 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearly-Optimal Algorithm for Adversarial Kernelized Bandits
May 11, 2026This paper studies kernelized bandits (also known as Gaussian process bandits) in an adversarial environment, where the reward functions in a known reproducing kernel Hilbert space (RKHS) may be adversarially chosen at each round. We show that the exponential-weight algorithm achieves $\tilde{O}(\sqrt{T γ_T})$ adversarial regret, where $T$ and $γ_T$ denote the number of total rounds and the maximum information gain, respectively. For squared exponential (SE) and $ν$-Matérn kernels, we also show algorithm-independent lower bounds that guarantee the optimality of our algorithm up to polylogarithmic factors. Furthermore, we present a computationally efficient variant of our algorithm using Nyström approximation while maintaining nearly optimal regret guarantees.
On Regret Bounds of Thompson Sampling for Bayesian Optimization
Mar 10, 2026We study a widely used Bayesian optimization method, Gaussian process Thompson sampling (GP-TS), under the assumption that the objective function is a sample path from a GP. Compared with the GP upper confidence bound (GP-UCB) with established high-probability and expected regret bounds, most analyses of GP-TS have been limited to expected regret. Moreover, whether the recent analyses of GP-UCB for the lenient regret and the improved cumulative regret upper bound can be applied to GP-TS remains unclear. To fill these gaps, this paper shows several regret bounds: (i) a regret lower bound for GP-TS, which implies that GP-TS suffers from a polynomial dependence on $1/δ$ with probability $δ$, (ii) an upper bound of the second moment of cumulative regret, which directly suggests an improved regret upper bound on $δ$, (iii) expected lenient regret upper bounds, and (iv) an improved cumulative regret upper bound on the time horizon $T$. Along the way, we provide several useful lemmas, including a relaxation of the necessary condition from recent analysis to obtain improved regret upper bounds on $T$.
High-dimensional Nonparametric Contextual Bandit Problem
May 20, 2025We consider the kernelized contextual bandit problem with a large feature space. This problem involves $K$ arms, and the goal of the forecaster is to maximize the cumulative rewards through learning the relationship between the contexts and the rewards. It serves as a general framework for various decision-making scenarios, such as personalized online advertising and recommendation systems. Kernelized contextual bandits generalize the linear contextual bandit problem and offers a greater modeling flexibility. Existing methods, when applied to Gaussian kernels, yield a trivial bound of $O(T)$ when we consider $\Omega(\log T)$ feature dimensions. To address this, we introduce stochastic assumptions on the context distribution and show that no-regret learning is achievable even when the number of dimensions grows up to the number of samples. Furthermore, we analyze lenient regret, which allows a per-round regret of at most $\Delta > 0$. We derive the rate of lenient regret in terms of $\Delta$.
Dose-finding design based on level set estimation in phase I cancer clinical trials
Apr 12, 2025The primary objective of phase I cancer clinical trials is to evaluate the safety of a new experimental treatment and to find the maximum tolerated dose (MTD). We show that the MTD estimation problem can be regarded as a level set estimation (LSE) problem whose objective is to determine the regions where an unknown function value is above or below a given threshold. Then, we propose a novel dose-finding design in the framework of LSE. The proposed design determines the next dose on the basis of an acquisition function incorporating uncertainty in the posterior distribution of the dose-toxicity curve as well as overdose control. Simulation experiments show that the proposed LSE design achieves a higher accuracy in estimating the MTD and involves a lower risk of overdosing allocation compared to existing designs, thereby indicating that it provides an effective methodology for phase I cancer clinical trial design.
Gaussian Process Upper Confidence Bound Achieves Nearly-Optimal Regret in Noise-Free Gaussian Process Bandits
Feb 26, 2025We study the noise-free Gaussian Process (GP) bandits problem, in which the learner seeks to minimize regret through noise-free observations of the black-box objective function lying on the known reproducing kernel Hilbert space (RKHS). Gaussian process upper confidence bound (GP-UCB) is the well-known GP-bandits algorithm whose query points are adaptively chosen based on the GP-based upper confidence bound score. Although several existing works have reported the practical success of GP-UCB, the current theoretical results indicate its suboptimal performance. However, GP-UCB tends to perform well empirically compared with other nearly optimal noise-free algorithms that rely on a non-adaptive sampling scheme of query points. This paper resolves this gap between theoretical and empirical performance by showing the nearly optimal regret upper bound of noise-free GP-UCB. Specifically, our analysis shows the first constant cumulative regret in the noise-free settings for the squared exponential kernel and Mat\'ern kernel with some degree of smoothness.
