 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGit Re-Basin: Merging Models modulo Permutation Symmetries
Sep 11, 2022
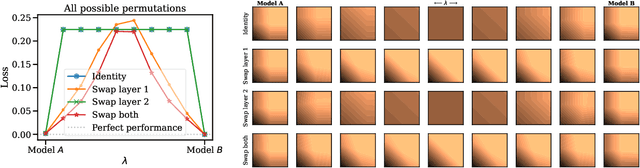

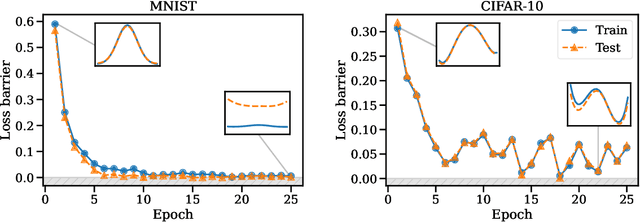
The success of deep learning is thanks to our ability to solve certain massive non-convex optimization problems with relative ease. Despite non-convex optimization being NP-hard, simple algorithms -- often variants of stochastic gradient descent -- exhibit surprising effectiveness in fitting large neural networks in practice. We argue that neural network loss landscapes contain (nearly) a single basin, after accounting for all possible permutation symmetries of hidden units. We introduce three algorithms to permute the units of one model to bring them into alignment with units of a reference model. This transformation produces a functionally equivalent set of weights that lie in an approximately convex basin near the reference model. Experimentally, we demonstrate the single basin phenomenon across a variety of model architectures and datasets, including the first (to our knowledge) demonstration of zero-barrier linear mode connectivity between independently trained ResNet models on CIFAR-10 and CIFAR-100. Additionally, we identify intriguing phenomena relating model width and training time to mode connectivity across a variety of models and datasets. Finally, we discuss shortcomings of a single basin theory, including a counterexample to the linear mode connectivity hypothesis.
Disentangled VAE Representations for Multi-Aspect and Missing Data
Jun 24, 2018

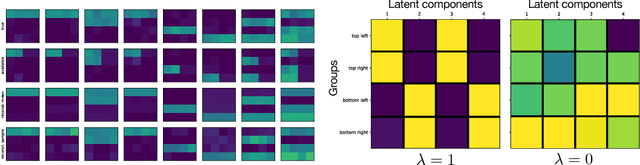
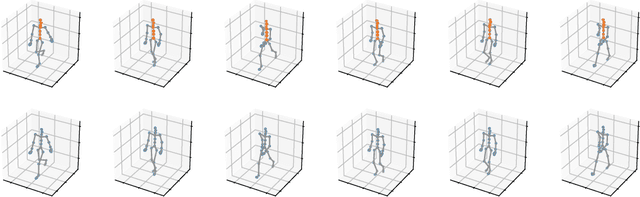
Many problems in machine learning and related application areas are fundamentally variants of conditional modeling and sampling across multi-aspect data, either multi-view, multi-modal, or simply multi-group. For example, sampling from the distribution of English sentences conditioned on a given French sentence or sampling audio waveforms conditioned on a given piece of text. Central to many of these problems is the issue of missing data: we can observe many English, French, or German sentences individually but only occasionally do we have data for a sentence pair. Motivated by these applications and inspired by recent progress in variational autoencoders for grouped data, we develop factVAE, a deep generative model capable of handling multi-aspect data, robust to missing observations, and with a prior that encourages disentanglement between the groups and the latent dimensions. The effectiveness of factVAE is demonstrated on a variety of rich real-world datasets, including motion capture poses and pictures of faces captured from varying poses and perspectives.