 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDose-finding design based on level set estimation in phase I cancer clinical trials
Apr 12, 2025The primary objective of phase I cancer clinical trials is to evaluate the safety of a new experimental treatment and to find the maximum tolerated dose (MTD). We show that the MTD estimation problem can be regarded as a level set estimation (LSE) problem whose objective is to determine the regions where an unknown function value is above or below a given threshold. Then, we propose a novel dose-finding design in the framework of LSE. The proposed design determines the next dose on the basis of an acquisition function incorporating uncertainty in the posterior distribution of the dose-toxicity curve as well as overdose control. Simulation experiments show that the proposed LSE design achieves a higher accuracy in estimating the MTD and involves a lower risk of overdosing allocation compared to existing designs, thereby indicating that it provides an effective methodology for phase I cancer clinical trial design.
Bayesian Optimization of Robustness Measures Using Randomized GP-UCB-based Algorithms under Input Uncertainty
Apr 04, 2025



Bayesian optimization based on Gaussian process upper confidence bound (GP-UCB) has a theoretical guarantee for optimizing black-box functions. Black-box functions often have input uncertainty, but even in this case, GP-UCB can be extended to optimize evaluation measures called robustness measures. However, GP-UCB-based methods for robustness measures include a trade-off parameter $\beta$, which must be excessively large to achieve theoretical validity, just like the original GP-UCB. In this study, we propose a new method called randomized robustness measure GP-UCB (RRGP-UCB), which samples the trade-off parameter $\beta$ from a probability distribution based on a chi-squared distribution and avoids explicitly specifying $\beta$. The expected value of $\beta$ is not excessively large. Furthermore, we show that RRGP-UCB provides tight bounds on the expected value of regret based on the optimal solution and estimated solutions. Finally, we demonstrate the usefulness of the proposed method through numerical experiments.
Distributionally Robust Active Learning for Gaussian Process Regression
Feb 24, 2025Gaussian process regression (GPR) or kernel ridge regression is a widely used and powerful tool for nonlinear prediction. Therefore, active learning (AL) for GPR, which actively collects data labels to achieve an accurate prediction with fewer data labels, is an important problem. However, existing AL methods do not theoretically guarantee prediction accuracy for target distribution. Furthermore, as discussed in the distributionally robust learning literature, specifying the target distribution is often difficult. Thus, this paper proposes two AL methods that effectively reduce the worst-case expected error for GPR, which is the worst-case expectation in target distribution candidates. We show an upper bound of the worst-case expected squared error, which suggests that the error will be arbitrarily small by a finite number of data labels under mild conditions. Finally, we demonstrate the effectiveness of the proposed methods through synthetic and real-world datasets.
Generalized Kernel Inducing Points by Duality Gap for Dataset Distillation
Feb 18, 2025We propose Duality Gap KIP (DGKIP), an extension of the Kernel Inducing Points (KIP) method for dataset distillation. While existing dataset distillation methods often rely on bi-level optimization, DGKIP eliminates the need for such optimization by leveraging duality theory in convex programming. The KIP method has been introduced as a way to avoid bi-level optimization; however, it is limited to the squared loss and does not support other loss functions (e.g., cross-entropy or hinge loss) that are more suitable for classification tasks. DGKIP addresses this limitation by exploiting an upper bound on parameter changes after dataset distillation using the duality gap, enabling its application to a wider range of loss functions. We also characterize theoretical properties of DGKIP by providing upper bounds on the test error and prediction consistency after dataset distillation. Experimental results on standard benchmarks such as MNIST and CIFAR-10 demonstrate that DGKIP retains the efficiency of KIP while offering broader applicability and robust performance.
Distributionally Robust Coreset Selection under Covariate Shift
Jan 24, 2025Coreset selection, which involves selecting a small subset from an existing training dataset, is an approach to reducing training data, and various approaches have been proposed for this method. In practical situations where these methods are employed, it is often the case that the data distributions differ between the development phase and the deployment phase, with the latter being unknown. Thus, it is challenging to select an effective subset of training data that performs well across all deployment scenarios. We therefore propose Distributionally Robust Coreset Selection (DRCS). DRCS theoretically derives an estimate of the upper bound for the worst-case test error, assuming that the future covariate distribution may deviate within a defined range from the training distribution. Furthermore, by selecting instances in a way that suppresses the estimate of the upper bound for the worst-case test error, DRCS achieves distributionally robust training instance selection. This study is primarily applicable to convex training computation, but we demonstrate that it can also be applied to deep learning under appropriate approximations. In this paper, we focus on covariate shift, a type of data distribution shift, and demonstrate the effectiveness of DRCS through experiments.
Regret Analysis for Randomized Gaussian Process Upper Confidence Bound
Sep 02, 2024Gaussian process upper confidence bound (GP-UCB) is a theoretically established algorithm for Bayesian optimization (BO), where we assume the objective function $f$ follows GP. One notable drawback of GP-UCB is that the theoretical confidence parameter $\beta$ increased along with the iterations is too large. To alleviate this drawback, this paper analyzes the randomized variant of GP-UCB called improved randomized GP-UCB (IRGP-UCB), which uses the confidence parameter generated from the shifted exponential distribution. We analyze the expected regret and conditional expected regret, where the expectation and the probability are taken respectively with $f$ and noises and with the randomness of the BO algorithm. In both regret analyses, IRGP-UCB achieves a sub-linear regret upper bound without increasing the confidence parameter if the input domain is finite. Finally, we show numerical experiments using synthetic and benchmark functions and real-world emulators.
