 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFASTER-CE: Fast, Sparse, Transparent, and Robust Counterfactual Explanations
Oct 12, 2022
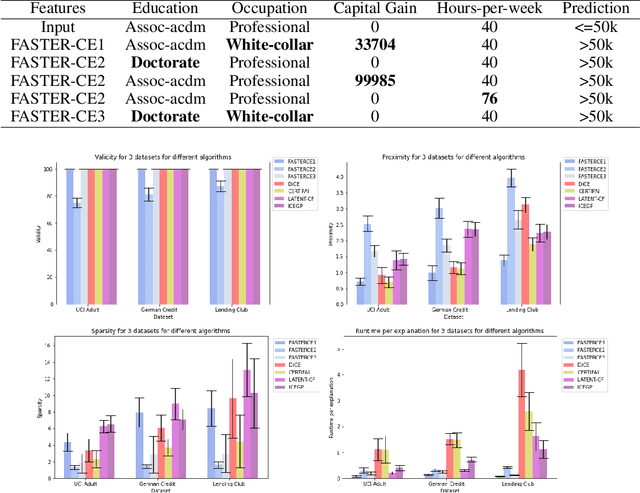


Counterfactual explanations have substantially increased in popularity in the past few years as a useful human-centric way of understanding individual black-box model predictions. While several properties desired of high-quality counterfactuals have been identified in the literature, three crucial concerns: the speed of explanation generation, robustness/sensitivity and succinctness of explanations (sparsity) have been relatively unexplored. In this paper, we present FASTER-CE: a novel set of algorithms to generate fast, sparse, and robust counterfactual explanations. The key idea is to efficiently find promising search directions for counterfactuals in a latent space that is specified via an autoencoder. These directions are determined based on gradients with respect to each of the original input features as well as of the target, as estimated in the latent space. The ability to quickly examine combinations of the most promising gradient directions as well as to incorporate additional user-defined constraints allows us to generate multiple counterfactual explanations that are sparse, realistic, and robust to input manipulations. Through experiments on three datasets of varied complexities, we show that FASTER-CE is not only much faster than other state of the art methods for generating multiple explanations but also is significantly superior when considering a larger set of desirable (and often conflicting) properties. Specifically we present results across multiple performance metrics: sparsity, proximity, validity, speed of generation, and the robustness of explanations, to highlight the capabilities of the FASTER-CE family.
FEAMOE: Fair, Explainable and Adaptive Mixture of Experts
Oct 10, 2022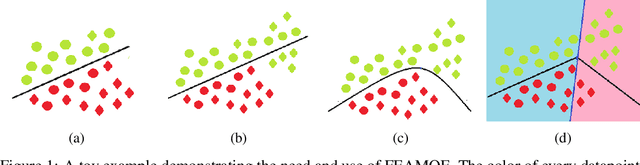


