 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Testing Framework for Clustering Pipelines by Selective Inference
Mar 19, 2026A data analysis pipeline is a structured sequence of steps that transforms raw data into meaningful insights by integrating multiple analysis algorithms.In many practical applications, analytical findings are obtained only after data pass through several data-dependent procedures within such pipelines.In this study, we address the problem of quantifying the statistical reliability of results produced by data analysis pipelines.As a proof of concept, we focus on clustering pipelines that identify cluster structures from complex and heterogeneous data through procedures such as outlier detection, feature selection, and clustering.We propose a novel statistical testing framework to assess the significance of clustering results obtained through these pipelines.Our framework, based on selective inference, enables the systematic construction of valid statistical tests for clustering pipelines composed of predefined components.We prove that the proposed test controls the type I error rate at any nominal level and demonstrate its validity and effectiveness through experiments on synthetic and real datasets.
Safe Distributionally Robust Feature Selection under Covariate Shift
Mar 17, 2026In practical machine learning, the environments encountered during the model development and deployment phases often differ, especially when a model is used by many users in diverse settings. Learning models that maintain reliable performance across plausible deployment environments is known as distributionally robust (DR) learning. In this work, we study the problem of distributionally robust feature selection (DRFS), with a particular focus on sparse sensing applications motivated by industrial needs. In practical multi-sensor systems, a shared subset of sensors is typically selected prior to deployment based on performance evaluations using many available sensors. At deployment, individual users may further adapt or fine-tune models to their specific environments. When deployment environments differ from those anticipated during development, this strategy can result in systems lacking sensors required for optimal performance. To address this issue, we propose safe-DRFS, a novel approach that extends safe screening from conventional sparse modeling settings to a DR setting under covariate shift. Our method identifies a feature subset that encompasses all subsets that may become optimal across a specified range of input distribution shifts, with finite-sample theoretical guarantees of no false feature elimination.
Randomized Kiring Believer for Parallel Bayesian Optimization with Regret Bounds
Mar 02, 2026We consider an optimization problem of an expensive-to-evaluate black-box function, in which we can obtain noisy function values in parallel. For this problem, parallel Bayesian optimization (PBO) is a promising approach, which aims to optimize with fewer function evaluations by selecting a diverse input set for parallel evaluation. However, existing PBO methods suffer from poor practical performance or lack theoretical guarantees. In this study, we propose a PBO method, called randomized kriging believer (KB), based on a well-known KB heuristic and inheriting the advantages of the original KB: low computational complexity, a simple implementation, versatility across various BO methods, and applicability to asynchronous parallelization. Furthermore, we show that our randomized KB achieves Bayesian expected regret guarantees. We demonstrate the effectiveness of the proposed method through experiments on synthetic and benchmark functions and emulators of real-world data.
Quantum Kernel Machine Learning for Autonomous Materials Science
Jan 16, 2026Autonomous materials science, where active learning is used to navigate large compositional phase space, has emerged as a powerful vehicle to rapidly explore new materials. A crucial aspect of autonomous materials science is exploring new materials using as little data as possible. Gaussian process-based active learning allows effective charting of multi-dimensional parameter space with a limited number of training data, and thus is a common algorithmic choice for autonomous materials science. An integral part of the autonomous workflow is the application of kernel functions for quantifying similarities among measured data points. A recent theoretical breakthrough has shown that quantum kernel models can achieve similar performance with less training data than classical models. This signals the possible advantage of applying quantum kernel machine learning to autonomous materials discovery. In this work, we compare quantum and classical kernels for their utility in sequential phase space navigation for autonomous materials science. Specifically, we compute a quantum kernel and several classical kernels for x-ray diffraction patterns taken from an Fe-Ga-Pd ternary composition spread library. We conduct our study on both IonQ's Aria trapped ion quantum computer hardware and the corresponding classical noisy simulator. We experimentally verify that a quantum kernel model can outperform some classical kernel models. The results highlight the potential of quantum kernel machine learning methods for accelerating materials discovery and suggest complex x-ray diffraction data is a candidate for robust quantum kernel model advantage.
Statistical Test for Saliency Maps of Graph Neural Networks via Selective Inference
May 22, 2025Graph Neural Networks (GNNs) have gained prominence for their ability to process graph-structured data across various domains. However, interpreting GNN decisions remains a significant challenge, leading to the adoption of saliency maps for identifying influential nodes and edges. Despite their utility, the reliability of GNN saliency maps has been questioned, particularly in terms of their robustness to noise. In this study, we propose a statistical testing framework to rigorously evaluate the significance of saliency maps. Our main contribution lies in addressing the inflation of the Type I error rate caused by double-dipping of data, leveraging the framework of Selective Inference. Our method provides statistically valid $p$-values while controlling the Type I error rate, ensuring that identified salient subgraphs contain meaningful information rather than random artifacts. To demonstrate the effectiveness of our method, we conduct experiments on both synthetic and real-world datasets, showing its effectiveness in assessing the reliability of GNN interpretations.