Improved Regret Analysis in Gaussian Process Bandits: Optimality for Noiseless Reward, RKHS norm, and Non-Stationary Variance
Feb 10, 2025



We study the Gaussian process (GP) bandit problem, whose goal is to minimize regret under an unknown reward function lying in some reproducing kernel Hilbert space (RKHS). The maximum posterior variance analysis is vital in analyzing near-optimal GP bandit algorithms such as maximum variance reduction (MVR) and phased elimination (PE). Therefore, we first show the new upper bound of the maximum posterior variance, which improves the dependence of the noise variance parameters of the GP. By leveraging this result, we refine the MVR and PE to obtain (i) a nearly optimal regret upper bound in the noiseless setting and (ii) regret upper bounds that are optimal with respect to the RKHS norm of the reward function. Furthermore, as another application of our proposed bound, we analyze the GP bandit under the time-varying noise variance setting, which is the kernelized extension of the linear bandit with heteroscedastic noise. For this problem, we show that MVR and PE-based algorithms achieve noise variance-dependent regret upper bounds, which matches our regret lower bound.
Near-Optimal Algorithm for Non-Stationary Kernelized Bandits
Oct 21, 2024


This paper studies a non-stationary kernelized bandit (KB) problem, also called time-varying Bayesian optimization, where one seeks to minimize the regret under an unknown reward function that varies over time. In particular, we focus on a near-optimal algorithm whose regret upper bound matches the regret lower bound. For this goal, we show the first algorithm-independent regret lower bound for non-stationary KB with squared exponential and Mat\'ern kernels, which reveals that an existing optimization-based KB algorithm with slight modification is near-optimal. However, this existing algorithm suffers from feasibility issues due to its huge computational cost. Therefore, we propose a novel near-optimal algorithm called restarting phased elimination with random permutation (R-PERP), which bypasses the huge computational cost. A technical key point is the simple permutation procedures of query candidates, which enable us to derive a novel tighter confidence bound tailored to the non-stationary problems.
Bayesian Optimization for Cascade-type Multi-stage Processes
Nov 26, 2021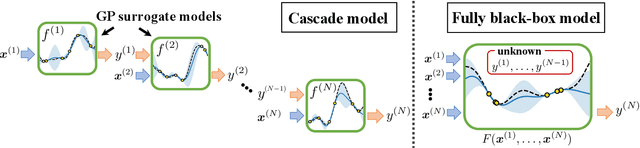
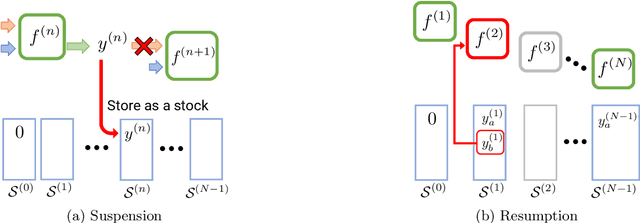
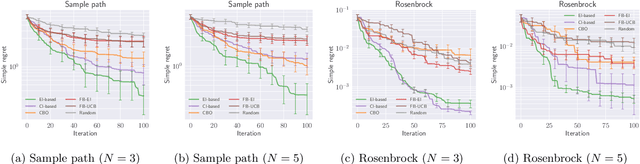
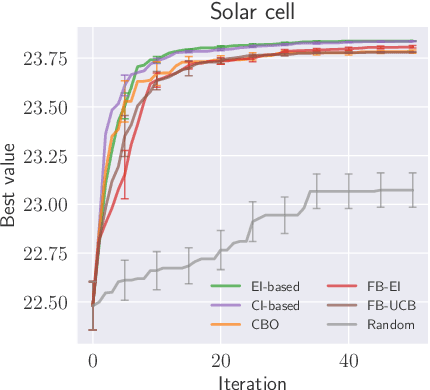
Complex processes in science and engineering are often formulated as multi-stage decision-making problems. In this paper, we consider a type of multi-stage decision-making process called a cascade process. A cascade process is a multi-stage process in which the output of one stage is used as an input for the next stage. When the cost of each stage is expensive, it is difficult to search for the optimal controllable parameters for each stage exhaustively. To address this problem, we formulate the optimization of the cascade process as an extension of Bayesian optimization framework and propose two types of acquisition functions (AFs) based on credible intervals and expected improvement. We investigate the theoretical properties of the proposed AFs and demonstrate their effectiveness through numerical experiments. In addition, we consider an extension called suspension setting in which we are allowed to suspend the cascade process at the middle of the multi-stage decision-making process that often arises in practical problems. We apply the proposed method in the optimization problem of the solar cell simulator, which was the motivation for this study.
