 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Active Learning for Gaussian Process Regression
Feb 24, 2025Gaussian process regression (GPR) or kernel ridge regression is a widely used and powerful tool for nonlinear prediction. Therefore, active learning (AL) for GPR, which actively collects data labels to achieve an accurate prediction with fewer data labels, is an important problem. However, existing AL methods do not theoretically guarantee prediction accuracy for target distribution. Furthermore, as discussed in the distributionally robust learning literature, specifying the target distribution is often difficult. Thus, this paper proposes two AL methods that effectively reduce the worst-case expected error for GPR, which is the worst-case expectation in target distribution candidates. We show an upper bound of the worst-case expected squared error, which suggests that the error will be arbitrarily small by a finite number of data labels under mild conditions. Finally, we demonstrate the effectiveness of the proposed methods through synthetic and real-world datasets.
Generalized Kernel Inducing Points by Duality Gap for Dataset Distillation
Feb 18, 2025We propose Duality Gap KIP (DGKIP), an extension of the Kernel Inducing Points (KIP) method for dataset distillation. While existing dataset distillation methods often rely on bi-level optimization, DGKIP eliminates the need for such optimization by leveraging duality theory in convex programming. The KIP method has been introduced as a way to avoid bi-level optimization; however, it is limited to the squared loss and does not support other loss functions (e.g., cross-entropy or hinge loss) that are more suitable for classification tasks. DGKIP addresses this limitation by exploiting an upper bound on parameter changes after dataset distillation using the duality gap, enabling its application to a wider range of loss functions. We also characterize theoretical properties of DGKIP by providing upper bounds on the test error and prediction consistency after dataset distillation. Experimental results on standard benchmarks such as MNIST and CIFAR-10 demonstrate that DGKIP retains the efficiency of KIP while offering broader applicability and robust performance.
Distributionally Robust Coreset Selection under Covariate Shift
Jan 24, 2025Coreset selection, which involves selecting a small subset from an existing training dataset, is an approach to reducing training data, and various approaches have been proposed for this method. In practical situations where these methods are employed, it is often the case that the data distributions differ between the development phase and the deployment phase, with the latter being unknown. Thus, it is challenging to select an effective subset of training data that performs well across all deployment scenarios. We therefore propose Distributionally Robust Coreset Selection (DRCS). DRCS theoretically derives an estimate of the upper bound for the worst-case test error, assuming that the future covariate distribution may deviate within a defined range from the training distribution. Furthermore, by selecting instances in a way that suppresses the estimate of the upper bound for the worst-case test error, DRCS achieves distributionally robust training instance selection. This study is primarily applicable to convex training computation, but we demonstrate that it can also be applied to deep learning under appropriate approximations. In this paper, we focus on covariate shift, a type of data distribution shift, and demonstrate the effectiveness of DRCS through experiments.
Distributionally Robust Safe Sample Screening
Jun 10, 2024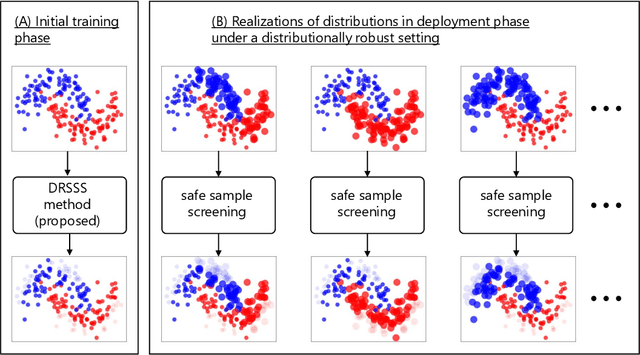


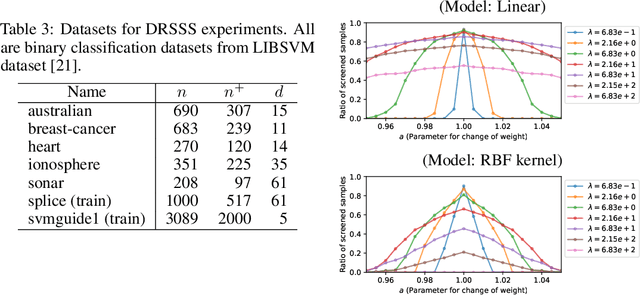
In this study, we propose a machine learning method called Distributionally Robust Safe Sample Screening (DRSSS). DRSSS aims to identify unnecessary training samples, even when the distribution of the training samples changes in the future. To achieve this, we effectively combine the distributionally robust (DR) paradigm, which aims to enhance model robustness against variations in data distribution, with the safe sample screening (SSS), which identifies unnecessary training samples prior to model training. Since we need to consider an infinite number of scenarios regarding changes in the distribution, we applied SSS because it does not require model training after the change of the distribution. In this paper, we employed the covariate shift framework to represent the distribution of training samples and reformulated the DR covariate-shift problem as a weighted empirical risk minimization problem, where the weights are subject to uncertainty within a predetermined range. By extending the existing SSS technique to accommodate this weight uncertainty, the DRSSS method is capable of reliably identifying unnecessary samples under any future distribution within a specified range. We provide a theoretical guarantee for the DRSSS method and validate its performance through numerical experiments on both synthetic and real-world datasets.
