 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaking of Language: Reflections on Metalanguage Research in NLP
Apr 03, 2026This work aims to shine a spotlight on the topic of metalanguage. We first define metalanguage, link it to NLP and LLMs, and then discuss our two labs' metalanguage-centered efforts. Finally, we discuss four dimensions of metalanguage and metalinguistic tasks, offering a list of understudied future research directions.
A Curious Class of Adpositional Multiword Expressions in Korean
Feb 17, 2026Multiword expressions (MWEs) have been widely studied in cross-lingual annotation frameworks such as PARSEME. However, Korean MWEs remain underrepresented in these efforts. In particular, Korean multiword adpositions lack systematic analysis, annotated resources, and integration into existing multilingual frameworks. In this paper, we study a class of Korean functional multiword expressions: postpositional verb-based constructions (PVCs). Using data from Korean Wikipedia, we survey and analyze several PVC expressions and contrast them with non-MWEs and light verb constructions (LVCs) with similar structure. Building on this analysis, we propose annotation guidelines designed to support future work in Korean multiword adpositions and facilitate alignment with cross-lingual frameworks.
A Unified Assessment of the Poverty of the Stimulus Argument for Neural Language Models
Feb 10, 2026How can children acquire native-level syntax from limited input? According to the Poverty of the Stimulus Hypothesis (PoSH), the linguistic input children receive is insufficient to explain certain generalizations that are robustly learned; innate linguistic constraints, many have argued, are thus necessary to explain language learning. Neural language models, which lack such language-specific constraints in their design, offer a computational test of this longstanding (but controversial) claim. We introduce \poshbench, a training-and-evaluation suite targeting question formation, islands to movement, and other English phenomena at the center of the PoSH arguments. Training Transformer models on 10--50M words of developmentally plausible text, we find indications of generalization on all phenomena even without direct positive evidence -- yet neural models remain less data-efficient and their generalizations are weaker than those of children. We further enhance our models with three recently proposed cognitively motivated inductive biases. We find these biases improve general syntactic competence but not \poshbench performance. Our findings challenge the claim that innate syntax is the only possible route to generalization, while suggesting that human-like data efficiency requires inductive biases beyond those tested here.
Unpacking Let Alone: Human-Scale Models Generalize to a Rare Construction in Form but not Meaning
Jun 04, 2025


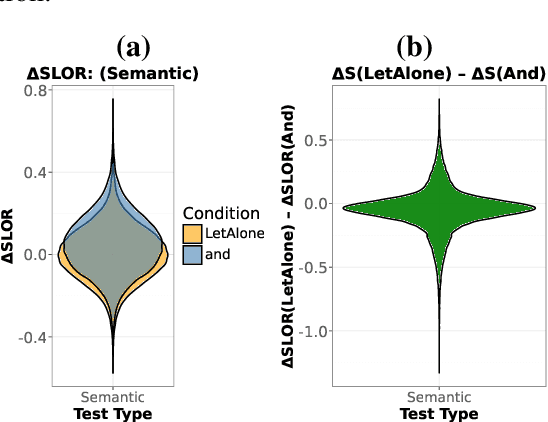
Humans have a remarkable ability to acquire and understand grammatical phenomena that are seen rarely, if ever, during childhood. Recent evidence suggests that language models with human-scale pretraining data may possess a similar ability by generalizing from frequent to rare constructions. However, it remains an open question how widespread this generalization ability is, and to what extent this knowledge extends to meanings of rare constructions, as opposed to just their forms. We fill this gap by testing human-scale transformer language models on their knowledge of both the form and meaning of the (rare and quirky) English LET-ALONE construction. To evaluate our LMs we construct a bespoke synthetic benchmark that targets syntactic and semantic properties of the construction. We find that human-scale LMs are sensitive to form, even when related constructions are filtered from the dataset. However, human-scale LMs do not make correct generalizations about LET-ALONE's meaning. These results point to an asymmetry in the current architectures' sample efficiency between language form and meaning, something which is not present in human language learners.
UD-English-CHILDES: A Collected Resource of Gold and Silver Universal Dependencies Trees for Child Language Interactions
Apr 28, 2025CHILDES is a widely used resource of transcribed child and child-directed speech. This paper introduces UD-English-CHILDES, the first officially released Universal Dependencies (UD) treebank derived from previously dependency-annotated CHILDES data with consistent and unified annotation guidelines. Our corpus harmonizes annotations from 11 children and their caregivers, totaling over 48k sentences. We validate existing gold-standard annotations under the UD v2 framework and provide an additional 1M silver-standard sentences, offering a consistent resource for computational and linguistic research.
