 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCuRIAM: Corpus re Interpretation and Metalanguage in U.S. Supreme Court Opinions
May 24, 2023
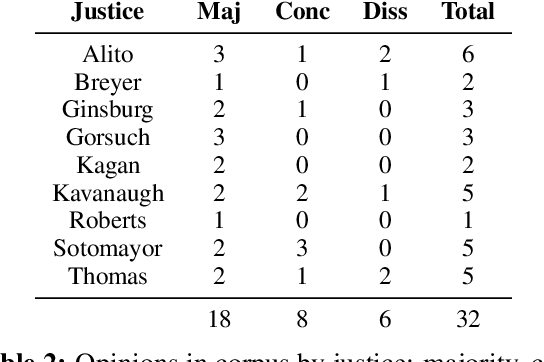
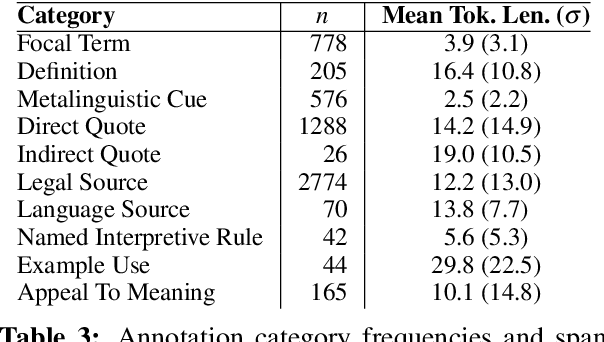
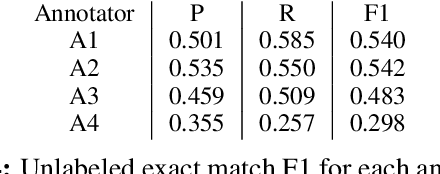
Most judicial decisions involve the interpretation of legal texts; as such, judicial opinion requires the use of language as a medium to comment on or draw attention to other language. Language used this way is called metalanguage. We develop an annotation schema for categorizing types of legal metalanguage and apply our schema to a set of U.S. Supreme Court opinions, yielding a corpus totaling 59k tokens. We remark on several patterns observed in the kinds of metalanguage used by the justices.
PASTRIE: A Corpus of Prepositions Annotated with Supersense Tags in Reddit International English
Oct 23, 2021
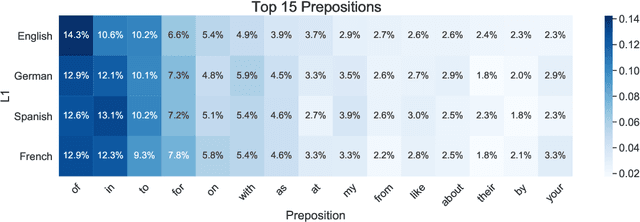


We present the Prepositions Annotated with Supersense Tags in Reddit International English ("PASTRIE") corpus, a new dataset containing manually annotated preposition supersenses of English data from presumed speakers of four L1s: English, French, German, and Spanish. The annotations are comprehensive, covering all preposition types and tokens in the sample. Along with the corpus, we provide analysis of distributional patterns across the included L1s and a discussion of the influence of L1s on L2 preposition choice.
Making Heads and Tails of Models with Marginal Calibration for Sparse Tagsets
Sep 15, 2021
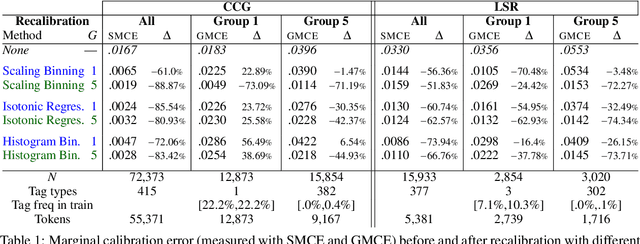
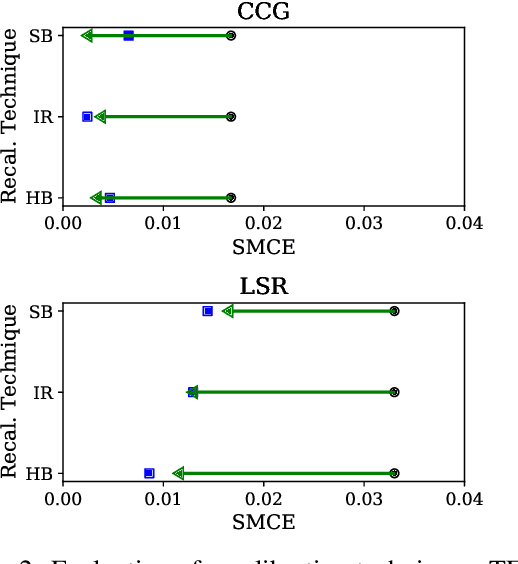
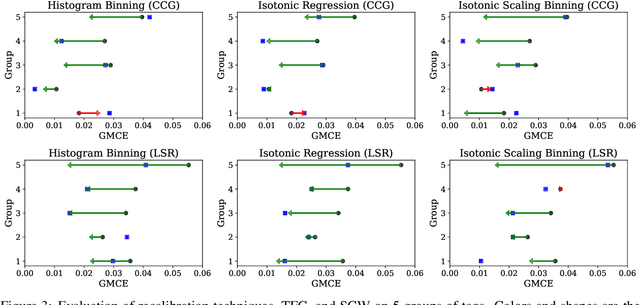
For interpreting the behavior of a probabilistic model, it is useful to measure a model's calibration--the extent to which it produces reliable confidence scores. We address the open problem of calibration for tagging models with sparse tagsets, and recommend strategies to measure and reduce calibration error (CE) in such models. We show that several post-hoc recalibration techniques all reduce calibration error across the marginal distribution for two existing sequence taggers. Moreover, we propose tag frequency grouping (TFG) as a way to measure calibration error in different frequency bands. Further, recalibrating each group separately promotes a more equitable reduction of calibration error across the tag frequency spectrum.
