 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMILM: Large Language Models for Multimodal Irregular Time Series with Informative Sampling
May 13, 2026Multimodal irregular time series (MITS) consist of asynchronous and irregularly sampled observations from heterogeneous numerical and textual channels. In healthcare, for example, patients' electronic health records (EHR) include irregular lab measurements and clinical notes. The irregular timing and channel patterns of observations carry predictive signal alongside the numerical values and textual content. LLMs are natural candidates for processing such heterogeneous data, given their extensive pretrained knowledge spanning textual and numerical domains. We introduce MILM (Multimodal Irregular time series Language Model), which represents MITS as time-ordered triplets in Extensible Markup Language (XML) format and fine-tunes an LLM through a two-stage strategy for MITS classification. The first stage trains on value-redacted MITS to predict from sampling patterns alone, and the second stage trains on full MITS to jointly model sampling patterns and observed values. Our two-stage model (MILM-2S) and its single-stage counterpart (MILM-Direct) achieve the best and second-best average performance on multiple EHR datasets. Further value redaction evaluations confirm that sampling patterns carry predictive signal and that MILM-2S learns to exploit them. In the value pending evaluation we introduce, where some values are unavailable at prediction time, MILM-2S outperforms MILM-Direct by a larger margin compared to standard evaluation. For MILM-2S, preserving the time and channel of value-pending observations as additional sampling information further improves in-hospital mortality prediction.
A Multi-Stage Large Language Model Framework for Extracting Suicide-Related Social Determinants of Health
Aug 07, 2025Background: Understanding social determinants of health (SDoH) factors contributing to suicide incidents is crucial for early intervention and prevention. However, data-driven approaches to this goal face challenges such as long-tailed factor distributions, analyzing pivotal stressors preceding suicide incidents, and limited model explainability. Methods: We present a multi-stage large language model framework to enhance SDoH factor extraction from unstructured text. Our approach was compared to other state-of-the-art language models (i.e., pre-trained BioBERT and GPT-3.5-turbo) and reasoning models (i.e., DeepSeek-R1). We also evaluated how the model's explanations help people annotate SDoH factors more quickly and accurately. The analysis included both automated comparisons and a pilot user study. Results: We show that our proposed framework demonstrated performance boosts in the overarching task of extracting SDoH factors and in the finer-grained tasks of retrieving relevant context. Additionally, we show that fine-tuning a smaller, task-specific model achieves comparable or better performance with reduced inference costs. The multi-stage design not only enhances extraction but also provides intermediate explanations, improving model explainability. Conclusions: Our approach improves both the accuracy and transparency of extracting suicide-related SDoH from unstructured texts. These advancements have the potential to support early identification of individuals at risk and inform more effective prevention strategies.
OMAC: A Broad Optimization Framework for LLM-Based Multi-Agent Collaboration
May 17, 2025Agents powered by advanced large language models (LLMs) have demonstrated impressive capabilities across diverse complex applications. Recently, Multi-Agent Systems (MAS), wherein multiple agents collaborate and communicate with each other, have exhibited enhanced capabilities in complex tasks, such as high-quality code generation and arithmetic reasoning. However, the development of such systems often relies on handcrafted methods, and the literature on systematic design and optimization of LLM-based MAS remains limited. In this work, we introduce OMAC, a general framework designed for holistic optimization of LLM-based MAS. Specifically, we identify five key optimization dimensions for MAS, encompassing both agent functionality and collaboration structure. Building upon these dimensions, we first propose a general algorithm, utilizing two actors termed the Semantic Initializer and the Contrastive Comparator, to optimize any single dimension. Then, we present an algorithm for joint optimization across multiple dimensions. Extensive experiments demonstrate the superior performance of OMAC on code generation, arithmetic reasoning, and general reasoning tasks against state-of-the-art approaches.
Between Linear and Sinusoidal: Rethinking the Time Encoder in Dynamic Graph Learning
Apr 10, 2025
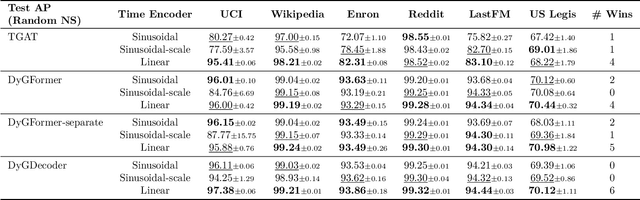


