 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotations Mitigate Post-Training Mode Collapse
May 11, 2026Post-training (via supervised fine-tuning) improves instruction-following, but often induces semantic mode collapse by biasing models toward low-entropy fine-tuning data at the expense of the high-entropy pretraining distribution. Crucially, we find this trade-off worsens with scale. To close this semantic diversity gap, we propose annotation-anchored training, a principled method that enables models to adopt the preference-following behaviors of post-training without sacrificing the inherent diversity of pretraining. Our approach is simple: we pretrain on documents paired with semantic annotations, inducing a rich annotation distribution that reflects the full breadth of pretraining data, and we preserve this distribution during post-training. This lets us sample diverse annotations at inference time and use them as anchors to guide generation, effectively transferring pretraining's semantic richness into post-trained models. We find that models trained with annotation-anchored training can attain $6 \times$ less diversity collapse than models trained with SFT, and improve with scale.
Uncertainty Quantification for LLM Function-Calling
Apr 24, 2026Large Language Models (LLMs) are increasingly deployed to autonomously solve real-world tasks. A key ingredient for this is the LLM Function-Calling paradigm, a widely used approach for equipping LLMs with tool-use capabilities. However, an LLM calling functions incorrectly can have severe implications, especially when their effects are irreversible, e.g., transferring money or deleting data. Hence, it is of paramount importance to consider the LLM's confidence that a function call solves the task correctly prior to executing it. Uncertainty Quantification (UQ) methods can be used to quantify this confidence and prevent potentially incorrect function calls. In this work, we present what is, to our knowledge, the first evaluation of UQ methods for LLM Function-Calling (FC). While multi-sample UQ methods, such as Semantic Entropy, show strong performance for natural language Q&A tasks, we find that in the FC setting, it offers no clear advantage over simple single-sample UQ methods. Additionally, we find that the particularities of FC outputs can be leveraged to improve the performance of existing UQ methods in this setting. Specifically, multi-sample UQ methods benefit from clustering FC outputs based on their abstract syntax tree parsing, while single-sample UQ methods can be improved by selecting only semantically meaningful tokens when calculating logit-based uncertainty scores.
What do your logits know? (The answer may surprise you!)
Apr 10, 2026Recent work has shown that probing model internals can reveal a wealth of information not apparent from the model generations. This poses the risk of unintentional or malicious information leakage, where model users are able to learn information that the model owner assumed was inaccessible. Using vision-language models as a testbed, we present the first systematic comparison of information retained at different "representational levels'' as it is compressed from the rich information encoded in the residual stream through two natural bottlenecks: low-dimensional projections of the residual stream obtained using tuned lens, and the final top-k logits most likely to impact model's answer. We show that even easily accessible bottlenecks defined by the model's top logit values can leak task-irrelevant information present in an image-based query, in some cases revealing as much information as direct projections of the full residual stream.
Self-Supervised Learning with Gaussian Processes
Dec 10, 2025Self supervised learning (SSL) is a machine learning paradigm where models learn to understand the underlying structure of data without explicit supervision from labeled samples. The acquired representations from SSL have demonstrated useful for many downstream tasks including clustering, and linear classification, etc. To ensure smoothness of the representation space, most SSL methods rely on the ability to generate pairs of observations that are similar to a given instance. However, generating these pairs may be challenging for many types of data. Moreover, these methods lack consideration of uncertainty quantification and can perform poorly in out-of-sample prediction settings. To address these limitations, we propose Gaussian process self supervised learning (GPSSL), a novel approach that utilizes Gaussian processes (GP) models on representation learning. GP priors are imposed on the representations, and we obtain a generalized Bayesian posterior minimizing a loss function that encourages informative representations. The covariance function inherent in GPs naturally pulls representations of similar units together, serving as an alternative to using explicitly defined positive samples. We show that GPSSL is closely related to both kernel PCA and VICReg, a popular neural network-based SSL method, but unlike both allows for posterior uncertainties that can be propagated to downstream tasks. Experiments on various datasets, considering classification and regression tasks, demonstrate that GPSSL outperforms traditional methods in terms of accuracy, uncertainty quantification, and error control.
