 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models
Aug 20, 2023
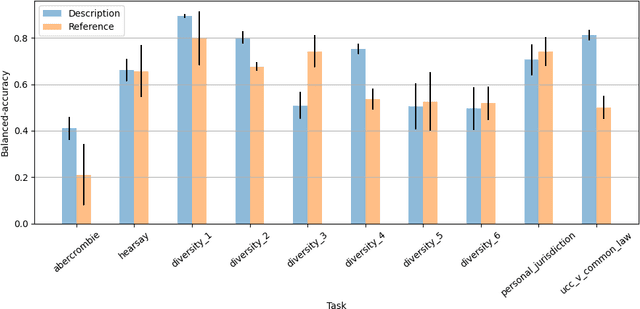
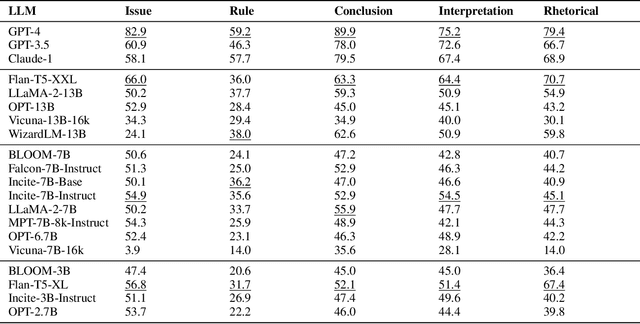
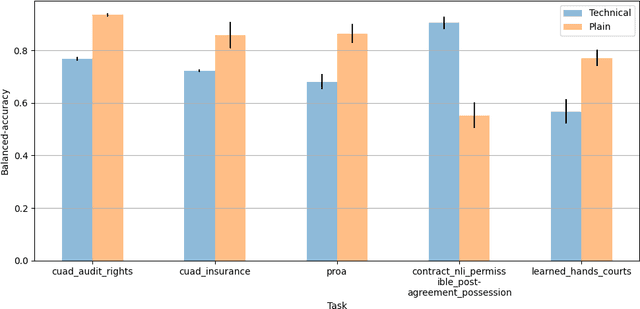
The advent of large language models (LLMs) and their adoption by the legal community has given rise to the question: what types of legal reasoning can LLMs perform? To enable greater study of this question, we present LegalBench: a collaboratively constructed legal reasoning benchmark consisting of 162 tasks covering six different types of legal reasoning. LegalBench was built through an interdisciplinary process, in which we collected tasks designed and hand-crafted by legal professionals. Because these subject matter experts took a leading role in construction, tasks either measure legal reasoning capabilities that are practically useful, or measure reasoning skills that lawyers find interesting. To enable cross-disciplinary conversations about LLMs in the law, we additionally show how popular legal frameworks for describing legal reasoning -- which distinguish between its many forms -- correspond to LegalBench tasks, thus giving lawyers and LLM developers a common vocabulary. This paper describes LegalBench, presents an empirical evaluation of 20 open-source and commercial LLMs, and illustrates the types of research explorations LegalBench enables.