Causal Discovery from Data Assisted by Large Language Models
Mar 18, 2025Knowledge driven discovery of novel materials necessitates the development of the causal models for the property emergence. While in classical physical paradigm the causal relationships are deduced based on the physical principles or via experiment, rapid accumulation of observational data necessitates learning causal relationships between dissimilar aspects of materials structure and functionalities based on observations. For this, it is essential to integrate experimental data with prior domain knowledge. Here we demonstrate this approach by combining high-resolution scanning transmission electron microscopy (STEM) data with insights derived from large language models (LLMs). By fine-tuning ChatGPT on domain-specific literature, such as arXiv papers on ferroelectrics, and combining obtained information with data-driven causal discovery, we construct adjacency matrices for Directed Acyclic Graphs (DAGs) that map the causal relationships between structural, chemical, and polarization degrees of freedom in Sm-doped BiFeO3 (SmBFO). This approach enables us to hypothesize how synthesis conditions influence material properties, particularly the coercive field (E0), and guides experimental validation. The ultimate objective of this work is to develop a unified framework that integrates LLM-driven literature analysis with data-driven discovery, facilitating the precise engineering of ferroelectric materials by establishing clear connections between synthesis conditions and their resulting material properties.
Rapid analysis of point-contact Andreev reflection spectra via machine learning with adaptive data augmentation
Mar 13, 2025


Delineating the superconducting order parameters is a pivotal task in investigating superconductivity for probing pairing mechanisms, as well as their symmetry and topology. Point-contact Andreev reflection (PCAR) measurement is a simple yet powerful tool for identifying the order parameters. The PCAR spectra exhibit significant variations depending on the type of the order parameter in a superconductor, including its magnitude ($\mathit{\Delta}$), as well as temperature, interfacial quality, Fermi velocity mismatch, and other factors. The information on the order parameter can be obtained by finding the combination of these parameters, generating a theoretical spectrum that fits a measured experimental spectrum. However, due to the complexity of the spectra and the high dimensionality of parameters, extracting the fitting parameters is often time-consuming and labor-intensive. In this study, we employ a convolutional neural network (CNN) algorithm to create models for rapid and automated analysis of PCAR spectra of various superconductors with different pairing symmetries (conventional $s$-wave, chiral $p_x+ip_y$-wave, and $d_{x^2-y^2}$-wave). The training datasets are generated based on the Blonder-Tinkham-Klapwijk (BTK) theory and further modified and augmented by selectively incorporating noise and peaks according to the bias voltages. This approach not only replicates the experimental spectra but also brings the model's attention to important features within the spectra. The optimized models provide fitting parameters for experimentally measured spectra in less than 100 ms per spectrum. Our approaches and findings pave the way for rapid and automated spectral analysis which will help accelerate research on superconductors with complex order parameters.