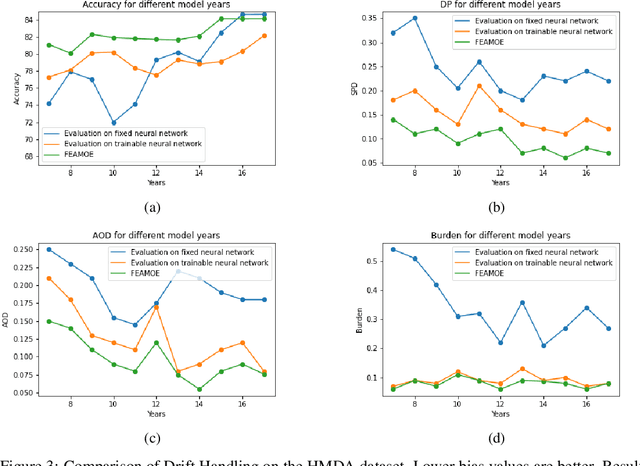
Three key properties that are desired of trustworthy machine learning models deployed in high-stakes environments are fairness, explainability, and an ability to account for various kinds of "drift". While drifts in model accuracy, for example due to covariate shift, have been widely investigated, drifts in fairness metrics over time remain largely unexplored. In this paper, we propose FEAMOE, a novel "mixture-of-experts" inspired framework aimed at learning fairer, more explainable/interpretable models that can also rapidly adjust to drifts in both the accuracy and the fairness of a classifier. We illustrate our framework for three popular fairness measures and demonstrate how drift can be handled with respect to these fairness constraints. Experiments on multiple datasets show that our framework as applied to a mixture of linear experts is able to perform comparably to neural networks in terms of accuracy while producing fairer models. We then use the large-scale HMDA dataset and show that while various models trained on HMDA demonstrate drift with respect to both accuracy and fairness, FEAMOE can ably handle these drifts with respect to all the considered fairness measures and maintain model accuracy as well. We also prove that the proposed framework allows for producing fast Shapley value explanations, which makes computationally efficient feature attribution based explanations of model decisions readily available via FEAMOE.
Federating Recommendations Using Differentially Private Prototypes
Mar 01, 2020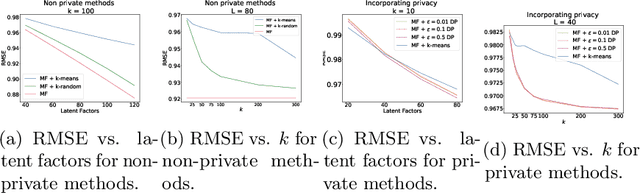
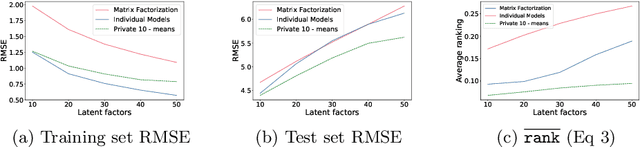
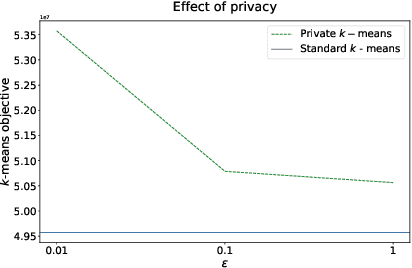
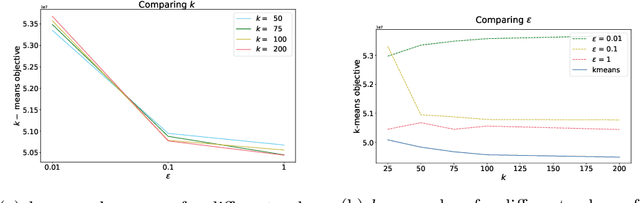
Machine learning methods allow us to make recommendations to users in applications across fields including entertainment, dating, and commerce, by exploiting similarities in users' interaction patterns. However, in domains that demand protection of personally sensitive data, such as medicine or banking, how can we learn such a model without accessing the sensitive data, and without inadvertently leaking private information? We propose a new federated approach to learning global and local private models for recommendation without collecting raw data, user statistics, or information about personal preferences. Our method produces a set of prototypes that allows us to infer global behavioral patterns, while providing differential privacy guarantees for users in any database of the system. By requiring only two rounds of communication, we both reduce the communication costs and avoid the excessive privacy loss associated with iterative procedures. We test our framework on synthetic data as well as real federated medical data and Movielens ratings data. We show local adaptation of the global model allows our method to outperform centralized matrix-factorization-based recommender system models, both in terms of accuracy of matrix reconstruction and in terms of relevance of the recommendations, while maintaining provable privacy guarantees. We also show that our method is more robust and is characterized by smaller variance than individual models learned by independent entities.
CERTIFAI: Counterfactual Explanations for Robustness, Transparency, Interpretability, and Fairness of Artificial Intelligence models
May 20, 2019


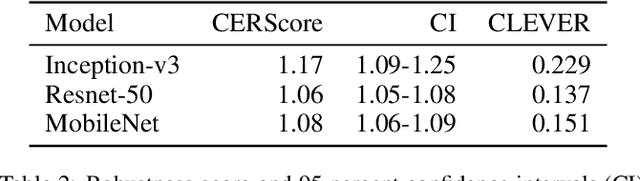
As artificial intelligence plays an increasingly important role in our society, there are ethical and moral obligations for both businesses and researchers to ensure that their machine learning models are designed, deployed, and maintained responsibly. These models need to be rigorously audited for fairness, robustness, transparency, and interpretability. A variety of methods have been developed that focus on these issues in isolation, however, managing these methods in conjunction with model development can be cumbersome and timeconsuming. In this paper, we introduce a unified and model-agnostic approach to address these issues: Counterfactual Explanations for Robustness, Transparency, Interpretability, and Fairness of Artificial Intelligence models (CERTIFAI). Unlike previous methods in this domain, CERTIFAI is a general tool that can be applied to any black-box model and any type of input data. Given a model and an input instance, CERTIFAI uses a custom genetic algorithm to generate counterfactuals: instances close to the input that change the prediction of the model. We demonstrate how these counterfactuals can be used to examine issues of robustness, interpretability, transparency, and fairness. Additionally, we introduce CERScore, the first black-box model robustness score that performs comparably to methods that have access to model internals.
PIVETed-Granite: Computational Phenotypes through Constrained Tensor Factorization
Aug 08, 2018

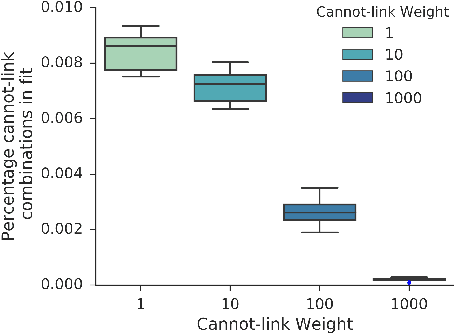

It has been recently shown that sparse, nonnegative tensor factorization of multi-modal electronic health record data is a promising approach to high-throughput computational phenotyping. However, such approaches typically do not leverage available domain knowledge while extracting the phenotypes; hence, some of the suggested phenotypes may not map well to clinical concepts or may be very similar to other suggested phenotypes. To address these issues, we present a novel, automatic approach called PIVETed-Granite that mines existing biomedical literature (PubMed) to obtain cannot-link constraints that are then used as side-information during a tensor-factorization based computational phenotyping process. The resulting improvements are clearly observed in experiments using a large dataset from VUMC to identify phenotypes for hypertensive patients.