 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal-Point Variance Reduction For Bayesian Optimization With Regret Guarantee
May 31, 2026This paper studies a one-step lookahead Bayesian optimization (BO) method and its theoretical guarantee. Although the empirical effectiveness of one-step lookahead BO methods, such as entropy search, has been studied extensively, they often rely on computationally intractable approximations, and their regret guarantees remain underdeveloped. Thus, this paper proposes a one-step lookahead BO method called optimal-point variance reduction (OVR), which requires only posterior sampling and Monte Carlo approximations. We obtain a uniform error bound over an input domain for the Monte Carlo estimation in OVR. Furthermore, we show that the regularized OVR, with the slight modification to promote exploration, achieves a vanishing Bayesian expected simple regret upper bound. Finally, we demonstrate the effectiveness of OVR through numerical experiments.
Safe Distributionally Robust Feature Selection under Covariate Shift
Mar 17, 2026In practical machine learning, the environments encountered during the model development and deployment phases often differ, especially when a model is used by many users in diverse settings. Learning models that maintain reliable performance across plausible deployment environments is known as distributionally robust (DR) learning. In this work, we study the problem of distributionally robust feature selection (DRFS), with a particular focus on sparse sensing applications motivated by industrial needs. In practical multi-sensor systems, a shared subset of sensors is typically selected prior to deployment based on performance evaluations using many available sensors. At deployment, individual users may further adapt or fine-tune models to their specific environments. When deployment environments differ from those anticipated during development, this strategy can result in systems lacking sensors required for optimal performance. To address this issue, we propose safe-DRFS, a novel approach that extends safe screening from conventional sparse modeling settings to a DR setting under covariate shift. Our method identifies a feature subset that encompasses all subsets that may become optimal across a specified range of input distribution shifts, with finite-sample theoretical guarantees of no false feature elimination.
On Regret Bounds of Thompson Sampling for Bayesian Optimization
Mar 10, 2026We study a widely used Bayesian optimization method, Gaussian process Thompson sampling (GP-TS), under the assumption that the objective function is a sample path from a GP. Compared with the GP upper confidence bound (GP-UCB) with established high-probability and expected regret bounds, most analyses of GP-TS have been limited to expected regret. Moreover, whether the recent analyses of GP-UCB for the lenient regret and the improved cumulative regret upper bound can be applied to GP-TS remains unclear. To fill these gaps, this paper shows several regret bounds: (i) a regret lower bound for GP-TS, which implies that GP-TS suffers from a polynomial dependence on $1/δ$ with probability $δ$, (ii) an upper bound of the second moment of cumulative regret, which directly suggests an improved regret upper bound on $δ$, (iii) expected lenient regret upper bounds, and (iv) an improved cumulative regret upper bound on the time horizon $T$. Along the way, we provide several useful lemmas, including a relaxation of the necessary condition from recent analysis to obtain improved regret upper bounds on $T$.
Randomized Kiring Believer for Parallel Bayesian Optimization with Regret Bounds
Mar 02, 2026We consider an optimization problem of an expensive-to-evaluate black-box function, in which we can obtain noisy function values in parallel. For this problem, parallel Bayesian optimization (PBO) is a promising approach, which aims to optimize with fewer function evaluations by selecting a diverse input set for parallel evaluation. However, existing PBO methods suffer from poor practical performance or lack theoretical guarantees. In this study, we propose a PBO method, called randomized kriging believer (KB), based on a well-known KB heuristic and inheriting the advantages of the original KB: low computational complexity, a simple implementation, versatility across various BO methods, and applicability to asynchronous parallelization. Furthermore, we show that our randomized KB achieves Bayesian expected regret guarantees. We demonstrate the effectiveness of the proposed method through experiments on synthetic and benchmark functions and emulators of real-world data.
Dose-finding design based on level set estimation in phase I cancer clinical trials
Apr 12, 2025The primary objective of phase I cancer clinical trials is to evaluate the safety of a new experimental treatment and to find the maximum tolerated dose (MTD). We show that the MTD estimation problem can be regarded as a level set estimation (LSE) problem whose objective is to determine the regions where an unknown function value is above or below a given threshold. Then, we propose a novel dose-finding design in the framework of LSE. The proposed design determines the next dose on the basis of an acquisition function incorporating uncertainty in the posterior distribution of the dose-toxicity curve as well as overdose control. Simulation experiments show that the proposed LSE design achieves a higher accuracy in estimating the MTD and involves a lower risk of overdosing allocation compared to existing designs, thereby indicating that it provides an effective methodology for phase I cancer clinical trial design.
Distributionally Robust Active Learning for Gaussian Process Regression
Feb 24, 2025Gaussian process regression (GPR) or kernel ridge regression is a widely used and powerful tool for nonlinear prediction. Therefore, active learning (AL) for GPR, which actively collects data labels to achieve an accurate prediction with fewer data labels, is an important problem. However, existing AL methods do not theoretically guarantee prediction accuracy for target distribution. Furthermore, as discussed in the distributionally robust learning literature, specifying the target distribution is often difficult. Thus, this paper proposes two AL methods that effectively reduce the worst-case expected error for GPR, which is the worst-case expectation in target distribution candidates. We show an upper bound of the worst-case expected squared error, which suggests that the error will be arbitrarily small by a finite number of data labels under mild conditions. Finally, we demonstrate the effectiveness of the proposed methods through synthetic and real-world datasets.
Improved Regret Analysis in Gaussian Process Bandits: Optimality for Noiseless Reward, RKHS norm, and Non-Stationary Variance
Feb 10, 2025



