 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreiman's two cultures: You don't have to choose sides
Apr 25, 2021Breiman's classic paper casts data analysis as a choice between two cultures: data modelers and algorithmic modelers. Stated broadly, data modelers use simple, interpretable models with well-understood theoretical properties to analyze data. Algorithmic modelers prioritize predictive accuracy and use more flexible function approximations to analyze data. This dichotomy overlooks a third set of models $-$ mechanistic models derived from scientific theories (e.g., ODE/SDE simulators). Mechanistic models encode application-specific scientific knowledge about the data. And while these categories represent extreme points in model space, modern computational and algorithmic tools enable us to interpolate between these points, producing flexible, interpretable, and scientifically-informed hybrids that can enjoy accurate and robust predictions, and resolve issues with data analysis that Breiman describes, such as the Rashomon effect and Occam's dilemma. Challenges still remain in finding an appropriate point in model space, with many choices on how to compose model components and the degree to which each component informs inferences.
Learning Insulin-Glucose Dynamics in the Wild
Aug 06, 2020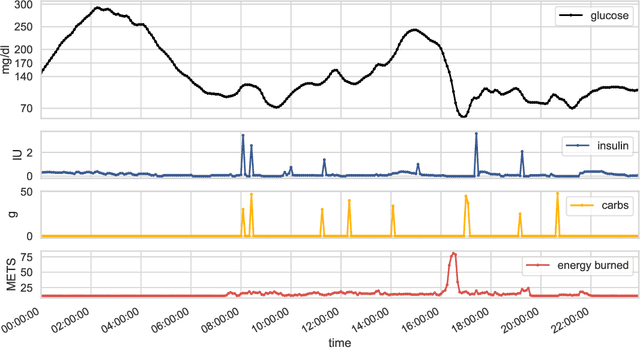

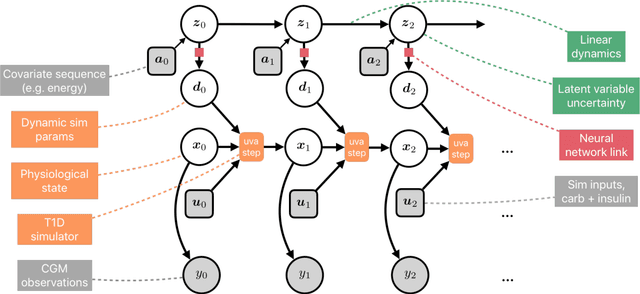
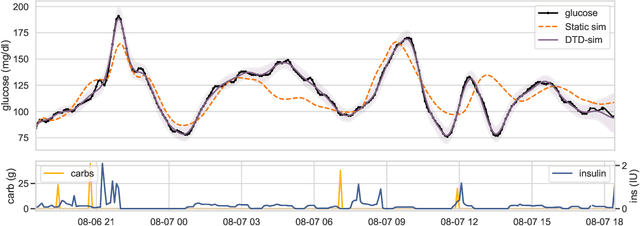
We develop a new model of insulin-glucose dynamics for forecasting blood glucose in type 1 diabetics. We augment an existing biomedical model by introducing time-varying dynamics driven by a machine learning sequence model. Our model maintains a physiologically plausible inductive bias and clinically interpretable parameters -- e.g., insulin sensitivity -- while inheriting the flexibility of modern pattern recognition algorithms. Critical to modeling success are the flexible, but structured representations of subject variability with a sequence model. In contrast, less constrained models like the LSTM fail to provide reliable or physiologically plausible forecasts. We conduct an extensive empirical study. We show that allowing biomedical model dynamics to vary in time improves forecasting at long time horizons, up to six hours, and produces forecasts consistent with the physiological effects of insulin and carbohydrates.
