 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models
Aug 20, 2023
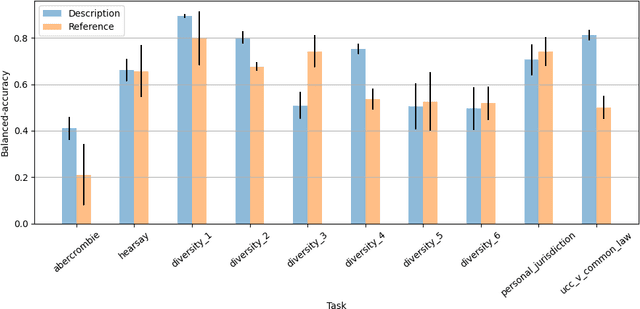
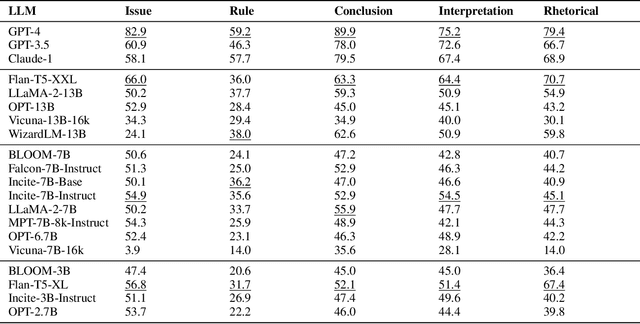
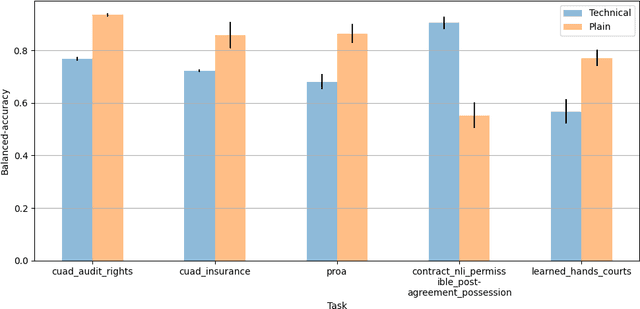
The advent of large language models (LLMs) and their adoption by the legal community has given rise to the question: what types of legal reasoning can LLMs perform? To enable greater study of this question, we present LegalBench: a collaboratively constructed legal reasoning benchmark consisting of 162 tasks covering six different types of legal reasoning. LegalBench was built through an interdisciplinary process, in which we collected tasks designed and hand-crafted by legal professionals. Because these subject matter experts took a leading role in construction, tasks either measure legal reasoning capabilities that are practically useful, or measure reasoning skills that lawyers find interesting. To enable cross-disciplinary conversations about LLMs in the law, we additionally show how popular legal frameworks for describing legal reasoning -- which distinguish between its many forms -- correspond to LegalBench tasks, thus giving lawyers and LLM developers a common vocabulary. This paper describes LegalBench, presents an empirical evaluation of 20 open-source and commercial LLMs, and illustrates the types of research explorations LegalBench enables.
CuRIAM: Corpus re Interpretation and Metalanguage in U.S. Supreme Court Opinions
May 24, 2023
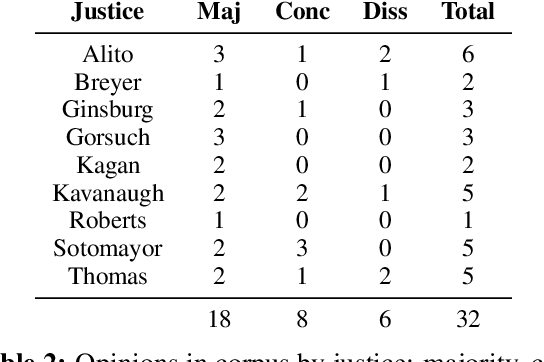
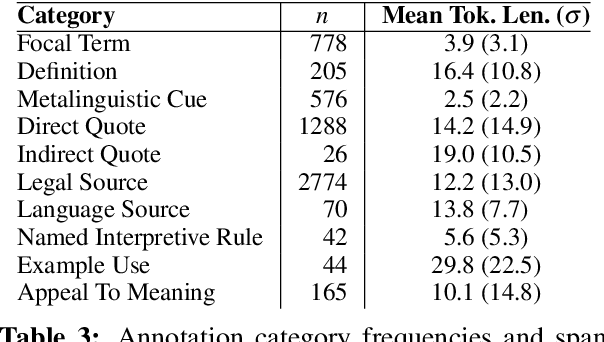
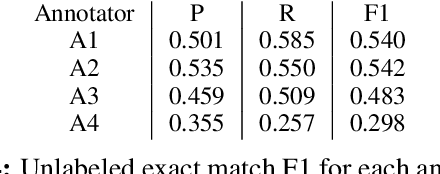
Most judicial decisions involve the interpretation of legal texts; as such, judicial opinion requires the use of language as a medium to comment on or draw attention to other language. Language used this way is called metalanguage. We develop an annotation schema for categorizing types of legal metalanguage and apply our schema to a set of U.S. Supreme Court opinions, yielding a corpus totaling 59k tokens. We remark on several patterns observed in the kinds of metalanguage used by the justices.