We study the Gaussian process (GP) bandit problem, whose goal is to minimize regret under an unknown reward function lying in some reproducing kernel Hilbert space (RKHS). The maximum posterior variance analysis is vital in analyzing near-optimal GP bandit algorithms such as maximum variance reduction (MVR) and phased elimination (PE). Therefore, we first show the new upper bound of the maximum posterior variance, which improves the dependence of the noise variance parameters of the GP. By leveraging this result, we refine the MVR and PE to obtain (i) a nearly optimal regret upper bound in the noiseless setting and (ii) regret upper bounds that are optimal with respect to the RKHS norm of the reward function. Furthermore, as another application of our proposed bound, we analyze the GP bandit under the time-varying noise variance setting, which is the kernelized extension of the linear bandit with heteroscedastic noise. For this problem, we show that MVR and PE-based algorithms achieve noise variance-dependent regret upper bounds, which matches our regret lower bound.
Near-Optimal Algorithm for Non-Stationary Kernelized Bandits
Oct 21, 2024


This paper studies a non-stationary kernelized bandit (KB) problem, also called time-varying Bayesian optimization, where one seeks to minimize the regret under an unknown reward function that varies over time. In particular, we focus on a near-optimal algorithm whose regret upper bound matches the regret lower bound. For this goal, we show the first algorithm-independent regret lower bound for non-stationary KB with squared exponential and Mat\'ern kernels, which reveals that an existing optimization-based KB algorithm with slight modification is near-optimal. However, this existing algorithm suffers from feasibility issues due to its huge computational cost. Therefore, we propose a novel near-optimal algorithm called restarting phased elimination with random permutation (R-PERP), which bypasses the huge computational cost. A technical key point is the simple permutation procedures of query candidates, which enable us to derive a novel tighter confidence bound tailored to the non-stationary problems.
Regret Analysis for Randomized Gaussian Process Upper Confidence Bound
Sep 02, 2024Gaussian process upper confidence bound (GP-UCB) is a theoretically established algorithm for Bayesian optimization (BO), where we assume the objective function $f$ follows GP. One notable drawback of GP-UCB is that the theoretical confidence parameter $\beta$ increased along with the iterations is too large. To alleviate this drawback, this paper analyzes the randomized variant of GP-UCB called improved randomized GP-UCB (IRGP-UCB), which uses the confidence parameter generated from the shifted exponential distribution. We analyze the expected regret and conditional expected regret, where the expectation and the probability are taken respectively with $f$ and noises and with the randomness of the BO algorithm. In both regret analyses, IRGP-UCB achieves a sub-linear regret upper bound without increasing the confidence parameter if the input domain is finite. Finally, we show numerical experiments using synthetic and benchmark functions and real-world emulators.
Distributionally Robust Safe Sample Screening
Jun 10, 2024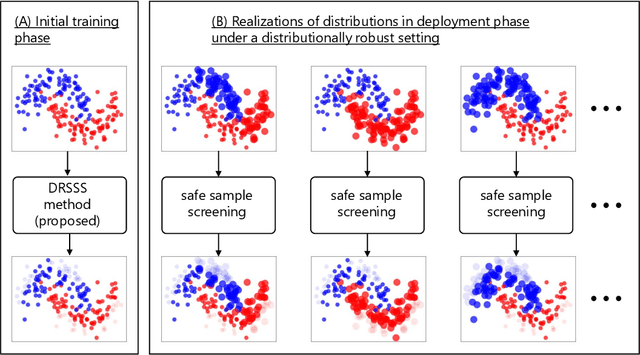


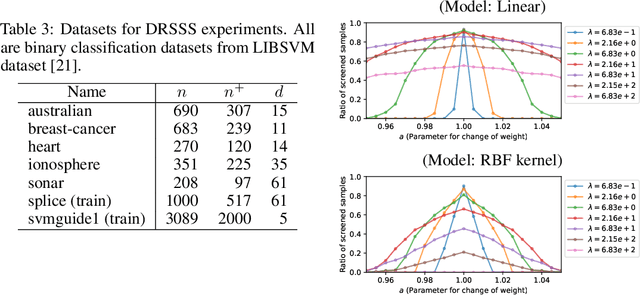
In this study, we propose a machine learning method called Distributionally Robust Safe Sample Screening (DRSSS). DRSSS aims to identify unnecessary training samples, even when the distribution of the training samples changes in the future. To achieve this, we effectively combine the distributionally robust (DR) paradigm, which aims to enhance model robustness against variations in data distribution, with the safe sample screening (SSS), which identifies unnecessary training samples prior to model training. Since we need to consider an infinite number of scenarios regarding changes in the distribution, we applied SSS because it does not require model training after the change of the distribution. In this paper, we employed the covariate shift framework to represent the distribution of training samples and reformulated the DR covariate-shift problem as a weighted empirical risk minimization problem, where the weights are subject to uncertainty within a predetermined range. By extending the existing SSS technique to accommodate this weight uncertainty, the DRSSS method is capable of reliably identifying unnecessary samples under any future distribution within a specified range. We provide a theoretical guarantee for the DRSSS method and validate its performance through numerical experiments on both synthetic and real-world datasets.