$f$-Cal: Calibrated aleatoric uncertainty estimation from neural networks for robot perception
Sep 28, 2021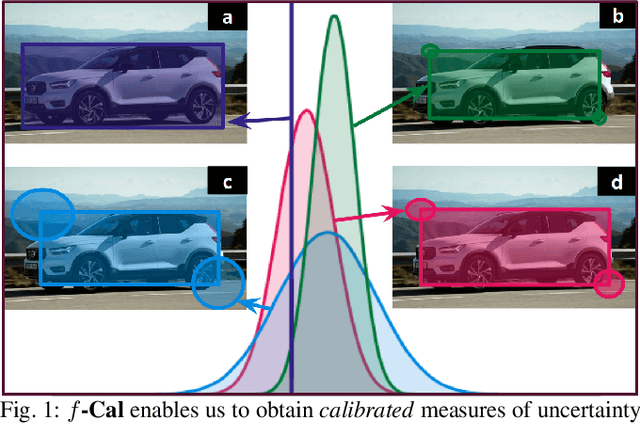
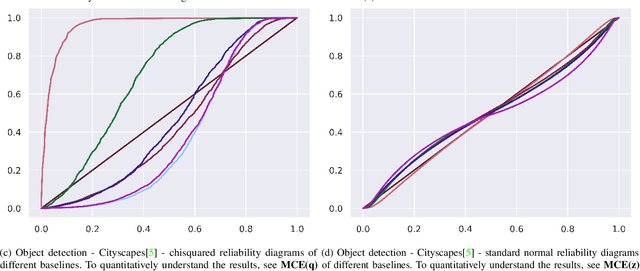
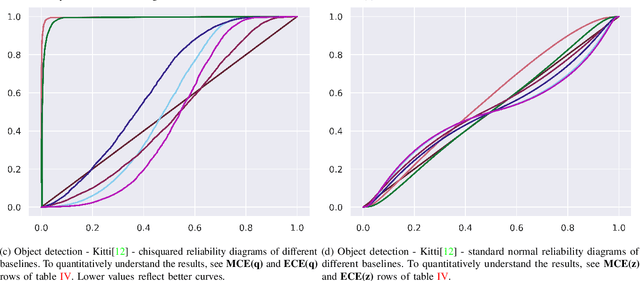
While modern deep neural networks are performant perception modules, performance (accuracy) alone is insufficient, particularly for safety-critical robotic applications such as self-driving vehicles. Robot autonomy stacks also require these otherwise blackbox models to produce reliable and calibrated measures of confidence on their predictions. Existing approaches estimate uncertainty from these neural network perception stacks by modifying network architectures, inference procedure, or loss functions. However, in general, these methods lack calibration, meaning that the predictive uncertainties do not faithfully represent the true underlying uncertainties (process noise). Our key insight is that calibration is only achieved by imposing constraints across multiple examples, such as those in a mini-batch; as opposed to existing approaches which only impose constraints per-sample, often leading to overconfident (thus miscalibrated) uncertainty estimates. By enforcing the distribution of outputs of a neural network to resemble a target distribution by minimizing an $f$-divergence, we obtain significantly better-calibrated models compared to prior approaches. Our approach, $f$-Cal, outperforms existing uncertainty calibration approaches on robot perception tasks such as object detection and monocular depth estimation over multiple real-world benchmarks.