Construction Identification and Disambiguation Using BERT: A Case Study of NPN
Mar 24, 2025
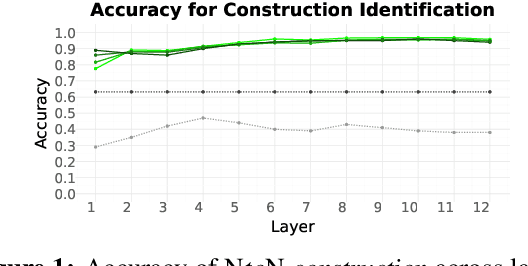
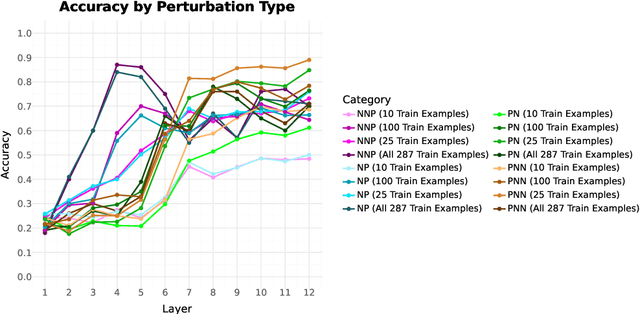
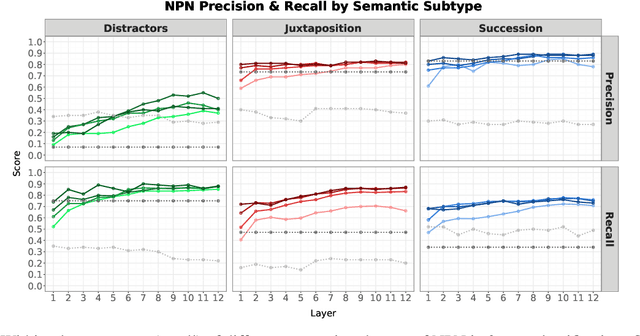
Construction Grammar hypothesizes that knowledge of a language consists chiefly of knowledge of form-meaning pairs (''constructions'') that include vocabulary, general grammar rules, and even idiosyncratic patterns. Recent work has shown that transformer language models represent at least some constructional patterns, including ones where the construction is rare overall. In this work, we probe BERT's representation of the form and meaning of a minor construction of English, the NPN (noun-preposition-noun) construction -- exhibited in such expressions as face to face and day to day -- which is known to be polysemous. We construct a benchmark dataset of semantically annotated corpus instances (including distractors that superficially resemble the construction). With this dataset, we train and evaluate probing classifiers. They achieve decent discrimination of the construction from distractors, as well as sense disambiguation among true instances of the construction, revealing that BERT embeddings carry indications of the construction's semantics. Moreover, artificially permuting the word order of true construction instances causes them to be rejected, indicating sensitivity to matters of form. We conclude that BERT does latently encode at least some knowledge of the NPN construction going beyond a surface syntactic pattern and lexical cues.
Natural Language Processing RELIES on Linguistics
May 09, 2024Large Language Models (LLMs) have become capable of generating highly fluent text in certain languages, without modules specially designed to capture grammar or semantic coherence. What does this mean for the future of linguistic expertise in NLP? We highlight several aspects in which NLP (still) relies on linguistics, or where linguistic thinking can illuminate new directions. We argue our case around the acronym $RELIES$ that encapsulates six major facets where linguistics contributes to NLP: $R$esources, $E$valuation, $L$ow-resource settings, $I$nterpretability, $E$xplanation, and the $S$tudy of language. This list is not exhaustive, nor is linguistics the main point of reference for every effort under these themes; but at a macro level, these facets highlight the enduring importance of studying machine systems vis-a-vis systems of human language.