The Cultural Evolution of National Constitutions
Nov 18, 2017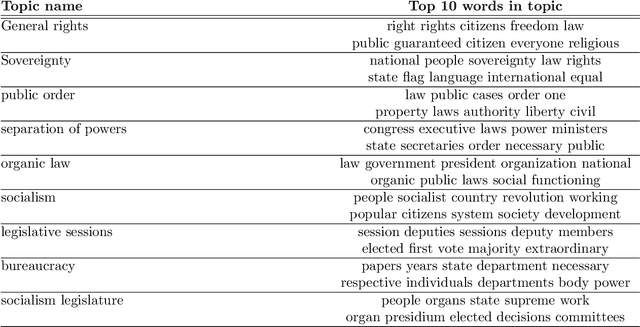
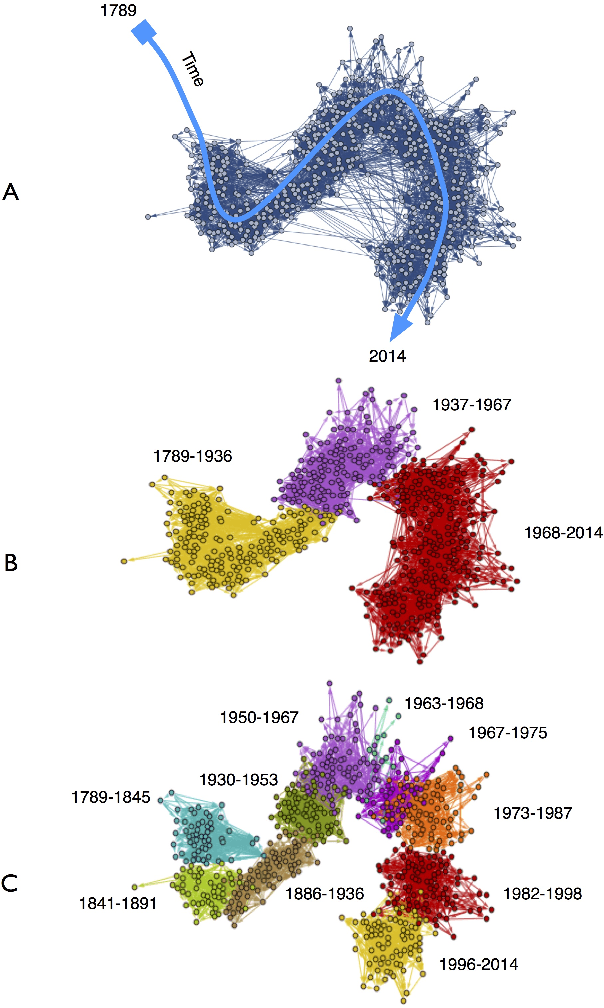
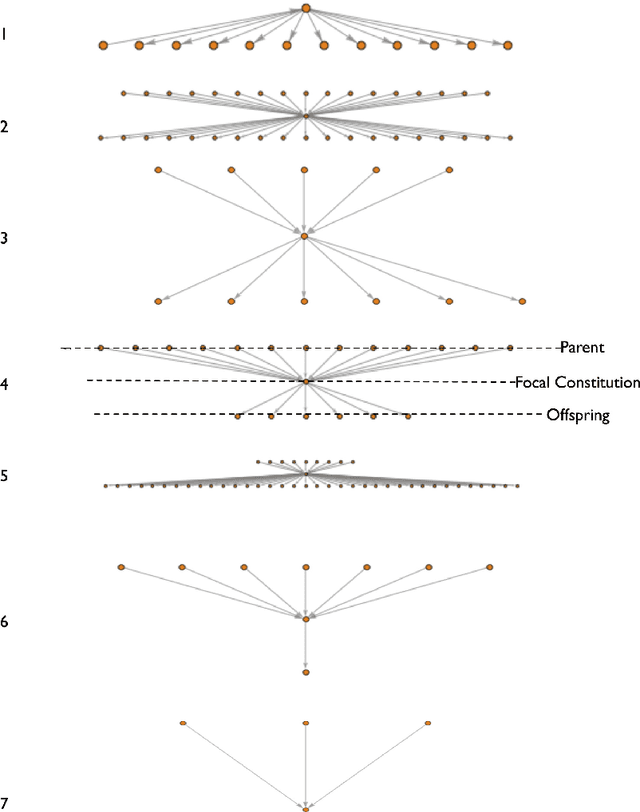
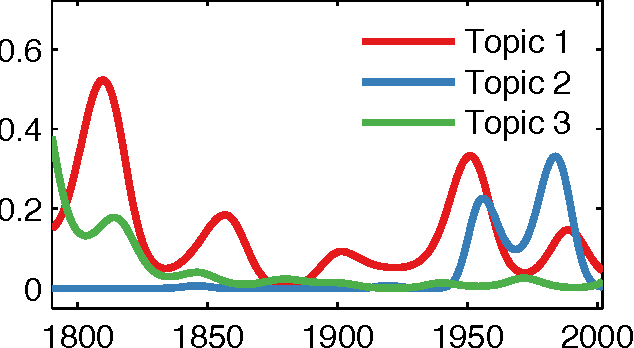
We explore how ideas from infectious disease and genetics can be used to uncover patterns of cultural inheritance and innovation in a corpus of 591 national constitutions spanning 1789 - 2008. Legal "Ideas" are encoded as "topics" - words statistically linked in documents - derived from topic modeling the corpus of constitutions. Using these topics we derive a diffusion network for borrowing from ancestral constitutions back to the US Constitution of 1789 and reveal that constitutions are complex cultural recombinants. We find systematic variation in patterns of borrowing from ancestral texts and "biological"-like behavior in patterns of inheritance with the distribution of "offspring" arising through a bounded preferential-attachment process. This process leads to a small number of highly innovative (influential) constitutions some of which have yet to have been identified as so in the current literature. Our findings thus shed new light on the critical nodes of the constitution-making network. The constitutional network structure reflects periods of intense constitution creation, and systematic patterns of variation in constitutional life-span and temporal influence.