Explainable Classifier for Malignant Lymphoma Subtyping via Cell Graph and Image Fusion
Mar 02, 2025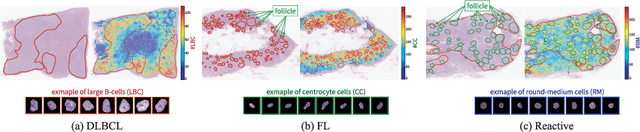
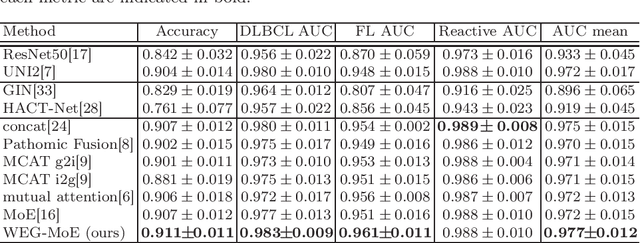
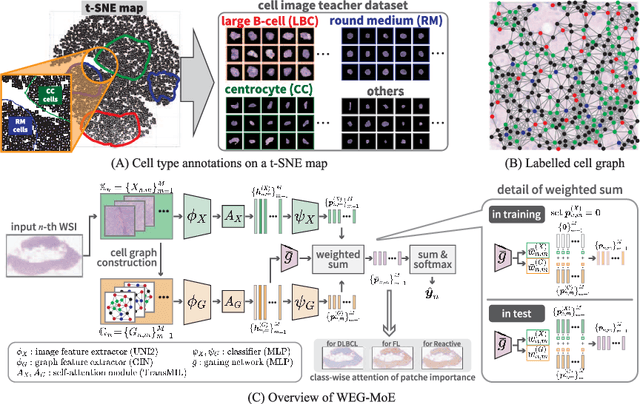
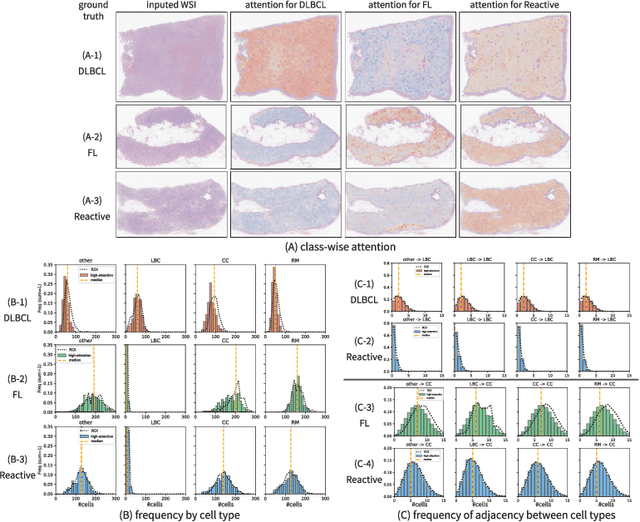
Malignant lymphoma subtype classification directly impacts treatment strategies and patient outcomes, necessitating classification models that achieve both high accuracy and sufficient explainability. This study proposes a novel explainable Multi-Instance Learning (MIL) framework that identifies subtype-specific Regions of Interest (ROIs) from Whole Slide Images (WSIs) while integrating cell distribution characteristics and image information. Our framework simultaneously addresses three objectives: (1) indicating appropriate ROIs for each subtype, (2) explaining the frequency and spatial distribution of characteristic cell types, and (3) achieving high-accuracy subtyping by leveraging both image and cell-distribution modalities. The proposed method fuses cell graph and image features extracted from each patch in the WSI using a Mixture-of-Experts (MoE) approach and classifies subtypes within an MIL framework. Experiments on a dataset of 1,233 WSIs demonstrate that our approach achieves state-of-the-art accuracy among ten comparative methods and provides region-level and cell-level explanations that align with a pathologist's perspectives.
Distributionally Robust Active Learning for Gaussian Process Regression
Feb 24, 2025Gaussian process regression (GPR) or kernel ridge regression is a widely used and powerful tool for nonlinear prediction. Therefore, active learning (AL) for GPR, which actively collects data labels to achieve an accurate prediction with fewer data labels, is an important problem. However, existing AL methods do not theoretically guarantee prediction accuracy for target distribution. Furthermore, as discussed in the distributionally robust learning literature, specifying the target distribution is often difficult. Thus, this paper proposes two AL methods that effectively reduce the worst-case expected error for GPR, which is the worst-case expectation in target distribution candidates. We show an upper bound of the worst-case expected squared error, which suggests that the error will be arbitrarily small by a finite number of data labels under mild conditions. Finally, we demonstrate the effectiveness of the proposed methods through synthetic and real-world datasets.
Statistically Significant $k$NNAD by Selective Inference
Feb 18, 2025In this paper, we investigate the problem of unsupervised anomaly detection using the k-Nearest Neighbor method. The k-Nearest Neighbor Anomaly Detection (kNNAD) is a simple yet effective approach for identifying anomalies across various domains and fields. A critical challenge in anomaly detection, including kNNAD, is appropriately quantifying the reliability of detected anomalies. To address this, we formulate kNNAD as a statistical hypothesis test and quantify the probability of false detection using $p$-values. The main technical challenge lies in performing both anomaly detection and statistical testing on the same data, which hinders correct $p$-value calculation within the conventional statistical testing framework. To resolve this issue, we introduce a statistical hypothesis testing framework called Selective Inference (SI) and propose a method named Statistically Significant NNAD (Stat-kNNAD). By leveraging SI, the Stat-kNNAD method ensures that detected anomalies are statistically significant with theoretical guarantees. The proposed Stat-kNNAD method is applicable to anomaly detection in both the original feature space and latent feature spaces derived from deep learning models. Through numerical experiments on synthetic data and applications to industrial product anomaly detection, we demonstrate the validity and effectiveness of the Stat-kNNAD method.