UCxn: Typologically Informed Annotation of Constructions Atop Universal Dependencies
Mar 26, 2024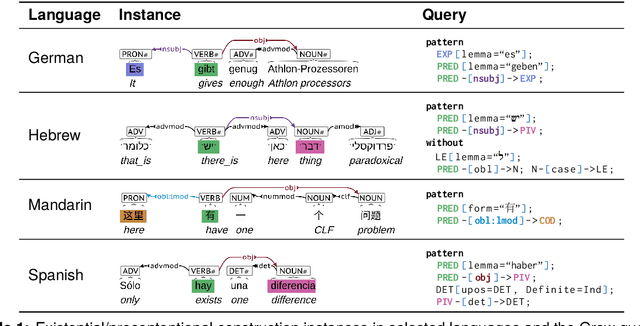
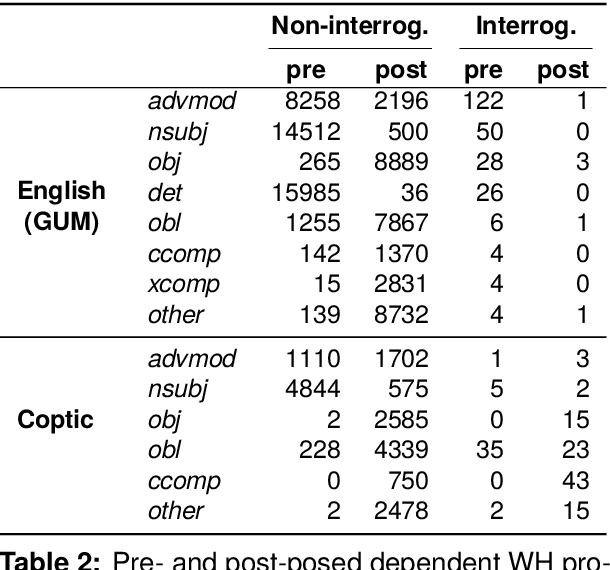
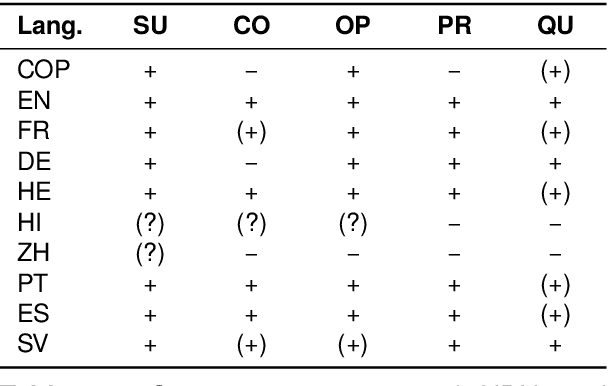
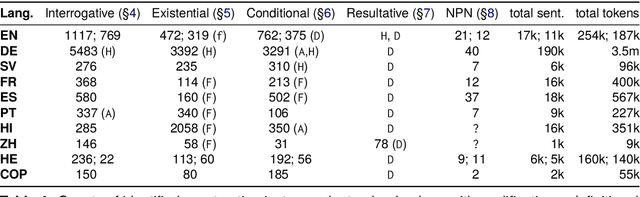
The Universal Dependencies (UD) project has created an invaluable collection of treebanks with contributions in over 140 languages. However, the UD annotations do not tell the full story. Grammatical constructions that convey meaning through a particular combination of several morphosyntactic elements -- for example, interrogative sentences with special markers and/or word orders -- are not labeled holistically. We argue for (i) augmenting UD annotations with a 'UCxn' annotation layer for such meaning-bearing grammatical constructions, and (ii) approaching this in a typologically informed way so that morphosyntactic strategies can be compared across languages. As a case study, we consider five construction families in ten languages, identifying instances of each construction in UD treebanks through the use of morphosyntactic patterns. In addition to findings regarding these particular constructions, our study yields important insights on methodology for describing and identifying constructions in language-general and language-particular ways, and lays the foundation for future constructional enrichment of UD treebanks.
Syntactic Inductive Bias in Transformer Language Models: Especially Helpful for Low-Resource Languages?
Nov 01, 2023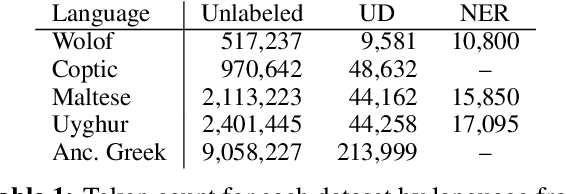
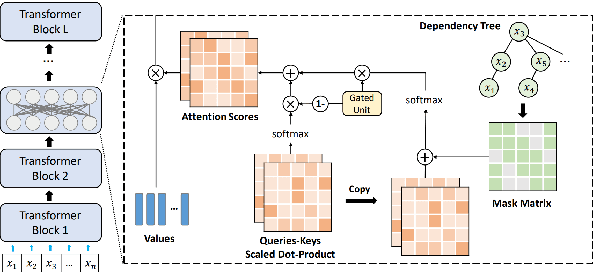
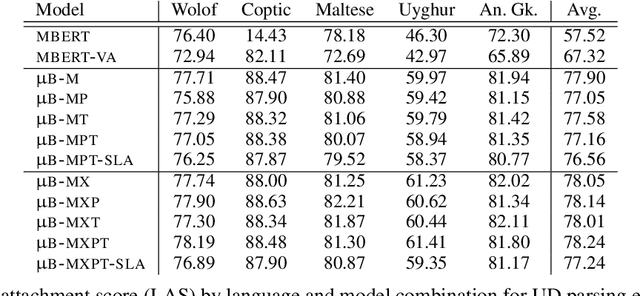
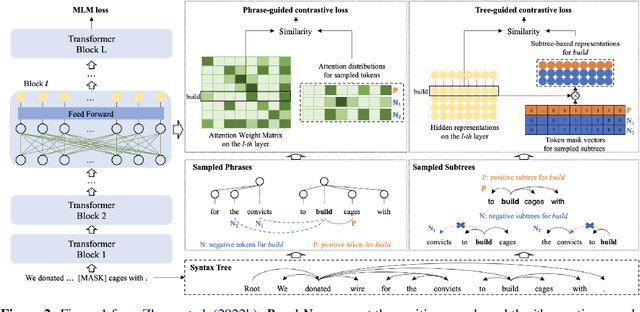