Adaptively Truncating Backpropagation Through Time to Control Gradient Bias
May 17, 2019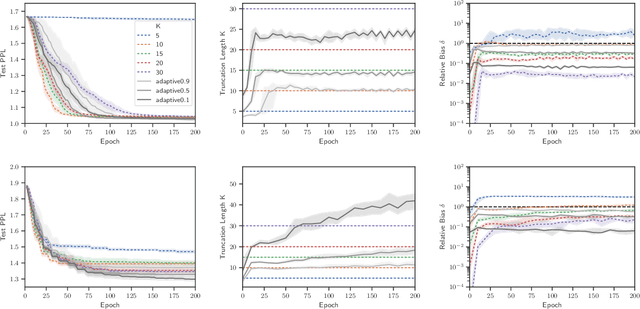
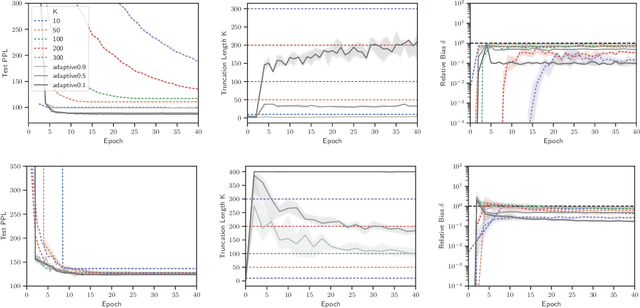
Truncated backpropagation through time (TBPTT) is a popular method for learning in recurrent neural networks (RNNs) that saves computation and memory at the cost of bias by truncating backpropagation after a fixed number of lags. In practice, choosing the optimal truncation length is difficult: TBPTT will not converge if the truncation length is too small, or will converge slowly if it is too large. We propose an adaptive TBPTT scheme that converts the problem from choosing a temporal lag to one of choosing a tolerable amount of gradient bias. For many realistic RNNs, the TBPTT gradients decay geometrically for large lags; under this condition, we can control the bias by varying the truncation length adaptively. For RNNs with smooth activation functions, we prove that this bias controls the convergence rate of SGD with biased gradients for our non-convex loss. Using this theory, we develop a practical method for adaptively estimating the truncation length during training. We evaluate our adaptive TBPTT method on synthetic data and language modeling tasks and find that our adaptive TBPTT ameliorates the computational pitfalls of fixed TBPTT.
Stochastic Gradient MCMC for State Space Models
Oct 22, 2018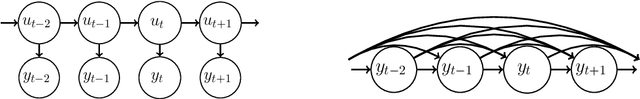
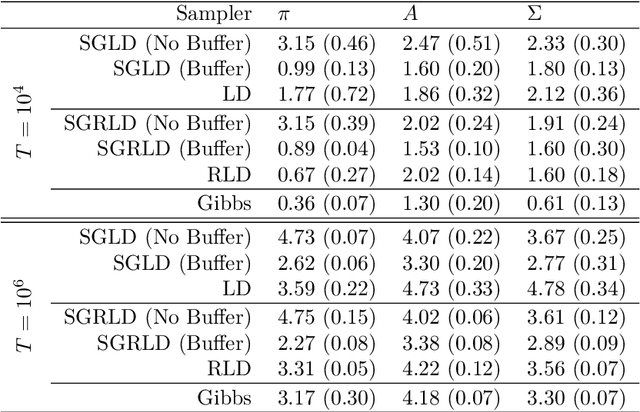

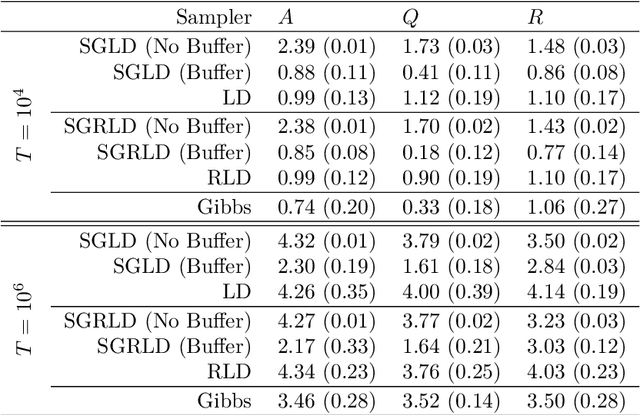
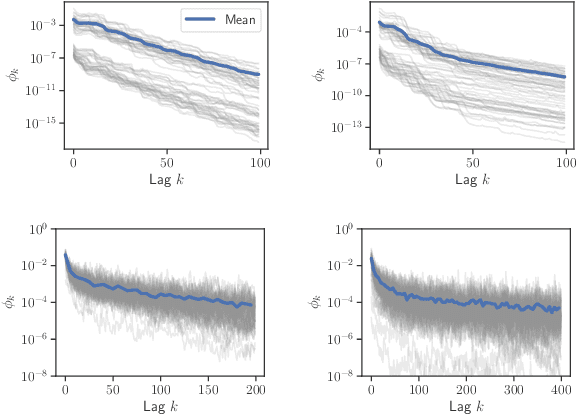
State space models (SSMs) are a flexible approach to modeling complex time series. However, inference in SSMs is often computationally prohibitive for long time series. Stochastic gradient MCMC (SGMCMC) is a popular method for scalable Bayesian inference for large independent data. Unfortunately