforward identification of any possible peak-shifted patterns. Peak-shifting arises due to continuous change in the lattice constants as a function of composition, and is ubiquitous in XRD datasets from composition spread libraries. Successful identification of the peak-shifted patterns allows proper quantification and classification of the basis XRD patterns, which is necessary in order to decipher the contribution of each unique single-phase structure to the multi-phase regions. The process can be utilized to determine accurately the compositional phase diagram of a system under study. The presented method is applied to one synthetic and one experimental dataset, and demonstrates robust accuracy and identification abilities.
* 26 pages, 9 figures
Nonnegative/binary matrix factorization with a D-Wave quantum annealer
Apr 05, 2017

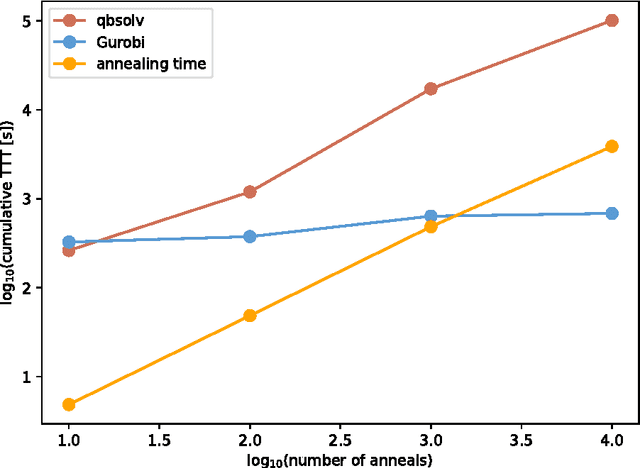
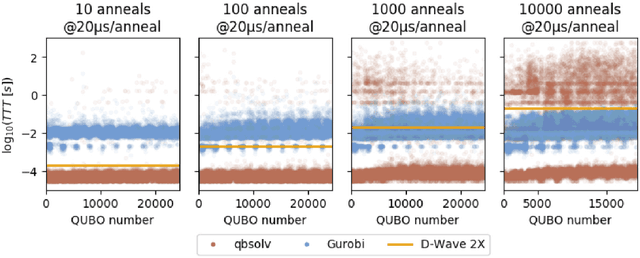
D-Wave quantum annealers represent a novel computational architecture and have attracted significant interest, but have been used for few real-world computations. Machine learning has been identified as an area where quantum annealing may be useful. Here, we show that the D-Wave 2X can be effectively used as part of an unsupervised machine learning method. This method can be used to analyze large datasets. The D-Wave only limits the number of features that can be extracted from the dataset. We apply this method to learn the features from a set of facial images.