Multi-Task Metric Learning on Network Data
Nov 10, 2014
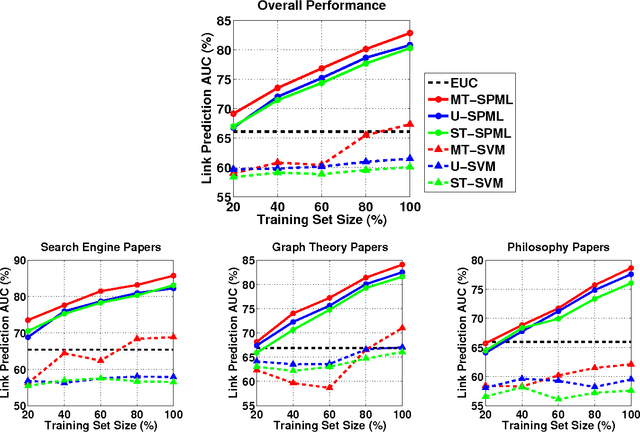
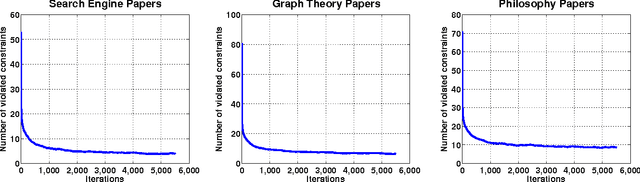
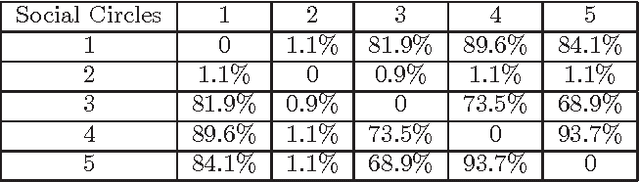
Multi-task learning (MTL) improves prediction performance in different contexts by learning models jointly on multiple different, but related tasks. Network data, which are a priori data with a rich relational structure, provide an important context for applying MTL. In particular, the explicit relational structure implies that network data is not i.i.d. data. Network data also often comes with significant metadata (i.e., attributes) associated with each entity (node). Moreover, due to the diversity and variation in network data (e.g., multi-relational links or multi-category entities), various tasks can be performed and often a rich correlation exists between them. Learning algorithms should exploit all of these additional sources of information for better performance. In this work we take a metric-learning point of view for the MTL problem in the network context. Our approach builds on structure preserving metric learning (SPML). In particular SPML learns a Mahalanobis distance metric for node attributes using network structure as supervision, so that the learned distance function encodes the structure and can be used to predict link patterns from attributes. SPML is described for single-task learning on single network. Herein, we propose a multi-task version of SPML, abbreviated as MT-SPML, which is able to learn across multiple related tasks on multiple networks via shared intermediate parametrization. MT-SPML learns a specific metric for each task and a common metric for all tasks. The task correlation is carried through the common metric and the individual metrics encode task specific information. When combined together, they are structure-preserving with respect to individual tasks. MT-SPML works on general networks, thus is suitable for a wide variety of problems. In experiments, we challenge MT-SPML on two real-word problems, where MT-SPML achieves significant improvement.
A unifying representation for a class of dependent random measures
Nov 20, 2012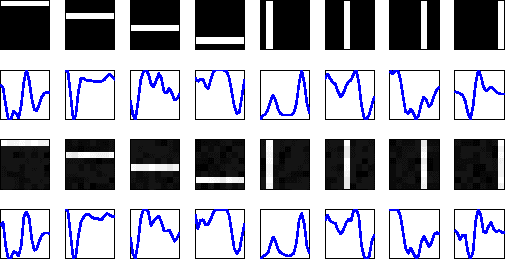

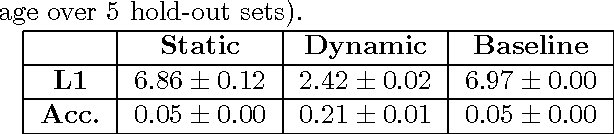
We present a general construction for dependent random measures based on thinning Poisson processes on an augmented space. The framework is not restricted to dependent versions of a specific nonparametric model, but can be applied to all models that can be represented using completely random measures. Several existing dependent random measures can be seen as specific cases of this framework. Interesting properties of the resulting measures are derived and the efficacy of the framework is demonstrated by constructing a covariate-dependent latent feature model and topic model that obtain superior predictive performance.