when applied to dependent data, such as in SSMs, SGMCMC's stochastic gradient estimates are biased as they break crucial temporal dependencies. To alleviate this, we propose stochastic gradient estimators that control this bias by performing additional computation in a `buffer' to reduce breaking dependencies. Furthermore, we derive error bounds for this bias and show a geometric decay under mild conditions. Using these estimators, we develop novel SGMCMC samplers for discrete, continuous and mixed-type SSMs. Our experiments on real and synthetic data demonstrate the effectiveness of our SGMCMC algorithms compared to batch MCMC, allowing us to scale inference to long time series with millions of time points.
An Interpretable and Sparse Neural Network Model for Nonlinear Granger Causality Discovery
Jun 25, 2018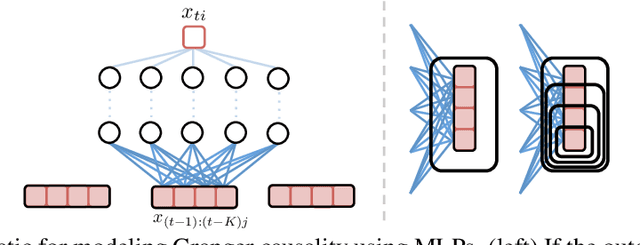
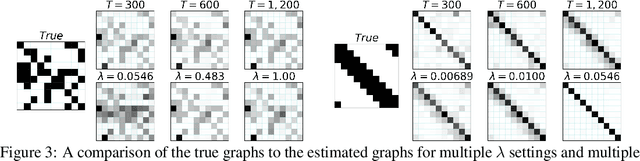
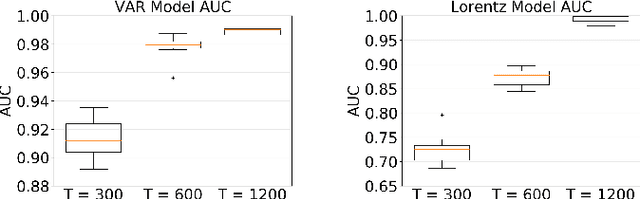
While most classical approaches to Granger causality detection repose upon linear time series assumptions, many interactions in neuroscience and economics applications are nonlinear. We develop an approach to nonlinear Granger causality detection using multilayer perceptrons where the input to the network is the past time lags of all series and the output is the future value of a single series. A sufficient condition for Granger non-causality in this setting is that all of the outgoing weights of the input data, the past lags of a series, to the first hidden layer are zero. For estimation, we utilize a group lasso penalty to shrink groups of input weights to zero. We also propose a hierarchical penalty for simultaneous Granger causality and lag estimation. We validate our approach on simulated data from both a sparse linear autoregressive model and the sparse and nonlinear Lorenz-96 model.
