 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnpacking Let Alone: Human-Scale Models Generalize to a Rare Construction in Form but not Meaning
Jun 04, 2025Humans have a remarkable ability to acquire and understand grammatical phenomena that are seen rarely, if ever, during childhood. Recent evidence suggests that language models with human-scale pretraining data may possess a similar ability by generalizing from frequent to rare constructions. However, it remains an open question how widespread this generalization ability is, and to what extent this knowledge extends to meanings of rare constructions, as opposed to just their forms. We fill this gap by testing human-scale transformer language models on their knowledge of both the form and meaning of the (rare and quirky) English LET-ALONE construction. To evaluate our LMs we construct a bespoke synthetic benchmark that targets syntactic and semantic properties of the construction. We find that human-scale LMs are sensitive to form, even when related constructions are filtered from the dataset. However, human-scale LMs do not make correct generalizations about LET-ALONE's meaning. These results point to an asymmetry in the current architectures' sample efficiency between language form and meaning, something which is not present in human language learners.
Language Models Grow Less Humanlike beyond Phase Transition
Feb 26, 2025LMs' alignment with human reading behavior (i.e. psychometric predictive power; PPP) is known to improve during pretraining up to a tipping point, beyond which it either plateaus or degrades. Various factors, such as word frequency, recency bias in attention, and context size, have been theorized to affect PPP, yet there is no current account that explains why such a tipping point exists, and how it interacts with LMs' pretraining dynamics more generally. We hypothesize that the underlying factor is a pretraining phase transition, characterized by the rapid emergence of specialized attention heads. We conduct a series of correlational and causal experiments to show that such a phase transition is responsible for the tipping point in PPP. We then show that, rather than producing attention patterns that contribute to the degradation in PPP, phase transitions alter the subsequent learning dynamics of the model, such that further training keeps damaging PPP.
Anything Goes? A Crosslinguistic Study of (Im)possible Language Learning in LMs
Feb 26, 2025



Do LLMs offer insights into human language learning? A common argument against this idea is that because their architecture and training paradigm are so vastly different from humans, LLMs can learn arbitrary inputs as easily as natural languages. In this paper, we test this claim by training LMs to model impossible and typologically unattested languages. Unlike previous work, which has focused exclusively on English, we conduct experiments on 12 natural languages from 4 language families. Our results show that while GPT-2 small can primarily distinguish attested languages from their impossible counterparts, it does not achieve perfect separation between all the attested languages and all the impossible ones. We further test whether GPT-2 small distinguishes typologically attested from unattested languages with different NP orders by manipulating word order based on Greenberg's Universal 20. We find that the model's perplexity scores do not distinguish attested vs. unattested word orders, as long as the unattested variants maintain constituency structure. These findings suggest that language models exhibit some human-like inductive biases, though these biases are weaker than those found in human learners.
Generalized Kernel Inducing Points by Duality Gap for Dataset Distillation
Feb 18, 2025We propose Duality Gap KIP (DGKIP), an extension of the Kernel Inducing Points (KIP) method for dataset distillation. While existing dataset distillation methods often rely on bi-level optimization, DGKIP eliminates the need for such optimization by leveraging duality theory in convex programming. The KIP method has been introduced as a way to avoid bi-level optimization; however, it is limited to the squared loss and does not support other loss functions (e.g., cross-entropy or hinge loss) that are more suitable for classification tasks. DGKIP addresses this limitation by exploiting an upper bound on parameter changes after dataset distillation using the duality gap, enabling its application to a wider range of loss functions. We also characterize theoretical properties of DGKIP by providing upper bounds on the test error and prediction consistency after dataset distillation. Experimental results on standard benchmarks such as MNIST and CIFAR-10 demonstrate that DGKIP retains the efficiency of KIP while offering broader applicability and robust performance.
Distributionally Robust Coreset Selection under Covariate Shift
Jan 24, 2025Coreset selection, which involves selecting a small subset from an existing training dataset, is an approach to reducing training data, and various approaches have been proposed for this method. In practical situations where these methods are employed, it is often the case that the data distributions differ between the development phase and the deployment phase, with the latter being unknown. Thus, it is challenging to select an effective subset of training data that performs well across all deployment scenarios. We therefore propose Distributionally Robust Coreset Selection (DRCS). DRCS theoretically derives an estimate of the upper bound for the worst-case test error, assuming that the future covariate distribution may deviate within a defined range from the training distribution. Furthermore, by selecting instances in a way that suppresses the estimate of the upper bound for the worst-case test error, DRCS achieves distributionally robust training instance selection. This study is primarily applicable to convex training computation, but we demonstrate that it can also be applied to deep learning under appropriate approximations. In this paper, we focus on covariate shift, a type of data distribution shift, and demonstrate the effectiveness of DRCS through experiments.