Partition Decomposition for Roll Call Data
Aug 13, 2011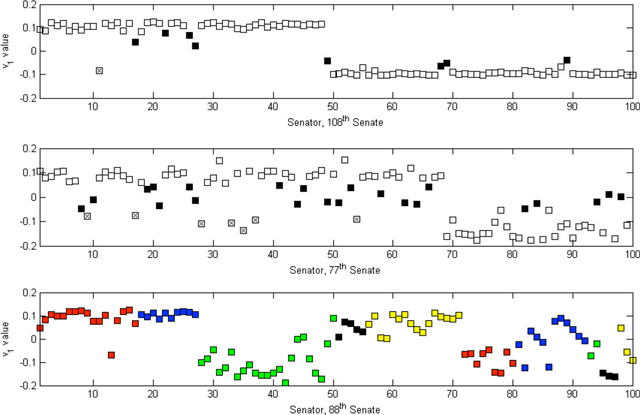
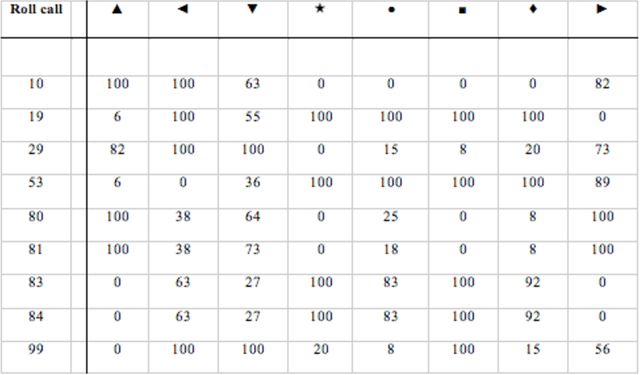

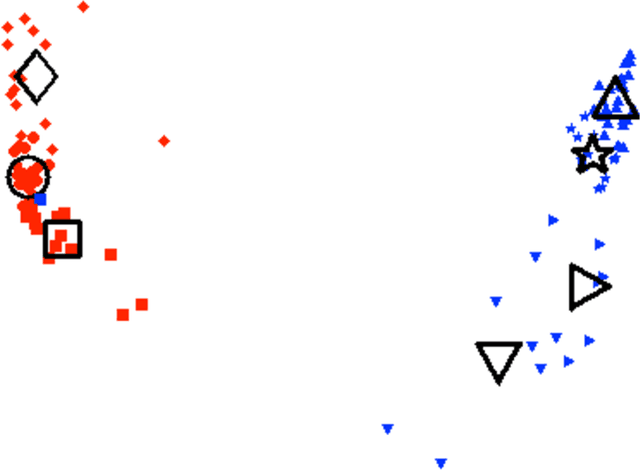
In this paper we bring to bear some new tools from statistical learning on the analysis of roll call data. We present a new data-driven model for roll call voting that is geometric in nature. We construct the model by adapting the "Partition Decoupling Method," an unsupervised learning technique originally developed for the analysis of families of time series, to produce a multiscale geometric description of a weighted network associated to a set of roll call votes. Central to this approach is the quantitative notion of a "motivation," a cluster-based and learned basis element that serves as a building block in the representation of roll call data. Motivations enable the formulation of a quantitative description of ideology and their data-dependent nature makes possible a quantitative analysis of the evolution of ideological factors. This approach is generally applicable to roll call data and we apply it in particular to the historical roll call voting of the U.S. House and Senate. This methodology provides a mechanism for estimating the dimension of the underlying action space. We determine that the dominant factors form a low- (one- or two-) dimensional representation with secondary factors adding higher-dimensional features. In this way our work supports and extends the findings of both Poole-Rosenthal and Heckman-Snyder concerning the dimensionality of the action space. We give a detailed analysis of several individual Senates and use the AdaBoost technique from statistical learning to determine those votes with the most powerful discriminatory value. When used as a predictive model, this geometric view significantly outperforms spatial models such as the Poole-Rosenthal DW-NOMINATE model and the Heckman-Snyder 6-factor model, both in raw accuracy as well as Aggregate Proportional Reduced Error (APRE).