Disentangled VAE Representations for Multi-Aspect and Missing Data
Jun 24, 2018

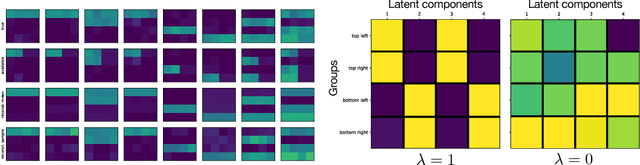
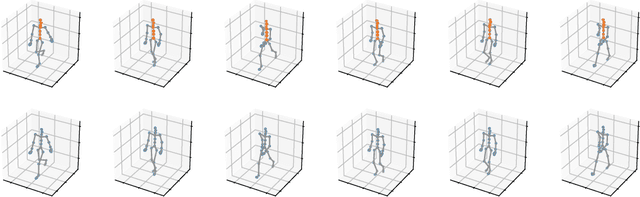
Many problems in machine learning and related application areas are fundamentally variants of conditional modeling and sampling across multi-aspect data, either multi-view, multi-modal, or simply multi-group. For example, sampling from the distribution of English sentences conditioned on a given French sentence or sampling audio waveforms conditioned on a given piece of text. Central to many of these problems is the issue of missing data: we can observe many English, French, or German sentences individually but only occasionally do we have data for a sentence pair. Motivated by these applications and inspired by recent progress in variational autoencoders for grouped data, we develop factVAE, a deep generative model capable of handling multi-aspect data, robust to missing observations, and with a prior that encourages disentanglement between the groups and the latent dimensions. The effectiveness of factVAE is demonstrated on a variety of rich real-world datasets, including motion capture poses and pictures of faces captured from varying poses and perspectives.
The Cultural Evolution of National Constitutions
Nov 18, 2017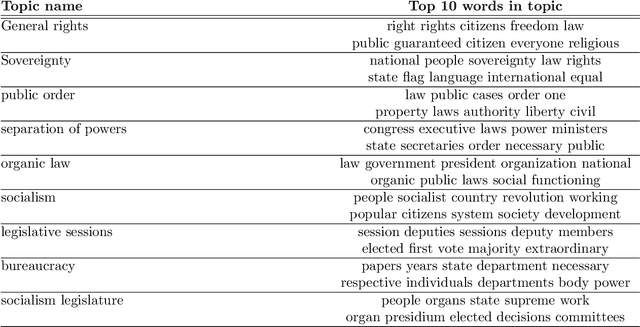