GDTB: Genre Diverse Data for English Shallow Discourse Parsing across Modalities, Text Types, and Domains
Nov 01, 2024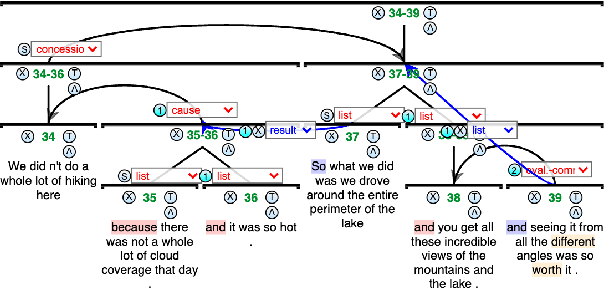
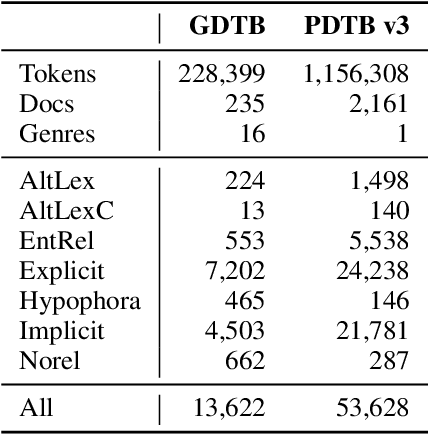
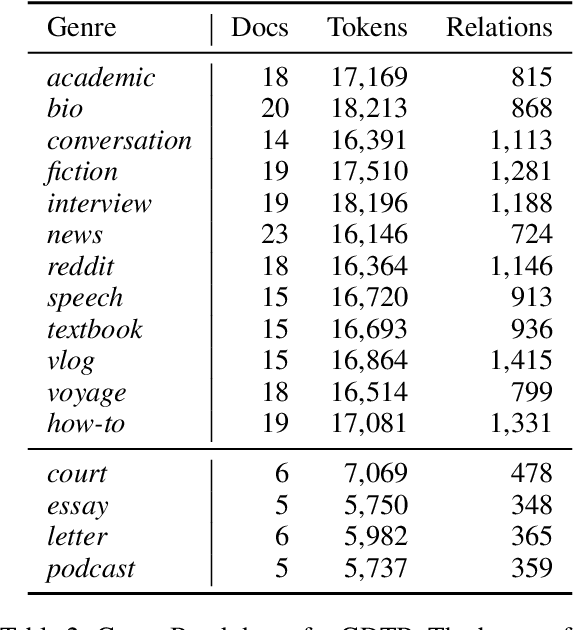
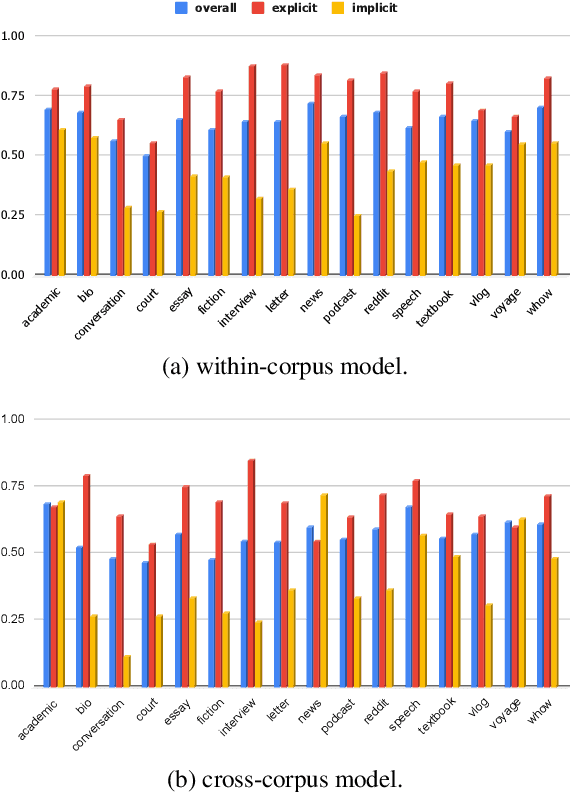
Work on shallow discourse parsing in English has focused on the Wall Street Journal corpus, the only large-scale dataset for the language in the PDTB framework. However, the data is not openly available, is restricted to the news domain, and is by now 35 years old. In this paper, we present and evaluate a new open-access, multi-genre benchmark for PDTB-style shallow discourse parsing, based on the existing UD English GUM corpus, for which discourse relation annotations in other frameworks already exist. In a series of experiments on cross-domain relation classification, we show that while our dataset is compatible with PDTB, substantial out-of-domain degradation is observed, which can be alleviated by joint training on both datasets.