Team DoNotDistribute at SemEval-2020 Task 11: Features, Finetuning, and Data Augmentation in Neural Models for Propaganda Detection in News Articles
Aug 21, 2020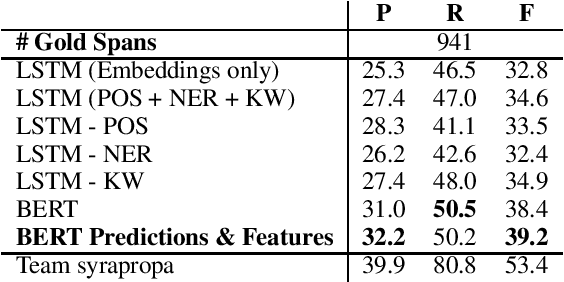
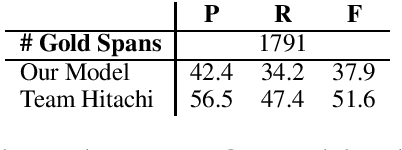
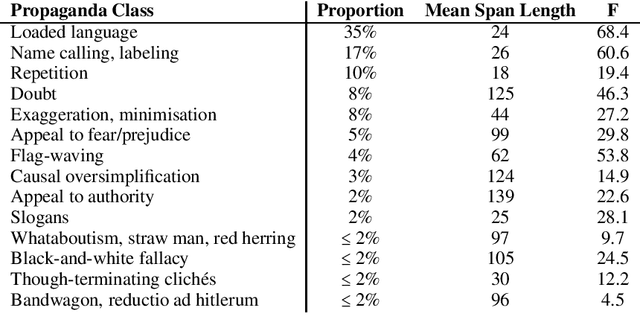

This paper presents our systems for SemEval 2020 Shared Task 11: Detection of Propaganda Techniques in News Articles. We participate in both the span identification and technique classification subtasks and report on experiments using different BERT-based models along with handcrafted features. Our models perform well above the baselines for both tasks, and we contribute ablation studies and discussion of our results to dissect the effectiveness of different features and techniques with the goal of aiding future studies in propaganda detection.
Lexical Semantic Recognition
Apr 30, 2020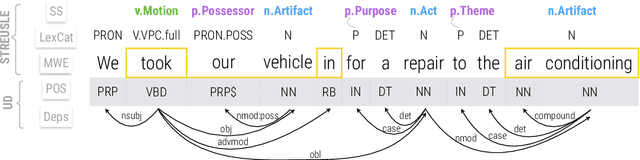
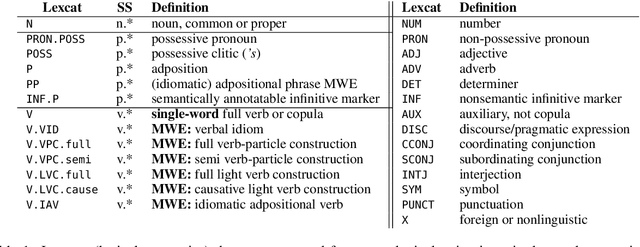
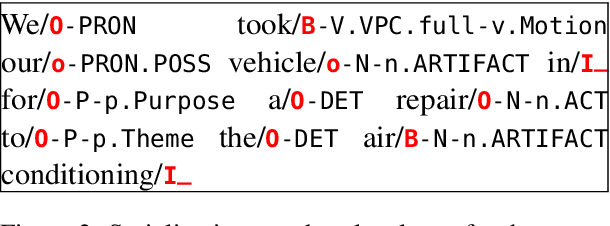
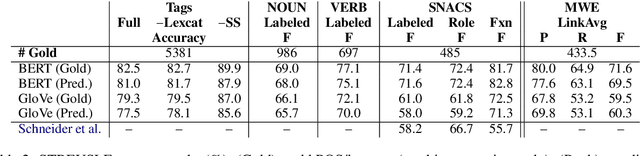
Segmentation and (segment) labeling are generally treated separately in lexical semantics, raising issues due to their close inter-dependence and necessitating joint annotation. We therefore investigate the lexical semantic recognition task of multiword expression segmentation and supersense disambiguation, unifying several previously-disparate styles of lexical semantic annotation. We evaluate a neural CRF model along all annotation axes available in version 4.3 of the STREUSLE corpus: lexical unit segmentation (multiword expressions), word-level syntactic tags, and supersense classes for noun, verb, and preposition/possessive units. As the label set generalizes that of previous tasks (DiMSUM, PARSEME), we additionally evaluate how well the model generalizes to those test sets, with encouraging results. By establishing baseline models and evaluation metrics, we pave the way for comprehensive and accurate modeling of lexical semantics.