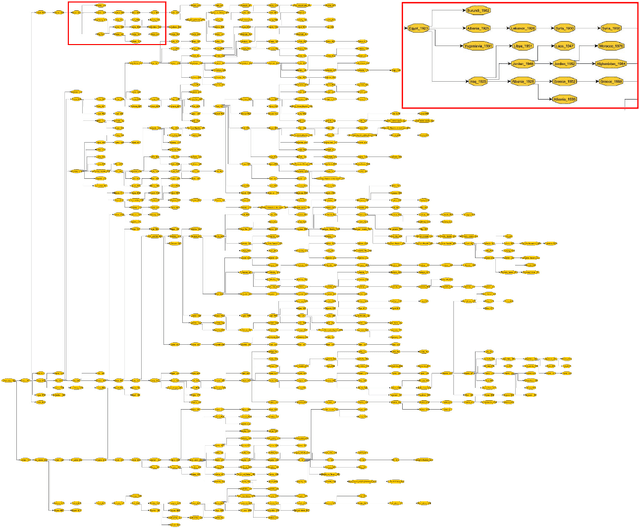
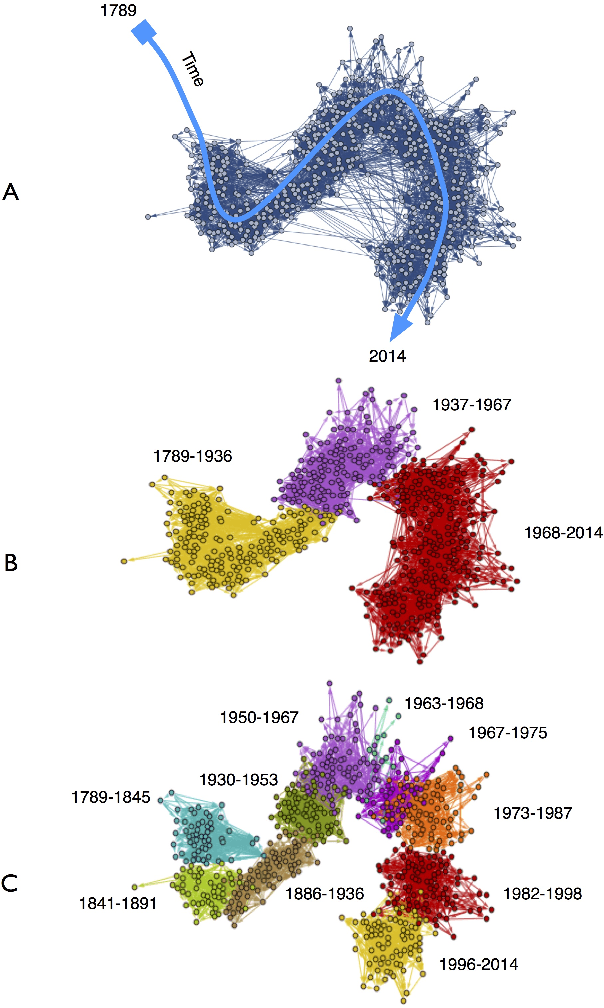
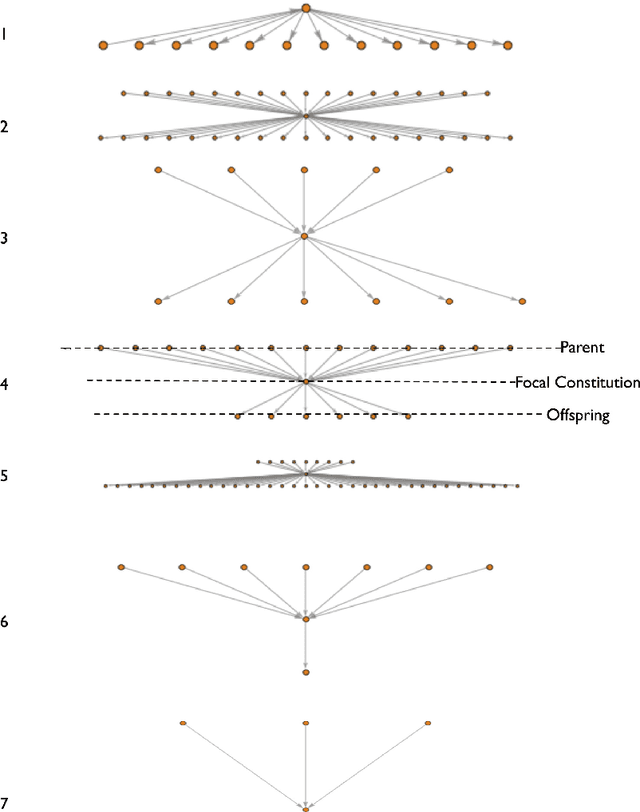
We explore how ideas from infectious disease and genetics can be used to uncover patterns of cultural inheritance and innovation in a corpus of 591 national constitutions spanning 1789 - 2008. Legal "Ideas" are encoded as "topics" - words statistically linked in documents - derived from topic modeling the corpus of constitutions. Using these topics we derive a diffusion network for borrowing from ancestral constitutions back to the US Constitution of 1789 and reveal that constitutions are complex cultural recombinants. We find systematic variation in patterns of borrowing from ancestral texts and "biological"-like behavior in patterns of inheritance with the distribution of "offspring" arising through a bounded preferential-attachment process. This process leads to a small number of highly innovative (influential) constitutions some of which have yet to have been identified as so in the current literature. Our findings thus shed new light on the critical nodes of the constitution-making network. The constitutional network structure reflects periods of intense constitution creation, and systematic patterns of variation in constitutional life-span and temporal influence.