Distributionally Robust Safe Sample Screening
Jun 10, 2024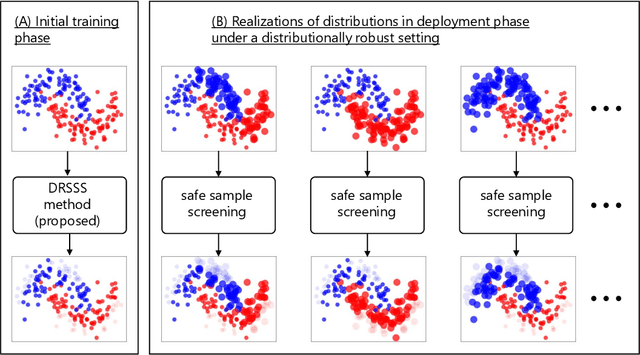


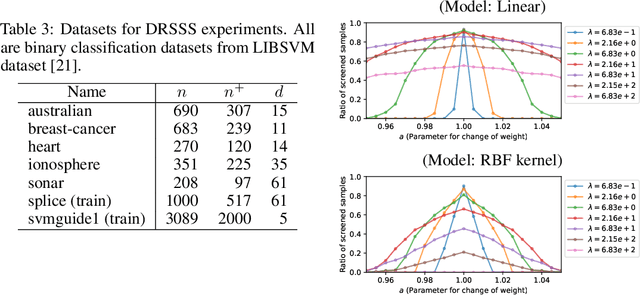
In this study, we propose a machine learning method called Distributionally Robust Safe Sample Screening (DRSSS). DRSSS aims to identify unnecessary training samples, even when the distribution of the training samples changes in the future. To achieve this, we effectively combine the distributionally robust (DR) paradigm, which aims to enhance model robustness against variations in data distribution, with the safe sample screening (SSS), which identifies unnecessary training samples prior to model training. Since we need to consider an infinite number of scenarios regarding changes in the distribution, we applied SSS because it does not require model training after the change of the distribution. In this paper, we employed the covariate shift framework to represent the distribution of training samples and reformulated the DR covariate-shift problem as a weighted empirical risk minimization problem, where the weights are subject to uncertainty within a predetermined range. By extending the existing SSS technique to accommodate this weight uncertainty, the DRSSS method is capable of reliably identifying unnecessary samples under any future distribution within a specified range. We provide a theoretical guarantee for the DRSSS method and validate its performance through numerical experiments on both synthetic and real-world datasets.
Distributionally Robust Safe Screening
Apr 25, 2024In this study, we propose a method Distributionally Robust Safe Screening (DRSS), for identifying unnecessary samples and features within a DR covariate shift setting. This method effectively combines DR learning, a paradigm aimed at enhancing model robustness against variations in data distribution, with safe screening (SS), a sparse optimization technique designed to identify irrelevant samples and features prior to model training. The core concept of the DRSS method involves reformulating the DR covariate-shift problem as a weighted empirical risk minimization problem, where the weights are subject to uncertainty within a predetermined range. By extending the SS technique to accommodate this weight uncertainty, the DRSS method is capable of reliably identifying unnecessary samples and features under any future distribution within a specified range. We provide a theoretical guarantee of the DRSS method and validate its performance through numerical experiments on both synthetic and real-world datasets.
Posterior Sampling-Based Bayesian Optimization with Tighter Bayesian Regret Bounds
Nov 07, 2023Among various acquisition functions (AFs) in Bayesian optimization (BO), Gaussian process upper confidence bound (GP-UCB) and Thompson sampling (TS) are well-known options with established theoretical properties regarding Bayesian cumulative regret (BCR). Recently, it has been shown that a randomized variant of GP-UCB achieves a tighter BCR bound compared with GP-UCB, which we call the tighter BCR bound for brevity. Inspired by this study, this paper first shows that TS achieves the tighter BCR bound. On the other hand, GP-UCB and TS often practically suffer from manual hyperparameter tuning and over-exploration issues, respectively. To overcome these difficulties, we propose yet another AF called a probability of improvement from the maximum of a sample path (PIMS). We show that PIMS achieves the tighter BCR bound and avoids the hyperparameter tuning, unlike GP-UCB. Furthermore, we demonstrate a wide range of experiments, focusing on the effectiveness of PIMS that mitigates the practical issues of GP-UCB and TS.
Randomized Gaussian Process Upper Confidence Bound with Tight Bayesian Regret Bounds
Feb 03, 2023Gaussian process upper confidence bound (GP-UCB) is a theoretically promising approach for black-box optimization; however, the confidence parameter $\beta$ is considerably large in the theorem and chosen heuristically in practice. Then, randomized GP-UCB (RGP-UCB) uses a randomized confidence parameter, which follows the Gamma distribution, to mitigate the impact of manually specifying $\beta$. This study first generalizes the regret analysis of RGP-UCB to a wider class of distributions, including the Gamma distribution. Furthermore, we propose improved RGP-UCB (IRGP-UCB) based on a two-parameter exponential distribution, which achieves tight Bayesian regret bounds. IRGP-UCB does not require an increase in the confidence parameter in terms of the number of iterations, which avoids over-exploration in the later iterations. Finally, we demonstrate the effectiveness of IRGP-UCB through extensive experiments.