Identifying Fairness Issues in Automatically Generated Testing Content
May 01, 2024
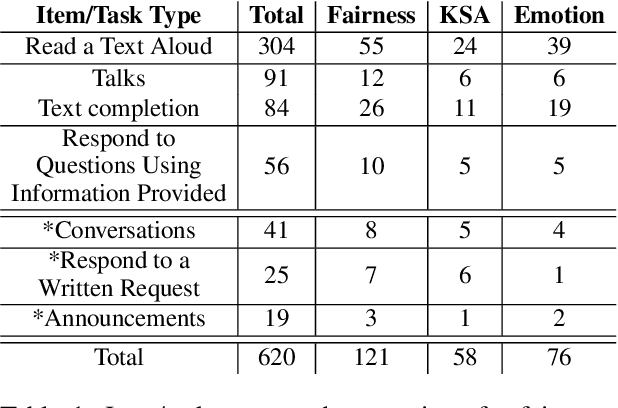
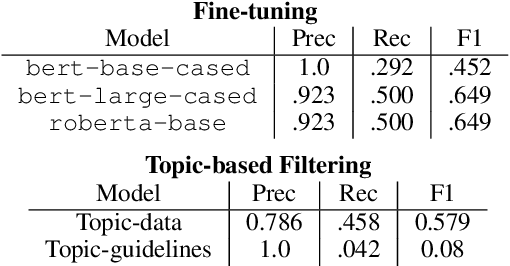
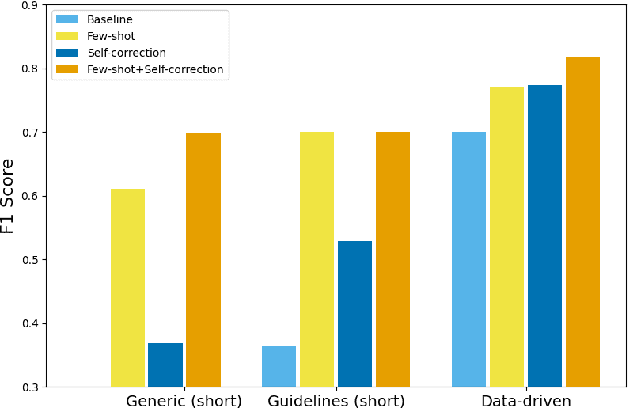
Natural language generation tools are powerful and effective for generating content. However, language models are known to display bias and fairness issues, making them impractical to deploy for many use cases. We here focus on how fairness issues impact automatically generated test content, which can have stringent requirements to ensure the test measures only what it was intended to measure. Specifically, we review test content generated for a large-scale standardized English proficiency test with the goal of identifying content that only pertains to a certain subset of the test population as well as content that has the potential to be upsetting or distracting to some test takers. Issues like these could inadvertently impact a test taker's score and thus should be avoided. This kind of content does not reflect the more commonly-acknowledged biases, making it challenging even for modern models that contain safeguards. We build a dataset of 601 generated texts annotated for fairness and explore a variety of methods for classification: fine-tuning, topic-based classification, and prompting, including few-shot and self-correcting prompts. We find that combining prompt self-correction and few-shot learning performs best, yielding an F1 score of 0.79 on our held-out test set, while much smaller BERT- and topic-based models have competitive performance on out-of-domain data.