Stochastic Gradient MCMC Methods for Hidden Markov Models
Jun 14, 2017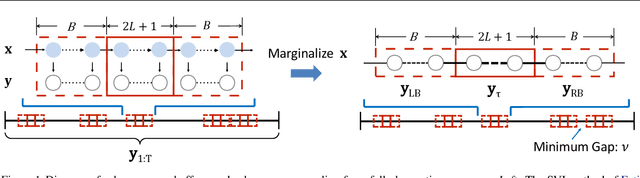
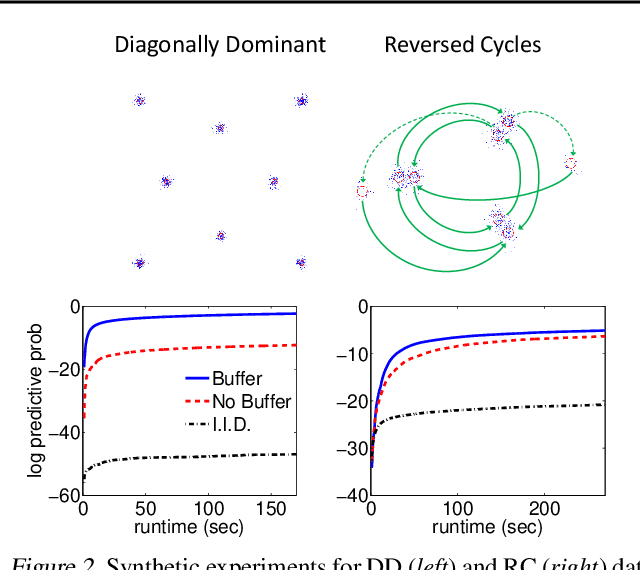
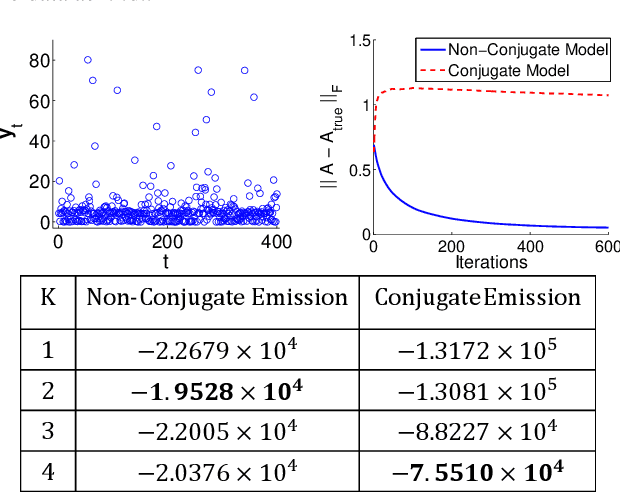
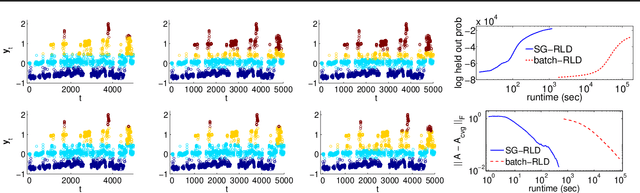
Stochastic gradient MCMC (SG-MCMC) algorithms have proven useful in scaling Bayesian inference to large datasets under an assumption of i.i.d data. We instead develop an SG-MCMC algorithm to learn the parameters of hidden Markov models (HMMs) for time-dependent data. There are two challenges to applying SG-MCMC in this setting: The latent discrete states, and needing to break dependencies when considering minibatches. We consider a marginal likelihood representation of the HMM and propose an algorithm that harnesses the inherent memory decay of the process. We demonstrate the effectiveness of our algorithm on synthetic experiments and an ion channel recording data, with runtimes significantly outperforming batch MCMC.