A line of work on Transformer-based language models such as BERT has attempted to use syntactic inductive bias to enhance the pretraining process, on the theory that building syntactic structure into the training process should reduce the amount of data needed for training. But such methods are often tested for high-resource languages such as English. In this work, we investigate whether these methods can compensate for data sparseness in low-resource languages, hypothesizing that they ought to be more effective for low-resource languages. We experiment with five low-resource languages: Uyghur, Wolof, Maltese, Coptic, and Ancient Greek. We find that these syntactic inductive bias methods produce uneven results in low-resource settings, and provide surprisingly little benefit in most cases.
AMR4NLI: Interpretable and robust NLI measures from semantic graphs
Jun 01, 2023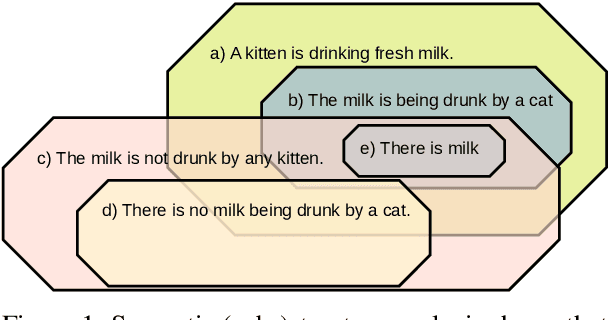
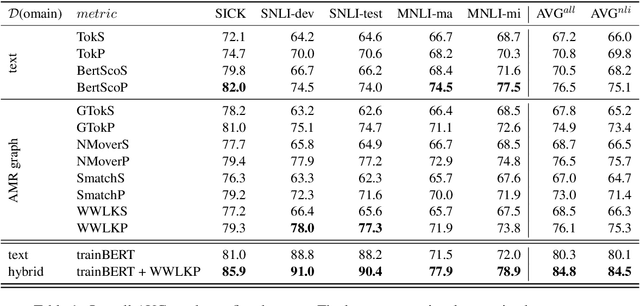
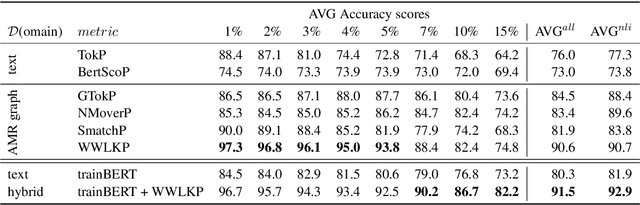
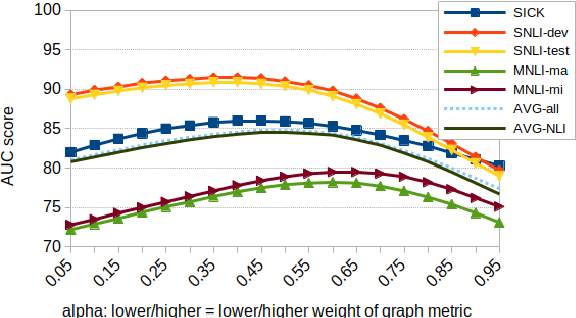
The task of natural language inference (NLI) asks whether a given premise (expressed in NL) entails a given NL hypothesis. NLI benchmarks contain human ratings of entailment, but the meaning relationships driving these ratings are not formalized. Can the underlying sentence pair relationships be made more explicit in an interpretable yet robust fashion? We compare semantic structures to represent premise and hypothesis, including sets of contextualized embeddings and semantic graphs (Abstract Meaning Representations), and measure whether the hypothesis is a semantic substructure of the premise, utilizing interpretable metrics. Our evaluation on three English benchmarks finds value in both contextualized embeddings and semantic graphs; moreover, they provide complementary signals, and can be leveraged together in a hybrid model.