Distributionally Robust Safe Screening
Apr 25, 2024In this study, we propose a method Distributionally Robust Safe Screening (DRSS), for identifying unnecessary samples and features within a DR covariate shift setting. This method effectively combines DR learning, a paradigm aimed at enhancing model robustness against variations in data distribution, with safe screening (SS), a sparse optimization technique designed to identify irrelevant samples and features prior to model training. The core concept of the DRSS method involves reformulating the DR covariate-shift problem as a weighted empirical risk minimization problem, where the weights are subject to uncertainty within a predetermined range. By extending the SS technique to accommodate this weight uncertainty, the DRSS method is capable of reliably identifying unnecessary samples and features under any future distribution within a specified range. We provide a theoretical guarantee of the DRSS method and validate its performance through numerical experiments on both synthetic and real-world datasets.
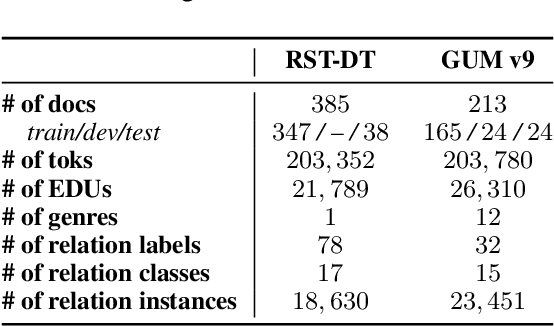
eRST: A Signaled Graph Theory of Discourse Relations and Organization
Mar 20, 2024In this article we present Enhanced Rhetorical Structure Theory (eRST), a new theoretical framework for computational discourse analysis, based on an expansion of Rhetorical Structure Theory (RST). The framework encompasses discourse relation graphs with tree-breaking, nonprojective and concurrent relations, as well as implicit and explicit signals which give explainable rationales to our analyses. We survey shortcomings of RST and other existing frameworks, such as Segmented Discourse Representation Theory (SDRT), the Penn Discourse Treebank (PDTB) and Discourse Dependencies, and address these using constructs in the proposed theory. We provide annotation, search and visualization tools for data, and present and evaluate a freely available corpus of English annotated according to our framework, encompassing 12 spoken and written genres with over 200K tokens. Finally, we discuss automatic parsing, evaluation metrics and applications for data in our framework.
What's Hard in English RST Parsing? Predictive Models for Error Analysis
Sep 10, 2023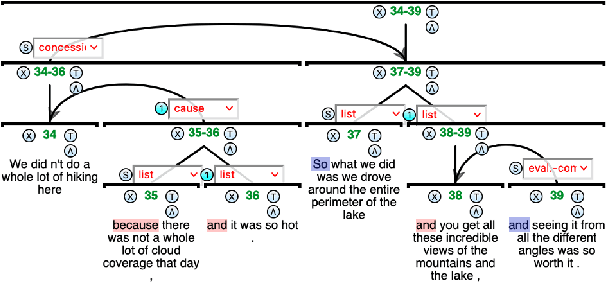
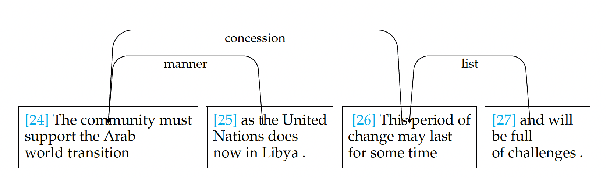
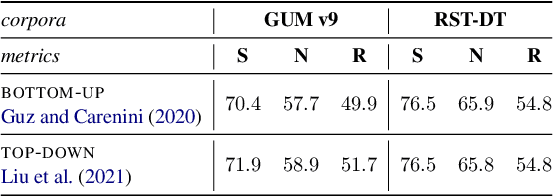
Despite recent advances in Natural Language Processing (NLP), hierarchical discourse parsing in the framework of Rhetorical Structure Theory remains challenging, and our understanding of the reasons for this are as yet limited. In this paper, we examine and model some of the factors associated with parsing difficulties in previous work: the existence of implicit discourse relations, challenges in identifying long-distance relations, out-of-vocabulary items, and more. In order to assess the relative importance of these variables, we also release two annotated English test-sets with explicit correct and distracting discourse markers associated with gold standard RST relations. Our results show that as in shallow discourse parsing, the explicit/implicit distinction plays a role, but that long-distance dependencies are the main challenge, while lack of lexical overlap is less of a problem, at least for in-domain parsing. Our final model is able to predict where errors will occur with an accuracy of 76.3% for the bottom-up parser and 76.6% for the top-down parser.