Reducing Reparameterization Gradient Variance
May 22, 2017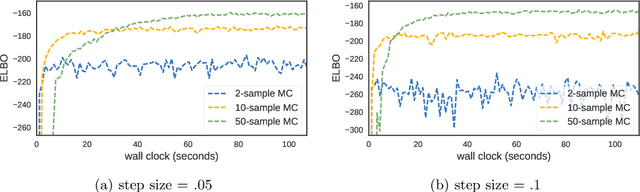
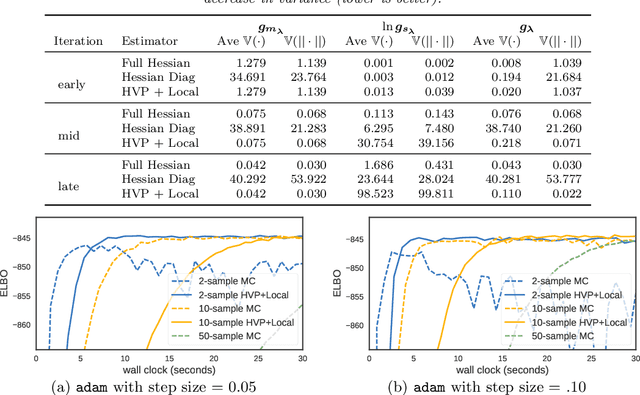

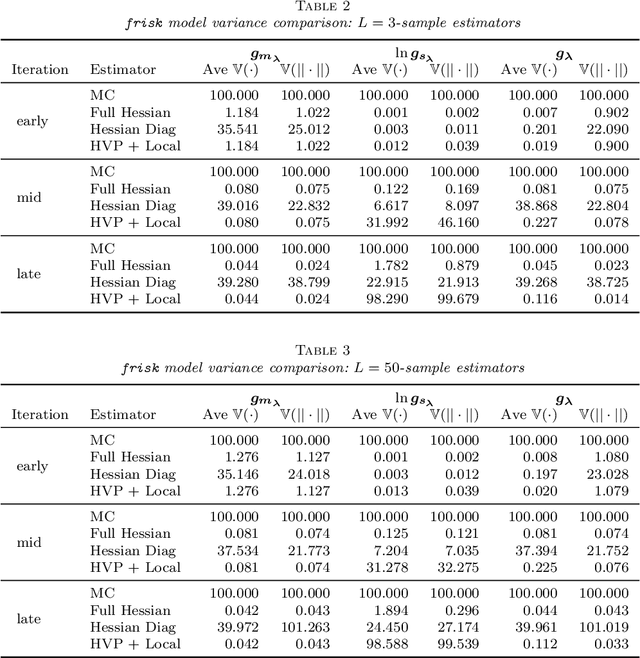
Optimization with noisy gradients has become ubiquitous in statistics and machine learning. Reparameterization gradients, or gradient estimates computed via the "reparameterization trick," represent a class of noisy gradients often used in Monte Carlo variational inference (MCVI). However, when these gradient estimators are too noisy, the optimization procedure can be slow or fail to converge. One way to reduce noise is to use more samples for the gradient estimate, but this can be computationally expensive. Instead, we view the noisy gradient as a random variable, and form an inexpensive approximation of the generating procedure for the gradient sample. This approximation has high correlation with the noisy gradient by construction, making it a useful control variate for variance reduction. We demonstrate our approach on non-conjugate multi-level hierarchical models and a Bayesian neural net where we observed gradient variance reductions of multiple orders of magnitude (20-2,000x).
