 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Optimization for Cascade-type Multi-stage Processes
Nov 26, 2021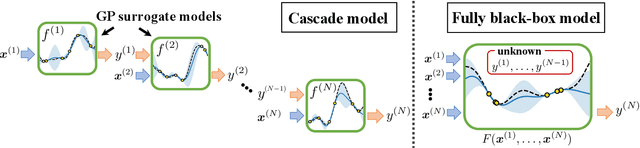
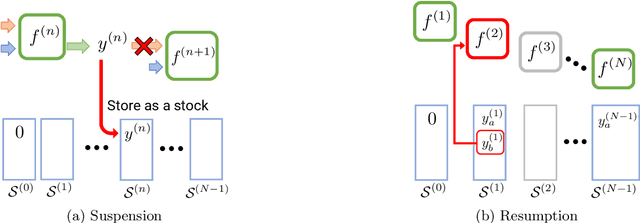
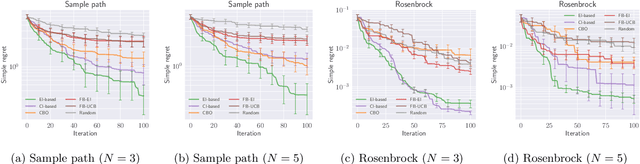
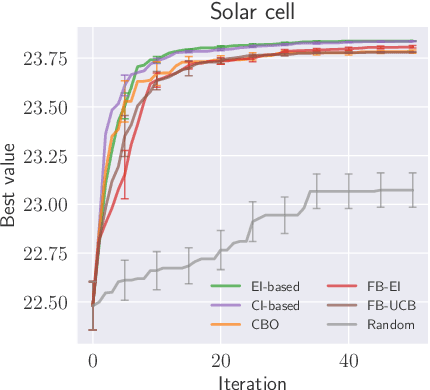
Complex processes in science and engineering are often formulated as multi-stage decision-making problems. In this paper, we consider a type of multi-stage decision-making process called a cascade process. A cascade process is a multi-stage process in which the output of one stage is used as an input for the next stage. When the cost of each stage is expensive, it is difficult to search for the optimal controllable parameters for each stage exhaustively. To address this problem, we formulate the optimization of the cascade process as an extension of Bayesian optimization framework and propose two types of acquisition functions (AFs) based on credible intervals and expected improvement. We investigate the theoretical properties of the proposed AFs and demonstrate their effectiveness through numerical experiments. In addition, we consider an extension called suspension setting in which we are allowed to suspend the cascade process at the middle of the multi-stage decision-making process that often arises in practical problems. We apply the proposed method in the optimization problem of the solar cell simulator, which was the motivation for this study.
Reduced-Lead ECG Classifier Model Trained with DivideMix and Model Ensemble
Sep 24, 2021
Automatic diagnosis of multiple cardiac abnormalities from reduced-lead electrocardiogram (ECG) data is challenging. One of the reasons for this is the difficulty of defining labels from standard 12-lead data. Reduced-lead ECG data usually do not have identical characteristics of cardiac abnormalities because of the noisy label problem. Thus, there is an inconsistency in the annotated labels between the reduced-lead and 12-lead ECG data. To solve this, we propose deep neural network (DNN)-based ECG classifier models that incorporate DivideMix and stochastic weight averaging (SWA). DivideMix was used to refine the noisy label by using two separate models. Besides DivideMix, we used a model ensemble technique, SWA, which also focuses on the noisy label problem, to enhance the effect of the models generated by DivideMix. Our classifiers (ami_kagoshima) received scores of 0.49, 0.47, 0.48, 0.47, and 0.47 (ranked 9th, 10th, 10th, 11th, and 10th, respectively, out of 39 teams) for the 12-lead, 6-lead, 4-lead, 3-lead, and 2-lead versions, respectively, of the hidden test set with the challenge evaluation metric. We obtained the scores of 0.701, 0.686, 0.693, 0.693, and 0.685 on the 10-fold cross validation, and 0.623, 0.593, 0.606, 0.612, and 0.601 on the hidden validation set for each lead combination.