Trained on Tokens, Calibrated on Concepts: The Emergence of Semantic Calibration in LLMs
Nov 06, 2025Large Language Models (LLMs) often lack meaningful confidence estimates for their outputs. While base LLMs are known to exhibit next-token calibration, it remains unclear whether they can assess confidence in the actual meaning of their responses beyond the token level. We find that, when using a certain sampling-based notion of semantic calibration, base LLMs are remarkably well-calibrated: they can meaningfully assess confidence in open-domain question-answering tasks, despite not being explicitly trained to do so. Our main theoretical contribution establishes a mechanism for why semantic calibration emerges as a byproduct of next-token prediction, leveraging a recent connection between calibration and local loss optimality. The theory relies on a general definition of "B-calibration," which is a notion of calibration parameterized by a choice of equivalence classes (semantic or otherwise). This theoretical mechanism leads to a testable prediction: base LLMs will be semantically calibrated when they can easily predict their own distribution over semantic answer classes before generating a response. We state three implications of this prediction, which we validate through experiments: (1) Base LLMs are semantically calibrated across question-answering tasks, (2) RL instruction-tuning systematically breaks this calibration, and (3) chain-of-thought reasoning breaks calibration. To our knowledge, our work provides the first principled explanation of when and why semantic calibration emerges in LLMs.
BED-LLM: Intelligent Information Gathering with LLMs and Bayesian Experimental Design
Aug 28, 2025We propose a general-purpose approach for improving the ability of Large Language Models (LLMs) to intelligently and adaptively gather information from a user or other external source using the framework of sequential Bayesian experimental design (BED). This enables LLMs to act as effective multi-turn conversational agents and interactively interface with external environments. Our approach, which we call BED-LLM (Bayesian Experimental Design with Large Language Models), is based on iteratively choosing questions or queries that maximize the expected information gain (EIG) about the task of interest given the responses gathered previously. We show how this EIG can be formulated in a principled way using a probabilistic model derived from the LLM's belief distribution and provide detailed insights into key decisions in its construction. Further key to the success of BED-LLM are a number of specific innovations, such as a carefully designed estimator for the EIG, not solely relying on in-context updates for conditioning on previous responses, and a targeted strategy for proposing candidate queries. We find that BED-LLM achieves substantial gains in performance across a wide range of tests based on the 20-questions game and using the LLM to actively infer user preferences, compared to direct prompting of the LLM and other adaptive design strategies.
Self-reflective Uncertainties: Do LLMs Know Their Internal Answer Distribution?
May 26, 2025To reveal when a large language model (LLM) is uncertain about a response, uncertainty quantification commonly produces percentage numbers along with the output. But is this all we can do? We argue that in the output space of LLMs, the space of strings, exist strings expressive enough to summarize the distribution over output strings the LLM deems possible. We lay a foundation for this new avenue of uncertainty explication and present SelfReflect, a theoretically-motivated metric to assess how faithfully a string summarizes an LLM's internal answer distribution. We show that SelfReflect is able to discriminate even subtle differences of candidate summary strings and that it aligns with human judgement, outperforming alternative metrics such as LLM judges and embedding comparisons. With SelfReflect, we investigate a number of self-summarization methods and find that even state-of-the-art reasoning models struggle to explicate their internal uncertainty. But we find that faithful summarizations can be generated by sampling and summarizing. Our metric enables future works towards this universal form of LLM uncertainties.