Streaming Variational Inference for Bayesian Nonparametric Mixture Models
Apr 21, 2015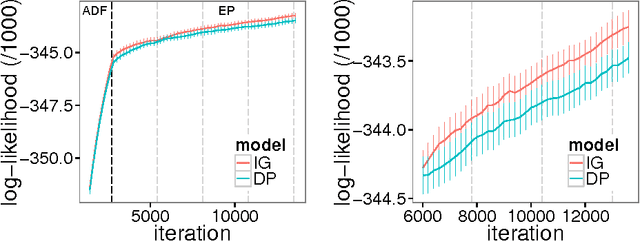
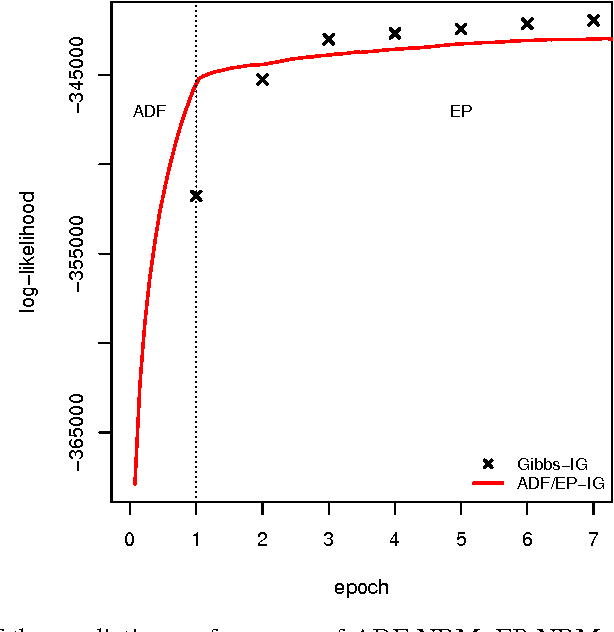
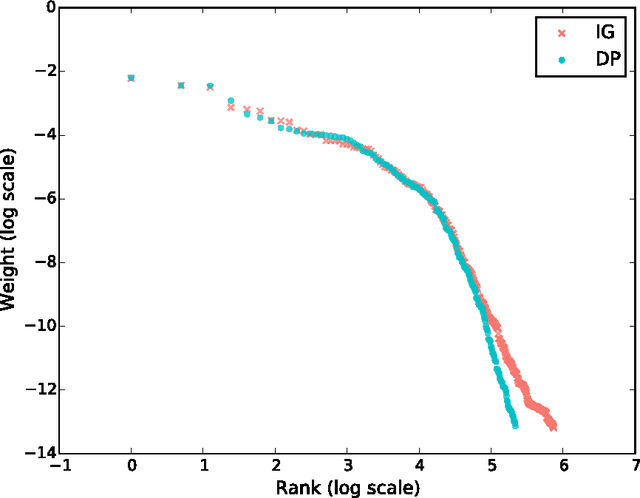
In theory, Bayesian nonparametric (BNP) models are well suited to streaming data scenarios due to their ability to adapt model complexity with the observed data. Unfortunately, such benefits have not been fully realized in practice; existing inference algorithms are either not applicable to streaming applications or not extensible to BNP models. For the special case of Dirichlet processes, streaming inference has been considered. However, there is growing interest in more flexible BNP models building on the class of normalized random measures (NRMs). We work within this general framework and present a streaming variational inference algorithm for NRM mixture models. Our algorithm is based on assumed density filtering (ADF), leading straightforwardly to expectation propagation (EP) for large-scale batch inference as well. We demonstrate the efficacy of the algorithm on clustering documents in large, streaming text corpora.