Dynamic graph learning is essential for applications involving temporal networks and requires effective modeling of temporal relationships. Seminal attention-based models like TGAT and DyGFormer rely on sinusoidal time encoders to capture temporal relationships between edge events. In this paper, we study a simpler alternative: the linear time encoder, which avoids temporal information loss caused by sinusoidal functions and reduces the need for high dimensional time encoders. We show that the self-attention mechanism can effectively learn to compute time spans from linear time encodings and extract relevant temporal patterns. Through extensive experiments on six dynamic graph datasets, we demonstrate that the linear time encoder improves the performance of TGAT and DyGFormer in most cases. Moreover, the linear time encoder can lead to significant savings in model parameters with minimal performance loss. For example, compared to a 100-dimensional sinusoidal time encoder, TGAT with a 2-dimensional linear time encoder saves 43% of parameters and achieves higher average precision on five datasets. These results can be readily used to positively impact the design choices of a wide variety of dynamic graph learning architectures. The experimental code is available at: https://github.com/hsinghuan/dg-linear-time.git.
Goal-Conditioned Supervised Learning for Multi-Objective Recommendation
Dec 12, 2024Multi-objective learning endeavors to concurrently optimize multiple objectives using a single model, aiming to achieve high and balanced performance across these diverse objectives. However, it often involves a more complex optimization problem, particularly when navigating potential conflicts between objectives, leading to solutions with higher memory requirements and computational complexity. This paper introduces a Multi-Objective Goal-Conditioned Supervised Learning (MOGCSL) framework for automatically learning to achieve multiple objectives from offline sequential data. MOGCSL extends the conventional Goal-Conditioned Supervised Learning (GCSL) method to multi-objective scenarios by redefining goals from one-dimensional scalars to multi-dimensional vectors. The need for complex architectures and optimization constraints can be naturally eliminated. MOGCSL benefits from filtering out uninformative or noisy instances that do not achieve desirable long-term rewards. It also incorporates a novel goal-choosing algorithm to model and select "high" achievable goals for inference. While MOGCSL is quite general, we focus on its application to the next action prediction problem in commercial-grade recommender systems. In this context, any viable solution needs to be reasonably scalable and also be robust to large amounts of noisy data that is characteristic of this application space. We show that MOGCSL performs admirably on both counts. Specifically, extensive experiments conducted on real-world recommendation datasets validate its efficacy and efficiency. Also, analysis and experiments are included to explain its strength in discounting the noisier portions of training data in recommender systems.
Achieving Fairness Across Local and Global Models in Federated Learning
Jun 24, 2024Achieving fairness across diverse clients in Federated Learning (FL) remains a significant challenge due to the heterogeneity of the data and the inaccessibility of sensitive attributes from clients' private datasets. This study addresses this issue by introducing \texttt{EquiFL}, a novel approach designed to enhance both local and global fairness in federated learning environments. \texttt{EquiFL} incorporates a fairness term into the local optimization objective, effectively balancing local performance and fairness. The proposed coordination mechanism also prevents bias from propagating across clients during the collaboration phase. Through extensive experiments across multiple benchmarks, we demonstrate that \texttt{EquiFL} not only strikes a better balance between accuracy and fairness locally at each client but also achieves global fairness. The results also indicate that \texttt{EquiFL} ensures uniform performance distribution among clients, thus contributing to performance fairness. Furthermore, we showcase the benefits of \texttt{EquiFL} in a real-world distributed dataset from a healthcare application, specifically in predicting the effects of treatments on patients across various hospital locations.
SVFT: Parameter-Efficient Fine-Tuning with Singular Vectors
May 30, 2024