Active learning for distributionally robust level-set estimation
Feb 08, 2021


Many cases exist in which a black-box function $f$ with high evaluation cost depends on two types of variables $\bm x$ and $\bm w$, where $\bm x$ is a controllable \emph{design} variable and $\bm w$ are uncontrollable \emph{environmental} variables that have random variation following a certain distribution $P$. In such cases, an important task is to find the range of design variables $\bm x$ such that the function $f(\bm x, \bm w)$ has the desired properties by incorporating the random variation of the environmental variables $\bm w$. A natural measure of robustness is the probability that $f(\bm x, \bm w)$ exceeds a given threshold $h$, which is known as the \emph{probability threshold robustness} (PTR) measure in the literature on robust optimization. However, this robustness measure cannot be correctly evaluated when the distribution $P$ is unknown. In this study, we addressed this problem by considering the \textit{distributionally robust PTR} (DRPTR) measure, which considers the worst-case PTR within given candidate distributions. Specifically, we studied the problem of efficiently identifying a reliable set $H$, which is defined as a region in which the DRPTR measure exceeds a certain desired probability $\alpha$, which can be interpreted as a level set estimation (LSE) problem for DRPTR. We propose a theoretically grounded and computationally efficient active learning method for this problem. We show that the proposed method has theoretical guarantees on convergence and accuracy, and confirmed through numerical experiments that the proposed method outperforms existing methods.
Quantifying Statistical Significance of Neural Network Representation-Driven Hypotheses by Selective Inference
Oct 05, 2020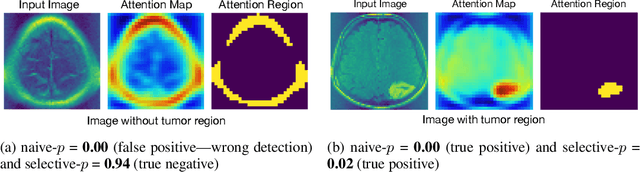
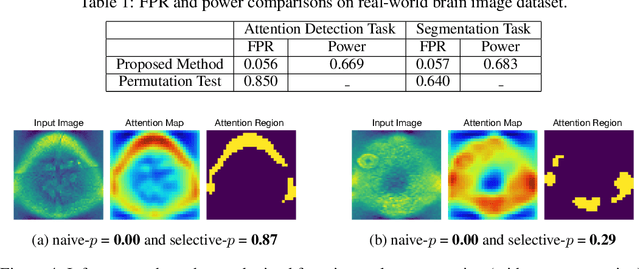
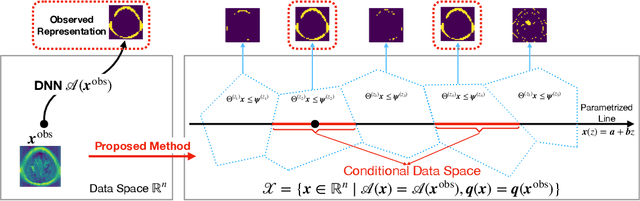
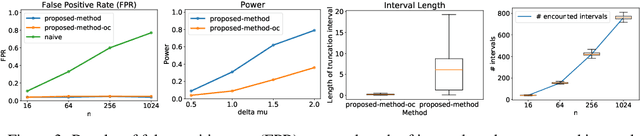
In the past few years, various approaches have been developed to explain and interpret deep neural network (DNN) representations, but it has been pointed out that these representations are sometimes unstable and not reproducible. In this paper, we interpret these representations as hypotheses driven by DNN (called DNN-driven hypotheses) and propose a method to quantify the reliability of these hypotheses in statistical hypothesis testing framework. To this end, we introduce Selective Inference (SI) framework, which has received much attention in the past few years as a new statistical inference framework for data-driven hypotheses. The basic idea of SI is to make conditional inferences on the selected hypotheses under the condition that they are selected. In order to use SI framework for DNN representations, we develop a new SI algorithm based on homotopy method which enables us to derive the exact (non-asymptotic) conditional sampling distribution of the DNN-driven hypotheses. We conduct experiments on both synthetic and real-world datasets, through which we offer evidence that our proposed method can successfully control the false positive rate, has decent performance in terms of computational efficiency, and provides good results in practical applications.