Revisiting Uncertainty Quantification Evaluation in Language Models: Spurious Interactions with Response Length Bias Results
Apr 18, 2025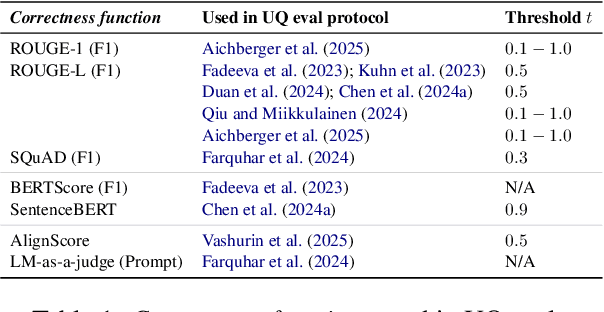
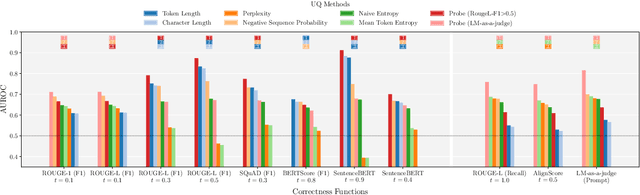
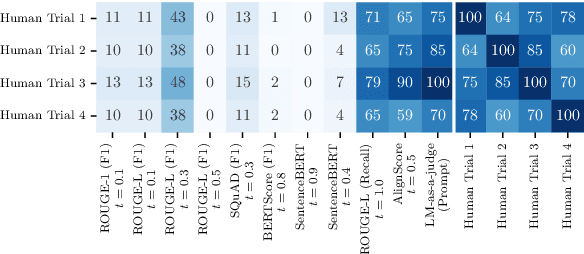
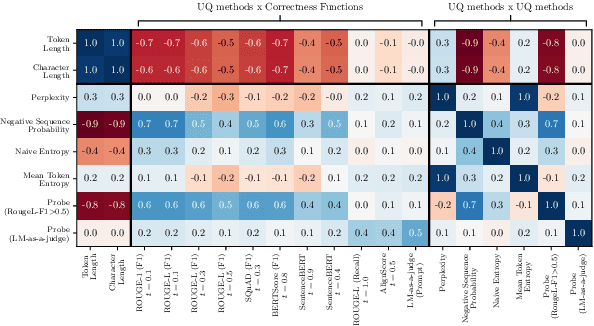
Uncertainty Quantification (UQ) in Language Models (LMs) is crucial for improving their safety and reliability. Evaluations often use performance metrics like AUROC to assess how well UQ methods (e.g., negative sequence probabilities) correlate with task correctness functions (e.g., ROUGE-L). In this paper, we show that commonly used correctness functions bias UQ evaluations by inflating the performance of certain UQ methods. We evaluate 7 correctness functions -- from lexical-based and embedding-based metrics to LLM-as-a-judge approaches -- across 4 datasets x 4 models x 6 UQ methods. Our analysis reveals that length biases in the errors of these correctness functions distort UQ assessments by interacting with length biases in UQ methods. We identify LLM-as-a-judge approaches as among the least length-biased choices and hence a potential solution to mitigate these biases.
Steering into New Embedding Spaces: Analyzing Cross-Lingual Alignment Induced by Model Interventions in Multilingual Language Models
Feb 21, 2025Aligned representations across languages is a desired property in multilingual large language models (mLLMs), as alignment can improve performance in cross-lingual tasks. Typically alignment requires fine-tuning a model, which is computationally expensive, and sizable language data, which often may not be available. A data-efficient alternative to fine-tuning is model interventions -- a method for manipulating model activations to steer generation into the desired direction. We analyze the effect of a popular intervention (finding experts) on the alignment of cross-lingual representations in mLLMs. We identify the neurons to manipulate for a given language and introspect the embedding space of mLLMs pre- and post-manipulation. We show that modifying the mLLM's activations changes its embedding space such that cross-lingual alignment is enhanced. Further, we show that the changes to the embedding space translate into improved downstream performance on retrieval tasks, with up to 2x improvements in top-1 accuracy on cross-lingual retrieval.
Analyze the Neurons, not the Embeddings: Understanding When and Where LLM Representations Align with Humans
Feb 20, 2025Modern large language models (LLMs) achieve impressive performance on some tasks, while exhibiting distinctly non-human-like behaviors on others. This raises the question of how well the LLM's learned representations align with human representations. In this work, we introduce a novel approach to the study of representation alignment: we adopt a method from research on activation steering to identify neurons responsible for specific concepts (e.g., 'cat') and then analyze the corresponding activation patterns. Our findings reveal that LLM representations closely align with human representations inferred from behavioral data. Notably, this alignment surpasses that of word embeddings, which have been center stage in prior work on human and model alignment. Additionally, our approach enables a more granular view of how LLMs represent concepts. Specifically, we show that LLMs organize concepts in a way that reflects hierarchical relationships interpretable to humans (e.g., 'animal'-'dog').