Popular parameter-efficient fine-tuning (PEFT) methods, such as LoRA and its variants, freeze pre-trained model weights \(W\) and inject learnable matrices \(\Delta W\). These \(\Delta W\) matrices are structured for efficient parameterization, often using techniques like low-rank approximations or scaling vectors. However, these methods typically show a performance gap compared to full fine-tuning. Although recent PEFT methods have narrowed this gap, they do so at the cost of additional learnable parameters. We propose SVFT, a simple approach that fundamentally differs from existing methods: the structure imposed on \(\Delta W\) depends on the specific weight matrix \(W\). Specifically, SVFT updates \(W\) as a sparse combination of outer products of its singular vectors, training only the coefficients (scales) of these sparse combinations. This approach allows fine-grained control over expressivity through the number of coefficients. Extensive experiments on language and vision benchmarks show that SVFT recovers up to 96% of full fine-tuning performance while training only 0.006 to 0.25% of parameters, outperforming existing methods that only recover up to 85% performance using 0.03 to 0.8% of the trainable parameter budget.
Exploring Explainability in Video Action Recognition
Apr 13, 2024



Image Classification and Video Action Recognition are perhaps the two most foundational tasks in computer vision. Consequently, explaining the inner workings of trained deep neural networks is of prime importance. While numerous efforts focus on explaining the decisions of trained deep neural networks in image classification, exploration in the domain of its temporal version, video action recognition, has been scant. In this work, we take a deeper look at this problem. We begin by revisiting Grad-CAM, one of the popular feature attribution methods for Image Classification, and its extension to Video Action Recognition tasks and examine the method's limitations. To address these, we introduce Video-TCAV, by building on TCAV for Image Classification tasks, which aims to quantify the importance of specific concepts in the decision-making process of Video Action Recognition models. As the scalable generation of concepts is still an open problem, we propose a machine-assisted approach to generate spatial and spatiotemporal concepts relevant to Video Action Recognition for testing Video-TCAV. We then establish the importance of temporally-varying concepts by demonstrating the superiority of dynamic spatiotemporal concepts over trivial spatial concepts. In conclusion, we introduce a framework for investigating hypotheses in action recognition and quantitatively testing them, thus advancing research in the explainability of deep neural networks used in video action recognition.
Novel Node Category Detection Under Subpopulation Shift
Apr 01, 2024



In real-world graph data, distribution shifts can manifest in various ways, such as the emergence of new categories and changes in the relative proportions of existing categories. It is often important to detect nodes of novel categories under such distribution shifts for safety or insight discovery purposes. We introduce a new approach, Recall-Constrained Optimization with Selective Link Prediction (RECO-SLIP), to detect nodes belonging to novel categories in attributed graphs under subpopulation shifts. By integrating a recall-constrained learning framework with a sample-efficient link prediction mechanism, RECO-SLIP addresses the dual challenges of resilience against subpopulation shifts and the effective exploitation of graph structure. Our extensive empirical evaluation across multiple graph datasets demonstrates the superior performance of RECO-SLIP over existing methods.
Uncovering Misattributed Suicide Causes through Annotation Inconsistency Detection in Death Investigation Notes
Mar 29, 2024



Data accuracy is essential for scientific research and policy development. The National Violent Death Reporting System (NVDRS) data is widely used for discovering the patterns and causes of death. Recent studies suggested the annotation inconsistencies within the NVDRS and the potential impact on erroneous suicide-cause attributions. We present an empirical Natural Language Processing (NLP) approach to detect annotation inconsistencies and adopt a cross-validation-like paradigm to identify problematic instances. We analyzed 267,804 suicide death incidents between 2003 and 2020 from the NVDRS. Our results showed that incorporating the target state's data into training the suicide-crisis classifier brought an increase of 5.4% to the F-1 score on the target state's test set and a decrease of 1.1% on other states' test set. To conclude, we demonstrated the annotation inconsistencies in NVDRS's death investigation notes, identified problematic instances, evaluated the effectiveness of correcting problematic instances, and eventually proposed an NLP improvement solution.